
Elementi costitutivi delle reti neurali: spiegazione dei componenti delle reti neurali
Pubblicato: 2020-12-16Sommario
introduzione
Negli ultimi anni, la popolarità del deep learning ha preso una brusca inclinazione in termini di utilizzo e applicazione in ogni settore del settore. Che si tratti di riconoscimento delle immagini, generazione vocale, traduzione e molte altre applicazioni simili, quasi tutte le aziende desiderano integrare questa tecnologia nell'uno o nell'altro prodotto che stanno costruendo. La ragione di questa supremazia sui tradizionali algoritmi di machine learning è l'accuratezza e le prestazioni efficienti fornite da questi modelli di Deep Learning.
Sebbene l'infrastruttura svolga un ruolo importante nel fornire questi risultati, il codice principale esegue tutte le elaborazioni racchiuse in una rete neurale. Esploriamo i vari componenti di questa rete e poi esamineremo alcune unità fondamentali che utilizzano questi componenti.
Da leggere: Introduzione al modello di rete neurale
Vari componenti della rete neurale
Neurone
L'elemento costitutivo di base di una rete neurale è un neurone. Questo concetto è molto simile alla vera rete neurale nel nostro cervello umano. Questo neurone artificiale prende tutti gli input, li aggrega e quindi, in base a una funzione, fornisce l'output del neurone.
Una rete neurale comprende molti di questi neuroni interconnessi tra loro sotto forma di livelli noti come livelli di input, nascosti e di output. Questa rete ci consente di mappare qualsiasi tipo di modello di dati complessi su una funzione matematica, e questo può essere verificato matematicamente usando il teorema di approssimazione universale.
Pesi
Il modello può avere pesi in modo che i valori elevati possano essere soppressi utilizzando valori negativi. Puoi interpretarlo facendo un esempio di acquisto di uno smartphone. Più alto è il prezzo, minori saranno le possibilità di acquistare quello smartphone, ma se il nostro modello somma tutti i valori e lo confronta con la soglia, potrebbe essere fatta la previsione sbagliata. Per annullare questo effetto, i pesi negativi dovrebbero ridurre la somma e ottenere la previsione corretta.

Funzione di attivazione
C'era una menzione nella definizione del neurone che, in base a una funzione, il neurone trasmetterà il risultato al livello successivo se fa parte del livello di input o nascosto o utilizzato per un'ulteriore elaborazione nel livello di output.
Questa funzione è chiamata funzione di attivazione e definisce lo stato del neurone. Ci sono molte funzioni di attivazione disponibili sul mercato che possono fare il lavoro, ma tutto dipende dal caso d'uso. Esempi sono la funzione sigmoidea, la funzione tanh, la funzione softmax, Relu (unità lineare rettificata), Relu che perde e molti altri.
Tasso di apprendimento
Può controllare il ritmo dell'aggiornamento del peso. Considera due casi in cui il tasso di apprendimento agisce come un fattore importante. Se una funzione di input ha valori più sparsi, è necessario aggiornare i pesi più frequentemente, ed è per questo che si desidera un tasso di apprendimento maggiore. Allo stesso modo, un tasso di apprendimento basso può funzionare in dati densi.
Diamo un'occhiata ad alcune unità fondamentali che utilizzano questi componenti in reti neurali più grandi.
Neurone MP
Questa è la forma più semplice di neurone artificiale che calcola la somma di input e quindi la passa alla funzione di attivazione per ottenere l'output finale. Ecco una visuale di questo:
Il fattore limitante è che gli input devono essere binari e non è consentito alcun numero reale. Ciò significa che se vogliamo utilizzare un set di dati con valori diversi, è necessario ridimensionarlo in binario per essere passato al modello.
Anche gli output di questo modello sono binari, il che rende difficile interpretare la qualità dei risultati. Gli input non hanno alcun peso, quindi non possiamo controllare quanto contributo avrà una funzione al risultato.
Neurone Perceptron
Uno degli svantaggi significativi dei neuroni MP era che non può accettare numeri reali come input, il che può portare a risultati indesiderati. Significa che se vogliamo passare una funzione di input a questo neurone con numeri reali, deve essere ridimensionata a 1 o 0. In questo modello di neurone, non esiste tale limitazione sugli input, ma il passaggio di input standardizzati darà risultati migliori in meno tempo poiché l'aggregazione degli input sarebbe equa per tutti i valori delle caratteristiche.
Viene inoltre introdotto un algoritmo di apprendimento, che rende questo modello ancora più robusto ai nuovi input. L'algoritmo aggiorna i pesi applicati a ciascun input in base alla funzione di perdita. La funzione di perdita determina la differenza tra il valore effettivo e il valore previsto dal modello. La perdita di errore al quadrato è una di queste funzioni popolari utilizzate nei modelli di deep learning.

