
神經網絡的構建塊:解釋神經網絡的組件
已發表: 2020-12-16目錄
介紹
近年來,深度學習的普及在行業各個領域的使用和應用方面都出現了急劇下降。 無論是圖像識別、語音生成、翻譯以及更多此類應用,幾乎每家公司都希望將這項技術集成到他們正在構建的一個或其他產品中。 這種超越傳統機器學習算法的優勢的原因是這些深度學習模型提供的準確性和高效性能。
儘管基礎設施在提供這些結果方面發揮著重要作用,但核心代碼完成了包含在神經網絡中的所有處理。 讓我們探索這個網絡的各種組件,然後我們將看看使用這些組件的一些基本單元。
必讀:神經網絡模型介紹
神經網絡的各種組件
神經元
神經網絡的基本構建塊是神經元。 這個概念與我們人類大腦中的實際神經網絡非常相似。 這個人工神經元接受所有的輸入,聚合它們,然後基於一個函數給出神經元的輸出。
神經網絡由許多這樣的神經元組成,這些神經元以稱為輸入層、隱藏層和輸出層的層的形式相互連接。 該網絡使我們能夠將任何類型的複雜數據模式映射到數學函數,這可以使用通用逼近定理在數學上進行驗證。
重量
該模型可以具有權重,以便可以使用負值抑制高值。 您可以通過購買智能手機的例子來解釋這一點。 價格越高,購買該智能手機的機會就越低,但如果我們的模型將所有值相加並將其與閾值進行比較,則可能會做出錯誤的預測。 為了消除這種影響,負權重應該減少總和並獲得正確的預測。

激活函數
在神經元定義中提到,基於函數,如果神經元是輸入層或隱藏層的一部分,或者用於輸出層的進一步處理,神經元會將結果輸出到下一層。
這個函數稱為激活函數,它定義了神經元的狀態。 市場上有很多激活功能可以完成這項工作,但這一切都取決於用例。 例如 sigmoid 函數、tanh 函數、softmax 函數、Relu(整流線性單元)、leaky Relu 等等。
學習率
它可以控制權重更新的速度。 考慮學習率作為重要因素的兩種情況。 如果輸入特徵具有更稀疏的值,那麼我們需要更頻繁地更新權重,這就是需要更大學習率的原因。 同樣,低學習率可以在密集數據中工作。
讓我們看一下在更大的神經網絡中使用這些組件的一些基本單元。
MP神經元
這是人工神經元的最基本形式,它計算輸入總和,然後將其傳遞給激活函數以獲得最終輸出。 這是一個視覺效果:
對此的限制因素是輸入應該是二進制的並且不允許實數。 這意味著如果我們想使用具有不同值的數據集,則需要將其縮放為二進制才能傳遞給模型。
該模型的輸出也是二進制的,因此很難解釋結果的質量。 輸入沒有任何權重,因此我們無法控制特徵對結果的貢獻程度。
感知器神經元
MP 神經元的一個顯著缺點是它不能接受實數作為輸入,這可能會導致不良結果。 這意味著如果我們想將輸入特徵傳遞給這個具有實數的神經元,則需要將其縮小到 1 或 0。 在這個神經元模型中,對輸入沒有這樣的限制,但是通過標準化的輸入會在更短的時間內給出更好的結果,因為輸入的聚合對於所有特徵值都是公平的。

還引入了一種學習算法,這使得該模型對新輸入更加穩健。 該算法根據損失函數更新應用於每個輸入的權重。 損失函數決定了模型的實際值和預測值之間的差異。 平方誤差損失是深度學習模型中使用的一種流行函數。
由於感知神經元也給出二進制輸出,因此損失可以為零或一。 這意味著我們可以將這種類型的損失函數以更緊湊的方式定義為“當預測不等於真實值時,損失為 1,需要更新權重,否則為零損失且不需要更新”。 權重的更新通過以下方式完成:
w = w + x 如果 wx < 0
w = w – x 如果 wx >= 0
閱讀:面向初學者的 TensorFlow 對象檢測教程
乙狀結腸神經元
與 MP 神經元相比,感知器神經元似乎很有前景,但仍有一些問題需要解決。 它們的一個主要缺陷是它們只支持二進制分類。 另一個問題是嚴格的分類邊界,僅輸出特定情況是否可能。 它不允許以比二進制輸出更易解釋的概率形式進行預測的靈活性。
為了解決所有這些問題,引入了 Sigmoid 神經元,可用於多分類和回歸任務。 該模型使用 sigmoid 系列函數或對數:
y = 1 / (1 + e^ (-wx + b))
如果我們繪製這個函數,那麼它將採用“S”形,可以通過使用不同的“b”值來調整它的位置,“b”是這條曲線的截距。 無論傳遞多少輸入,此函數的輸出始終介於 0 和 1 之間。 這給出了類的概率,這比剛性輸出要好。 這也意味著我們可以有多個分類或執行回歸。
用於此的學習算法與以前的不同。 這裡根據損失函數的導數更新權重和偏差。
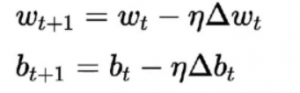
該算法通常稱為梯度下降規則。 對此的推導和詳細解釋非常冗長且數學化,因此目前不在本文中。 簡單來說,它表明要獲得損失函數導數的最優最小值,我們應該沿著與梯度相反的方向移動。
結論
這是對神經網絡的簡要介紹。 我們看到了各種基本組件,例如充當迷你大腦並處理輸入的神經元、允許平衡值的權重、控制權重更新速度的學習率以及激活神經元的激活函數。
我們還看到了基本的構建塊神經元如何在增加任務的複雜性方面採取不同的形式。 我們從 MP 神經元中最基本的形式開始,然後消除感知器神經元中的一些問題,然後在 sigmoid 神經元中添加對回歸和多類分類任務的支持。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
什麼是人工智能中的神經網絡?
神經網絡或人工神經網絡(ANN)是指受生物學啟發的計算網絡,即存在於人腦中的神經網絡。 就像人腦由數十億個神經元組成一個相互連接的網絡一樣,人工神經網絡也包括在各個層相互連接的神經元。 這些神經元在人工智能領域也被稱為節點。 開發人工神經網絡的概念是為了賦予計算機類似人類的理解事物和形成決策的能力; 這裡的節點或計算機被編程為像我們大腦的相互連接的細胞一樣。
在人工智能領域找到工作需要哪些技能?
由於人工智能是一個高度專業化的計算機科學領域,因此想要在人工智能領域建立職業生涯的人,除了具備分析思維、設計能力和解決問題能力等技能外,還必須具備一定的學歷。 非常成功的人工智能專業人士還具有技術創新的遠見,這使現代企業能夠擁有在競爭中保持領先所需的經濟高效的軟件解決方案。 不用說,出色的口頭和書面溝通技巧是必須的。 技術教育背景對於理解 AI 項目的邏輯、工程和技術觀點是必要的。
學習神經網絡的一般先決條件是什麼?
要從事任何大型人工智能項目,您需要對人工神經網絡的基本原理有清晰的了解。 要構建神經網絡的基本概念,首先,您必須閱讀大量書籍、文章和新聞文章。 一般來說,在學習神經網絡概念的先決條件中,數學起著至關重要的作用,尤其是統計學、線性代數、微積分、概率等。 除此之外,還需要 Python、Java、R 和 C++ 等語言的計算機編程技能。 中級編程技能在這裡也有很大幫助。