
Modèle de classification utilisant des réseaux de neurones artificiels (ANN)
Publié: 2020-12-01Dans la terminologie de l'apprentissage automatique, la classification fait référence à un problème de modélisation prédictive dans lequel les données d'entrée sont classées dans l'une des classes étiquetées prédéfinies. Par exemple, prédire Oui ou Non, Vrai ou Faux tombe dans la catégorie de la classification binaire car le nombre de sorties est limité à deux étiquettes.
De même, les sorties ayant plusieurs classes comme la classification de différents groupes d'âge sont appelées problèmes de classification multiclasses. Les problèmes de classification sont l'un des types de problèmes de ML les plus couramment utilisés ou définis qui peuvent être utilisés dans divers cas d'utilisation. Il existe différents modèles d'apprentissage automatique qui peuvent être utilisés pour les problèmes de classification.
Allant des techniques de bagging aux techniques de boosting, bien que ML soit plus que capable de gérer les cas d'utilisation de classification, les réseaux de neurones entrent en scène lorsque nous avons une grande quantité de classes de sortie et une grande quantité de données pour soutenir les performances du modèle. À l'avenir, nous verrons comment nous pouvons implémenter un modèle de classification à l'aide de réseaux de neurones sur Keras (Python).
Apprenez le cours d'intelligence artificielle des meilleures universités du monde. Gagnez des programmes de maîtrise, Executive PGP ou Advanced Certificate pour accélérer votre carrière.
Table des matières
Les réseaux de neurones
Les réseaux de neurones sont vaguement représentatifs de l'apprentissage du cerveau humain. Un réseau de neurones artificiels est constitué de neurones qui, à leur tour, sont responsables de la création de couches. Ces neurones sont également appelés paramètres accordés.
La sortie de chaque couche est transmise à la couche suivante. Il existe différentes fonctions d'activation non linéaires pour chaque couche, ce qui facilite le processus d'apprentissage et la sortie de chaque couche. La couche de sortie est également connue sous le nom de neurones terminaux.

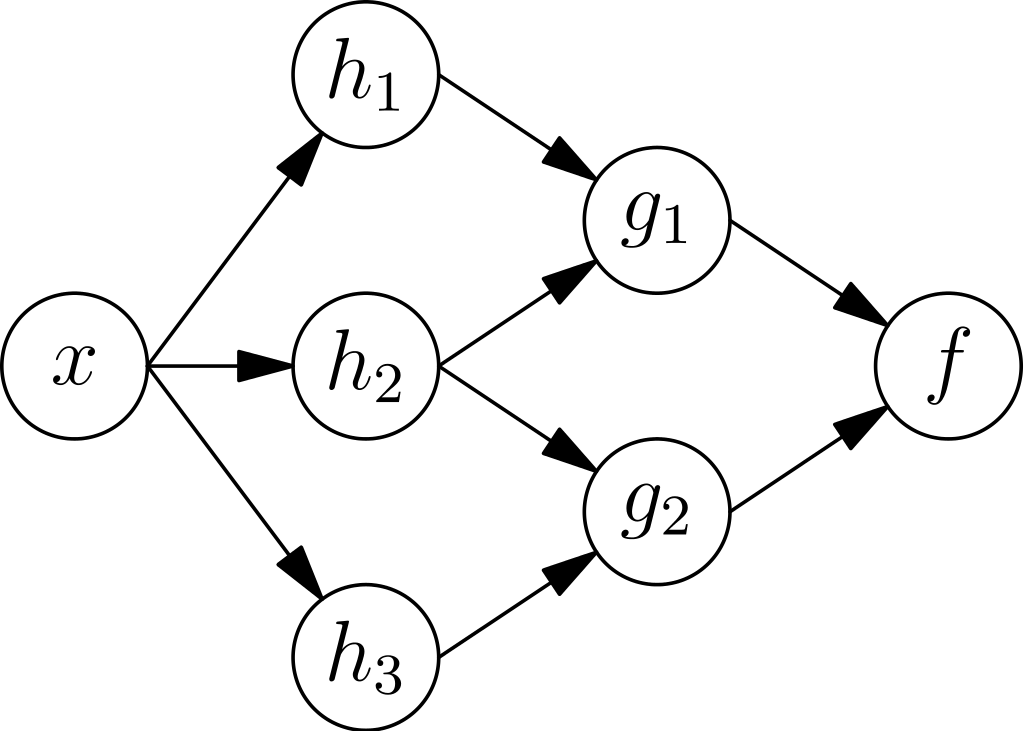
Source : Wikipédia
Les poids associés aux neurones et qui sont responsables des prédictions globales sont mis à jour à chaque époque. Le taux d'apprentissage est optimisé à l'aide de divers optimiseurs. Chaque réseau neuronal est doté d'une fonction de coût qui est minimisée au fur et à mesure que l'apprentissage se poursuit. Les meilleurs poids sont alors utilisés sur lesquels la fonction de coût donne les meilleurs résultats.
