
Bloki konstrukcyjne sieci neuronowych: objaśnienie elementów sieci neuronowych
Opublikowany: 2020-12-16Spis treści
Wstęp
W ostatnich latach popularność uczenia głębokiego gwałtownie spadła pod względem wykorzystania i zastosowania w każdym sektorze przemysłu. Niezależnie od tego, czy chodzi o rozpoznawanie obrazu, generowanie mowy, tłumaczenie i wiele innych tego typu aplikacji, prawie każda firma chce zintegrować tę technologię z jednym lub drugim produktem, który tworzy. Powodem tej wyższości nad tradycyjnymi algorytmami uczenia maszynowego jest dokładność i wydajna wydajność zapewniana przez te modele Deep Learning.
Chociaż infrastruktura odgrywa ważną rolę w dostarczaniu tych wyników, rdzeń kodu wykonuje całe przetwarzanie, które jest zawarte w sieci neuronowej. Przyjrzyjmy się różnym komponentom tej sieci, a następnie przyjrzymy się kilku podstawowym jednostkom wykorzystującym te komponenty.
Trzeba przeczytać: Wprowadzenie do modelu sieci neuronowej
Różne elementy sieci neuronowej
Neuron
Podstawowym budulcem sieci neuronowej jest neuron. