
Modelo de Clasificación usando Redes Neuronales Artificiales (ANN)
Publicado: 2020-12-01En la terminología de aprendizaje automático, la clasificación se refiere a un problema de modelado predictivo en el que los datos de entrada se clasifican como una de las clases etiquetadas predefinidas. Por ejemplo, predecir Sí o No, Verdadero o Falso cae en la categoría de Clasificación binaria ya que el número de resultados está limitado a dos etiquetas.
Del mismo modo, los resultados que tienen múltiples clases, como la clasificación de diferentes grupos de edad, se denominan problemas de clasificación multiclase. Los problemas de clasificación son uno de los tipos de problemas de ML más utilizados o definidos que se pueden utilizar en varios casos de uso. Hay varios modelos de Machine Learning que se pueden usar para problemas de clasificación.
Desde técnicas de embolsado hasta técnicas de refuerzo, aunque ML es más que capaz de manejar casos de uso de clasificación, las redes neuronales entran en escena cuando tenemos una gran cantidad de clases de salida y una gran cantidad de datos para respaldar el rendimiento del modelo. En el futuro, veremos cómo podemos implementar un modelo de clasificación utilizando redes neuronales en Keras (Python).
Aprenda el curso de inteligencia artificial de las mejores universidades del mundo. Obtenga programas de maestría, PGP ejecutivo o certificado avanzado para acelerar su carrera.
Tabla de contenido
Redes neuronales
Las redes neuronales son vagamente representativas del aprendizaje del cerebro humano. Una Red Neuronal Artificial está formada por Neuronas que a su vez se encargan de crear capas. Estas neuronas también se conocen como parámetros sintonizados.
La salida de cada capa se pasa a la siguiente capa. Hay diferentes funciones de activación no lineal para cada capa, lo que ayuda en el proceso de aprendizaje y la salida de cada capa. La capa de salida también se conoce como neuronas terminales.

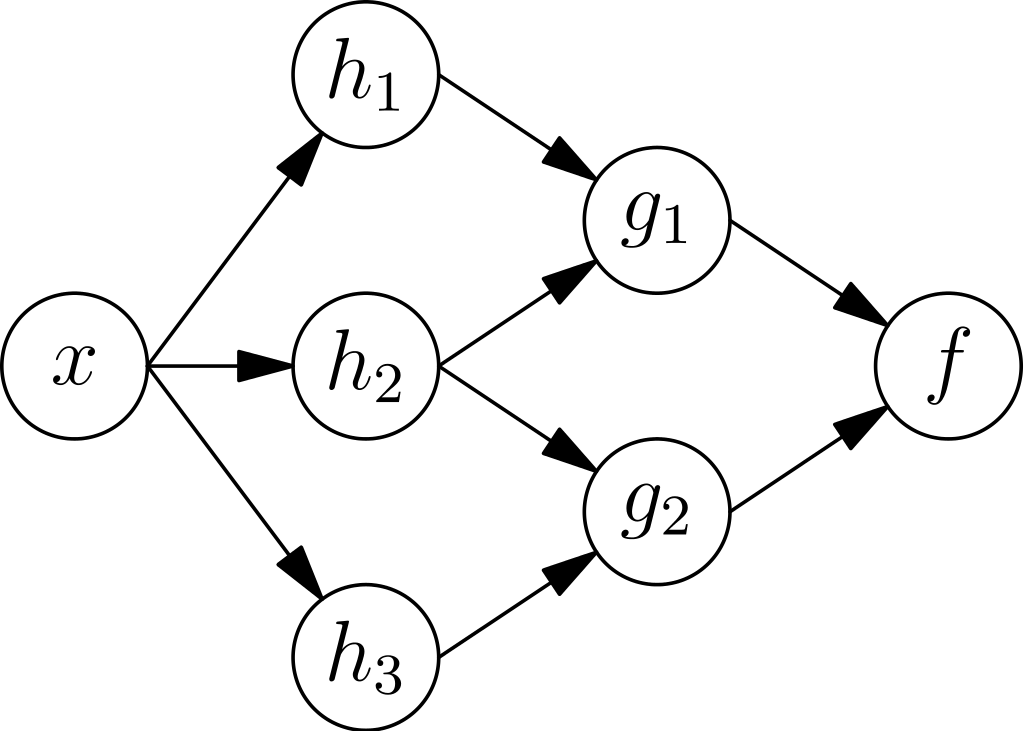
Fuente: Wikipedia
Los pesos asociados a las neuronas y que son responsables de las predicciones globales se actualizan en cada época. La tasa de aprendizaje se optimiza utilizando varios optimizadores. Cada red neuronal cuenta con una función de costo que se minimiza a medida que continúa el aprendizaje. Luego se utilizan los mejores pesos en los que la función de costo está dando los mejores resultados.