Lire : Tutoriel de détection d'objets TensorFlow pour les débutants
Problème de classification
Pour cet article, nous utiliserons Keras pour créer le réseau de neurones. Keras peut être directement importé en python à l'aide des commandes suivantes.
importer tensorflow en tant que tf
à partir de keras d'importation tensorflow
depuis keras.models import séquentiel
de keras.layers importer Dense
Ensemble de données et variable cible
Nous utiliserons l'ensemble de données sur le diabète qui aura les caractéristiques suivantes :
Variables d'entrée (X) :
- Grossesses : Nombre de fois enceintes
- Glucose : Concentration plasmatique de glucose à 2 heures dans un test oral de tolérance au glucose
- Tension artérielle : tension artérielle diastolique (mm Hg)
- Épaisseur de la peau : Épaisseur du pli cutané du triceps (mm)
- Insuline : insuline sérique de 2 heures (mu U/ml)
- IMC : Indice de masse corporelle (poids en kg/(taille en m)^2)
- DiabetesPedigreeFunction : fonction d'arbre généalogique du diabète
- Âge : Âge (ans)
Variables de sortie (y) :
Résultat : Variable de classe (0 ou 1) [Le patient est diabétique ou non]
# charger le jeu de données
df= loadtxt('pima-indians-diabetes.csv', delimiter=',')
# Diviser les données en X (entrée) et Y (sortie)
X = jeu de données[:,0:8]
y = jeu de données[:,8]
Définir le modèle Keras
Nous pouvons commencer à construire le réseau neuronal en utilisant des modèles séquentiels. Cette approche descendante aide à construire une architecture de réseau neuronal et à jouer avec la forme et les couches. La première couche aura le nombre d'entités qui peuvent être corrigées à l'aide de input_dim. Nous le mettrons à 8 dans cette condition.
La création de réseaux de neurones n'est pas un processus très facile. Il y a beaucoup d'essais et d'erreurs qui ont lieu avant qu'un bon modèle ne soit construit. Nous allons construire une structure de réseau entièrement connectée en utilisant la classe Dense dans keras. Le Neuron compte comme premier argument à fournir à la couche dense.
La fonction d'activation peut être définie à l'aide de l'argument d'activation. Nous utiliserons l'unité linéaire rectifiée comme fonction d'activation dans ce cas. Il existe d'autres options comme Sigmoid ou TanH, mais RELU est une option très généralisée et meilleure.

# définir le modèle keras
modèle = Séquentiel()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoïde'))
Compiler le modèle Keras
La compilation du modèle est la prochaine étape après la définition du modèle. Tensorflow est utilisé pour la compilation de modèles. La compilation est le processus au cours duquel les paramètres sont définis pour la formation et les prédictions du modèle. CPU/GPU ou mémoires distribuées peuvent être utilisés en arrière-plan.
Nous devons spécifier une fonction de perte qui est utilisée pour évaluer les poids des différentes couches. L'optimiseur ajuste le taux d'apprentissage et passe par différents ensembles de pondérations. Dans ce cas, nous utiliserons l'entropie croisée binaire comme fonction de perte. Dans le cas de l'optimiseur, nous utiliserons ADAM qui est un algorithme efficace de descente de gradient stochastique.
Il est très couramment utilisé pour le réglage. Enfin, comme il s'agit d'un problème de classification, nous allons collecter et rapporter la précision de la classification, définie via l'argument metrics. Nous utiliserons la précision dans ce cas.
