
Funcionalidad de regresión de árbol de decisión, términos, implementación [con ejemplo]
Publicado: 2020-12-24Para empezar, un modelo de regresión es un modelo que da como salida un valor numérico cuando se le dan algunos valores de entrada que también son numéricos. Esto difiere de lo que hace un modelo de clasificación. Clasifica los datos de prueba en varias clases o grupos involucrados en un enunciado de problema dado.
El tamaño del grupo puede ser tan pequeño como 2 y tan grande como 1000 o más. Existen múltiples modelos de regresión como la regresión lineal, la regresión multivariada, la regresión de Ridge, la regresión logística y muchos más. Los modelos de regresión de árboles de decisión también pertenecen a este conjunto de modelos de regresión.
El modelo predictivo clasificará o predecirá un valor numérico que utiliza reglas binarias para determinar el valor de salida o de destino. El modelo de árbol de decisión, como sugiere su nombre, es un modelo similar a un árbol que tiene hojas, ramas y nodos.
Aprenda el curso en línea de aprendizaje automático de las mejores universidades del mundo. Obtenga programas de maestría, PGP ejecutivo o certificado avanzado para acelerar su carrera.
Leer: Ideas de proyectos de aprendizaje automático
Tabla de contenido
Terminologías para recordar
Antes de profundizar en el algoritmo, aquí hay algunas terminologías importantes que todos deben conocer.

- Nodo raíz: Es el nodo superior desde donde comienza la división.
- División: Proceso de subdividir un solo nodo en múltiples subnodos.
- Nodo terminal o nodo hoja: los nodos que no se dividen más se denominan nodos terminales.
- Poda: El proceso de eliminación de subnodos.
- Nodo principal: el nodo que se divide aún más en subnodos.
- Nodo secundario: los subnodos que han surgido del nodo principal.
¿Como funciona?
El árbol de decisión desglosa el conjunto de datos en subconjuntos más pequeños. Una hoja de decisión se divide en dos o más ramas que representan el valor del atributo bajo examen. El nodo superior en el árbol de decisión es el mejor predictor llamado nodo raíz. ID3 es el algoritmo que construye el árbol de decisión.
Emplea un enfoque de arriba hacia abajo y las divisiones se realizan en función de la desviación estándar. Solo para una revisión rápida, la desviación estándar es el grado de distribución o dispersión de un conjunto de puntos de datos de su valor medio. Cuantifica la variabilidad global de la distribución de datos.
Un valor más alto de dispersión o variabilidad significa que mayor es la desviación estándar que indica la mayor dispersión de los puntos de datos del valor medio. Usamos la desviación estándar para medir la uniformidad de la muestra. Si la muestra es totalmente homogénea, su desviación estándar es cero.
Y del mismo modo, cuanto mayor sea el grado de heterogeneidad, mayor será la desviación estándar. Se requiere la media de la muestra y el número de muestras para calcular la desviación estándar. Usamos una función matemática: el coeficiente de desviación que decide cuándo debe detenerse la división. Se calcula dividiendo la desviación estándar por la media de todas las muestras.
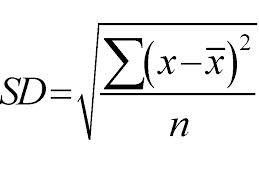
Fuente
El valor final sería el promedio de los nodos hoja. Digamos, por ejemplo, si el mes de noviembre es el nodo que se divide aún más en varios salarios a lo largo de los años en el mes de noviembre (hasta 2020). Para el año 2021, el salario del mes de noviembre sería el promedio de todos los salarios bajo el nodo noviembre.
Pasando a la desviación estándar de dos clases o atributos (como en el ejemplo anterior, el salario puede basarse en una base horaria o mensual). La fórmula quedaría de la siguiente manera:
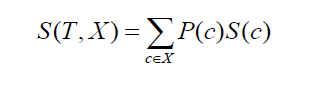
Fuente
donde P(c) es la probabilidad de ocurrencia del atributo c, S(c) es la desviación estándar correspondiente del atributo c. El método de reducción de la desviación estándar se basa en la disminución de la desviación estándar después de que se haya dividido un conjunto de datos.