Leer: Tutorial de detección de objetos de TensorFlow para principiantes
Problema de clasificación
Para este artículo, usaremos Keras para construir la red neuronal. Keras se puede importar directamente en python usando los siguientes comandos.
importar tensorflow como tf
de tensorflow importar keras
de keras.models import Secuencial
de keras.layers import Dense
Conjunto de datos y variable de destino
Usaremos el conjunto de datos de diabetes que tendrá las siguientes características:
Variables de Entrada (X):
- Embarazos: Número de veces embarazadas
- Glucosa: concentración de glucosa en plasma a las 2 horas en una prueba de tolerancia oral a la glucosa
- Presión arterial: presión arterial diastólica (mm Hg)
- Grosor de la piel: Grosor del pliegue cutáneo del tríceps (mm)
- Insulina: insulina sérica de 2 horas (mu U/ml)
- IMC: Índice de masa corporal (peso en kg/(altura en m)^2)
- DiabetesPedigreeFunction: función de pedigrí de diabetes
- Edad: Edad (años)
Variables de salida (y):
Resultado: Variable de clase (0 o 1) [El paciente tiene diabetes o no]
# cargar el conjunto de datos
df= loadtxt('pima-indians-diabetes.csv', delimitador=',')
# Dividir datos en X (entrada) e Y (salida)
X = conjunto de datos[:,0:8]
y = conjunto de datos[:,8]
Definir modelo de Keras
Podemos comenzar a construir la red neuronal usando modelos secuenciales. Este enfoque de arriba hacia abajo ayuda a construir una arquitectura de red neuronal y jugar con la forma y las capas. La primera capa tendrá la cantidad de características que se pueden corregir usando input_dim. Lo pondremos en 8 en esta condición.
Crear Redes Neuronales no es un proceso muy fácil. Hay muchas pruebas y errores que tienen lugar antes de construir un buen modelo. Construiremos una estructura de red Totalmente Conectada usando la clase Densa en keras. La Neurona cuenta como el primer argumento que se proporciona a la capa densa.
La función de activación se puede configurar usando el argumento de activación. Usaremos la Unidad Lineal Rectificada como función de activación en este caso. Hay otras opciones como Sigmoid o TanH, pero RELU es una opción muy generalizada y mejor.

# definir el modelo de keras
modelo = Secuencial()
modelo.add(Dense(12, input_dim=8, activación='relu'))
modelo.add(Dense(8, activación='relu'))
modelo.add(Dense(1, activación='sigmoide'))
Compilar el modelo de Keras
La compilación del modelo es el siguiente paso después de la definición del modelo. Tensorflow se utiliza para la compilación de modelos. La compilación es el proceso en el que se establecen parámetros para el entrenamiento y las predicciones del modelo. CPU/GPU o memorias distribuidas se pueden utilizar en segundo plano.
Tenemos que especificar una función de pérdida que se utiliza para evaluar los pesos de las diferentes capas. El optimizador ajusta la tasa de aprendizaje y pasa por varios conjuntos de pesos. En este caso, utilizaremos la entropía cruzada binaria como función de pérdida. En el caso del optimizador, usaremos ADAM, que es un algoritmo de descenso de gradiente estocástico eficiente.
Es muy popularmente utilizado para la afinación. Finalmente, debido a que es un problema de clasificación, recopilaremos e informaremos la precisión de la clasificación, definida a través del argumento de las métricas. Usaremos la precisión en este caso.