# compiler le modèle keras
model.compile(loss='binary_crossentropy', optimiseur='adam', metrics=['accuracy'])
Ajustement du modèle et évaluation
L'ajustement du modèle est essentiellement connu sous le nom de formation de modèle. Après avoir compilé le modèle, le modèle est prêt à parcourir efficacement les données et à s'entraîner. La fonction fit() de Keras peut être utilisée pour le processus de formation du modèle. Les deux principaux paramètres utilisés avant l'entraînement du modèle sont :
- Époques : un passage dans l'ensemble de données.
- Taille du lot : les poids sont mis à jour à chaque taille de lot. Les époques consistent en des lots de données également répartis.
# adapter le modèle keras au jeu de données
model.fit(X, y, époques=150, batch_size=10)
Un GPU ou un CPU est utilisé dans ce processus. La formation peut être un processus très long en fonction des époques, de la taille des lots et surtout de la taille des données.
Nous pouvons également évaluer le modèle sur l'ensemble de données d'apprentissage à l'aide de la fonction évalue(). Les données peuvent être divisées en ensembles d'apprentissage et de test et les tests X et Y peuvent être utilisés pour l'évaluation du modèle.
Pour chaque paire d'entrée et de sortie, cela produira une prévision et rassemblera des scores, y compris la perte moyenne et toutes les mesures que nous avons installées, telles que la précision.
Une liste de deux valeurs sera retournée par la fonction évalue(). Le premier sera la perte du modèle sur le jeu de données et le second sera la précision du modèle sur le jeu de données. Nous ne sommes intéressés que par l'exactitude du rapport, nous ne tiendrons donc pas compte de l'importance de la perte.
# évaluer le modèle keras
_, précision = model.evaluate(Xtest, ytest)
print('Précision : %.2f' % (précision*100))
Lisez également : Introduction au modèle de réseau neuronal
Conclusion
Nous avons créé et évalué un réseau de neurones basé sur la classification. Bien que les données utilisées soient petites dans ce cas, les réseaux de neurones conviennent principalement aux grands ensembles de données numériques.
Consultez le programme de certificat avancé d'upGrad en apprentissage automatique et en PNL. Ce cours a été conçu en gardant à l'esprit différents types d'étudiants intéressés par l'apprentissage automatique, offrant un mentorat 1-1 et bien plus encore.
Comment utiliser les réseaux de neurones pour la classification ?
La classification consiste à catégoriser des objets en groupes. Un type de classification est l'endroit où plusieurs classes sont prédites. Dans les réseaux neuronaux, les unités neuronales sont organisées en couches. Dans la première couche, l'entrée est traitée et une sortie est produite. Cette sortie est ensuite envoyée à travers les couches restantes pour produire la sortie finale. La même entrée est traitée à travers la couche pour produire différentes sorties. Ceci peut être représenté avec un perceptron multicouche. Le type de réseau de neurones utilisé pour la classification dépend de l'ensemble de données, mais les réseaux de neurones ont été utilisés pour des problèmes de classification.
Pourquoi les réseaux de neurones artificiels sont-ils bons pour la classification ?
Afin de répondre à cette question, nous devons comprendre le principe de base des réseaux de neurones et le problème que les réseaux de neurones sont conçus pour résoudre. Comme son nom l'indique, les réseaux de neurones sont un modèle biologiquement inspiré du cerveau humain. L'idée de base est que nous voulons modéliser un neurone comme une fonction mathématique. Chaque neurone prend des entrées d'autres neurones et calcule une sortie. Ensuite, nous connectons ces neurones d'une manière qui imite le réseau neuronal dans le cerveau. L'objectif est d'apprendre un réseau qui peut prendre certaines données et produire une sortie appropriée.
Quand devrions-nous utiliser les réseaux de neurones artificiels ?
Les réseaux de neurones artificiels sont utilisés dans des situations où vous essayez de dupliquer les performances d'organismes vivants ou de détecter des modèles dans les données. Les diagnostics médicaux, la reconnaissance de la parole, la visualisation des données et la prédiction des chiffres manuscrits sont tous de bons cas d'utilisation pour un ANN. Les réseaux de neurones artificiels sont utilisés lorsqu'il est nécessaire de comprendre les relations complexes entre les entrées et les sorties. Par exemple, il peut y avoir beaucoup de bruit dans les variables et il peut être difficile de comprendre les relations entre ces variables. Par conséquent, l'utilisation de réseaux de neurones artificiels est une pratique courante pour conserver les connaissances et les données.