Para construir un árbol de decisiones preciso, el objetivo debe ser encontrar atributos que devuelvan el cálculo y devuelvan la reducción de desviación estándar más alta. En palabras simples, las ramas más homogéneas.

El proceso de creación de un árbol de decisión para la regresión abarca cuatro pasos importantes.
1. En primer lugar, calculamos la desviación estándar de la variable objetivo. Considere que la variable objetivo es el salario como en los ejemplos anteriores. Con el ejemplo en su lugar, calcularemos la desviación estándar del conjunto de valores salariales.
2. En el paso 2, el conjunto de datos se divide aún más en diferentes atributos. Hablando de atributos, como el valor objetivo es el salario, podemos pensar en los posibles atributos como: meses, horas, estado de ánimo del jefe, designación, año en la empresa, etc. Luego, la desviación estándar para cada rama se calcula utilizando la fórmula anterior. la desviación estándar así obtenida se resta de la desviación estándar antes de la división. El resultado en cuestión se llama reducción de la desviación estándar.
3. Una vez que se ha calculado la diferencia como se mencionó en el paso anterior, el mejor atributo es aquel para el cual el valor de reducción de la desviación estándar es mayor. Eso significa que la desviación estándar antes de la división debe ser mayor que la desviación estándar antes de la división. En realidad, se toma la mod de la diferencia y también es posible viceversa.
4. Todo el conjunto de datos se clasifica según la importancia del atributo seleccionado. En las ramas que no son hojas, este método continúa recursivamente hasta que se procesan todos los datos disponibles. Ahora considere que el mes está seleccionado como el mejor atributo de división en función del valor de reducción de la desviación estándar. Entonces tendremos 12 sucursales para cada mes. Estas ramas se dividirán aún más para seleccionar el mejor atributo del conjunto restante de atributos.
5. En realidad, requerimos algunos criterios de acabado. Para esto, hacemos uso del coeficiente de desviación o CV para una rama que se vuelve más pequeña que un cierto umbral como el 10%. Cuando logramos este criterio detenemos el proceso de construcción del árbol. Debido a que no ocurre más división, el valor que cae bajo este atributo será el promedio de todos los valores bajo ese nodo.
Implementación
La regresión del árbol de decisiones se puede implementar utilizando el lenguaje Python y la biblioteca scikit-learn. Se puede encontrar en sklearn.tree.DecisionTreeRegressor.
Algunos de los parámetros importantes son los siguientes:
- criterio: Medir la calidad de un split. Su valor puede ser “mse” o el error cuadrático medio, “friedman_mse” y “mae” o el error absoluto medio. El valor predeterminado es mse.
- max_ depth: Representa la profundidad máxima del árbol. El valor predeterminado es Ninguno.
- max_features: Representa la cantidad de características a buscar al decidir la mejor división. El valor predeterminado es Ninguno.
- divisor: este parámetro se utiliza para elegir la división en cada nodo. Los valores disponibles son "mejor" y "aleatorio". El valor predeterminado es el mejor.
Consulte: Preguntas de la entrevista sobre aprendizaje automático
Ejemplo de la documentación de sklearn
>>> de sklearn.datasets import load_diabetes
>>> de sklearn.model_selection import cross_val_score
>>> desde sklearn.tree import DecisionTreeRegressor
>>> X, y = carga_diabetes(retorno_X_y= Verdadero )
>>> regresor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regresor, X, y, cv=10)
… # prueba de documento: + SALTAR
…
matriz([-0.39…, -0.46…, 0.02…, 0.06…, -0.50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
¿Qué sigue?
Además, si está interesado en obtener más información sobre el aprendizaje automático, consulte el programa Executive PG de IIIT-B y upGrad en aprendizaje automático e IA, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones. , estado de exalumno de IIIT-B, más de 5 proyectos prácticos finales y asistencia laboral con las mejores empresas.