Poiché anche il neurone di percezione emette un output binario, la perdita può essere zero o uno. Significa che possiamo definire la funzione di perdita di questo tipo in modo più compatto come "Quando la previsione non è uguale al valore reale, la perdita è uno e i pesi devono essere aggiornati altrimenti zero perdita e nessun aggiornamento necessario". Gli aggiornamenti dei pesi vengono effettuati nel modo seguente:
w = w + x se wx < 0
w = w – x se wx >= 0
Leggi: Tutorial sul rilevamento di oggetti TensorFlow per principianti
Neurone sigmoideo
Il neurone perceptron sembra promettente rispetto al neurone MP, ma ci sono ancora alcuni problemi che devono essere affrontati. Uno dei principali difetti in entrambi è che supportano solo la classificazione binaria. Un altro problema sono i rigidi confini di classificazione che indicano solo se un caso particolare è possibile. Non consente flessibilità nelle previsioni sotto forma di probabilità che sono più interpretabili degli output binari.
Per risolvere tutti questi problemi, è stato introdotto il neurone Sigmoide, che può essere utilizzato per la multiclassificazione e l'esecuzione di compiti di regressione. Questo modello utilizza la famiglia sigmoidea di funzioni o logaritmica:
y = 1 / (1 + e^ (-wx + b))
Se tracciamo questa funzione, assumerebbe la forma a "S" in cui la sua posizione può essere regolata utilizzando diversi valori di "b" che è l'intercetta di questa curva. L'output di questa funzione è sempre compreso tra 0 e 1, indipendentemente dal numero di input passati. Questo dà la probabilità della classe, che è migliore degli output rigidi. Ciò significa anche che possiamo avere più classificazioni o eseguire la regressione.
L'algoritmo di apprendimento per questo differisce dai precedenti. Qui i pesi e la deviazione vengono aggiornati in base alla derivata della funzione di perdita.
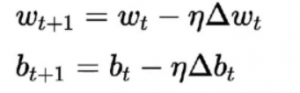
Questo algoritmo è comunemente noto come regola di discesa del gradiente. La derivazione e la spiegazione dettagliata per questo è piuttosto lunga e matematica, quindi è attualmente fuori da questo articolo. In parole povere, afferma che per ottenere un minimo ottimale per la derivata della funzione di perdita, dobbiamo muoverci in direzione opposta al gradiente.
Conclusione
Questa è stata una breve introduzione alle reti neurali. Abbiamo visto i vari componenti di base come il neurone che funge da mini-cervello ed elabora gli input, i pesi che consentono di bilanciare i valori, il tasso di apprendimento per controllare come il ritmo dei pesi si aggiorna e la funzione di attivazione per accendere i neuroni.
Abbiamo anche visto come il neurone del blocco costitutivo di base può assumere forme diverse aumentando la complessità del compito. Abbiamo iniziato con la forma più elementare nel neurone MP, quindi eliminando alcuni problemi nel neurone Perceptron e in seguito aggiungendo il supporto per le attività di regressione e classificazione multiclasse nel neurone sigmoideo.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Che cos'è una rete neurale nell'IA?
Una rete neurale o rete neurale artificiale (ANN) si riferisce a una rete computazionale ispirata alla biologia, ovvero le reti neurali presenti nel cervello umano. Proprio come il cervello umano è costituito da miliardi di neuroni che formano una rete interconnessa, anche la rete neurale artificiale comprende neuroni interconnessi a vari livelli. Questi neuroni sono anche conosciuti come nodi nel regno dell'intelligenza artificiale. Il concetto di reti neurali artificiali è stato sviluppato per impartire ai computer capacità simili a quelle umane di comprendere le cose e prendere decisioni; i nodi oi computer qui sono programmati per agire come cellule interconnesse del nostro cervello.
Quali competenze sono necessarie per ottenere un lavoro nell'IA?
Poiché l'IA è un campo altamente specializzato dell'informatica, coloro che aspirano a costruire una carriera nell'IA devono possedere determinati titoli di studio oltre ad abilità come il pensiero analitico, capacità di progettazione e capacità di risoluzione dei problemi. I professionisti dell'IA di grande successo hanno anche la lungimiranza delle innovazioni tecnologiche che consentono alle aziende moderne di disporre di soluzioni software convenienti ed efficienti necessarie per stare al passo con la concorrenza. Inutile dire che sono indispensabili ottime capacità di comunicazione verbale e scritta. È necessario un background di formazione tecnica per apprezzare le prospettive logiche, ingegneristiche e tecnologiche dei progetti di IA.
Quali sono i prerequisiti generali per l'apprendimento delle reti neurali?
Per lavorare su qualsiasi progetto di intelligenza artificiale su larga scala, ci si aspetta che tu abbia una chiara comprensione dei fondamenti delle reti neurali artificiali. Per costruire i tuoi concetti di base sulle reti neurali, prima di tutto, devi leggere ampi libri, articoli e articoli di notizie. In generale, tra i prerequisiti per lo studio dei concetti di reti neurali, la matematica gioca un ruolo fondamentale, in particolare cose come la statistica, l'algebra lineare, il calcolo, la probabilità. Oltre a ciò, saranno necessarie anche competenze di programmazione informatica in linguaggi come Python, Java, R e C++. Anche le abilità di programmazione intermedie possono essere di grande aiuto qui.