# compilar el modelo de keras
model.compile(pérdida='binary_crossentropy', Optimizer='adam', metrics=['accuracy'])
Ajuste y evaluación del modelo
El ajuste del modelo se conoce esencialmente como entrenamiento del modelo. Después de compilar el modelo, el modelo está listo para repasar los datos de manera eficiente y entrenarse a sí mismo. La función fit() de Keras se puede utilizar para el proceso de entrenamiento del modelo. Los dos parámetros principales utilizados antes del entrenamiento del modelo son:
- Épocas: una pasada por todo el conjunto de datos.
- Tamaño de lote: los pesos se actualizan en cada tamaño de lote. Las épocas consisten en lotes de datos igualmente distribuidos.
# ajuste el modelo de keras en el conjunto de datos
model.fit(X, y, epochs=150, batch_size=10)
En este proceso se utiliza una GPU o una CPU. La capacitación puede ser un proceso muy largo según las épocas, el tamaño del lote y, lo que es más importante, el tamaño de los datos.
También podemos evaluar el modelo en el conjunto de datos de entrenamiento usando la función evaluar(). Los datos se pueden dividir en conjuntos de entrenamiento y prueba, y las pruebas X e Y se pueden usar para la evaluación del modelo.
Para cada par de entrada y salida, esto producirá un pronóstico y recopilará puntajes, incluida la pérdida promedio y cualquier medida que hayamos instalado, como la precisión.
La función evaluar() devolverá una lista de dos valores. El primero será la pérdida del modelo en el conjunto de datos y el segundo será la precisión del modelo en el conjunto de datos. Solo nos interesa la exactitud del informe, por lo que no tomaremos en cuenta la importancia de la pérdida.
# evaluar el modelo de keras
_, precisión = modelo.evaluar(Xtest, ytest)
imprimir('Precisión: %.2f' % (precisión*100))
Lea también: Introducción al modelo de red neuronal
Conclusión
Creamos y evaluamos una Red Neuronal basada en clasificación. Aunque los datos utilizados fueron pequeños en este caso, las redes neuronales son en su mayoría adecuadas para grandes conjuntos de datos numéricos.
Consulte el programa de certificado avanzado de upGrad en aprendizaje automático y PNL. Este curso se ha diseñado teniendo en cuenta varios tipos de estudiantes interesados en el aprendizaje automático, ofrece tutoría 1-1 y mucho más.
¿Cómo se pueden utilizar las redes neuronales para la clasificación?
La clasificación consiste en categorizar objetos en grupos. Un tipo de clasificación es donde se predicen múltiples clases. En las redes neuronales, las unidades neuronales se organizan en capas. En la primera capa, se procesa la entrada y se produce una salida. Esta salida luego se envía a través de las capas restantes para producir la salida final. La misma entrada se procesa a través de la capa para producir diferentes salidas. Esto se puede representar con un perceptrón multicapa. El tipo de red neuronal utilizada para la clasificación depende del conjunto de datos, pero las redes neuronales se han utilizado para problemas de clasificación.
¿Por qué las redes neuronales artificiales son buenas para la clasificación?
Para responder a esta pregunta, debemos comprender el principio básico de las redes neuronales y el problema que las redes neuronales están diseñadas para resolver. Como sugiere su nombre, las redes neuronales son un modelo inspirado biológicamente del cerebro humano. La idea básica es que queremos modelar una neurona como una función matemática. Cada neurona toma entradas de otras neuronas y calcula una salida. Luego conectamos estas neuronas de una manera que imita la red neuronal en el cerebro. El objetivo es aprender una red que pueda tomar algunos datos y producir un resultado apropiado.
¿Cuándo debemos utilizar Redes Neuronales Artificiales?
Las redes neuronales artificiales se utilizan en situaciones en las que intenta duplicar el rendimiento de organismos vivos o detectar patrones en los datos. Los diagnósticos médicos, el reconocimiento del habla, la visualización de datos y la predicción de dígitos escritos a mano son buenos casos de uso para una ANN. Las redes neuronales artificiales se utilizan cuando existe la necesidad de comprender relaciones complejas entre entradas y salidas. Por ejemplo, puede haber mucho ruido en las variables y puede ser difícil entender las relaciones entre estas variables. Por lo tanto, el uso de Redes Neuronales Artificiales es una práctica común para retener el conocimiento y los datos.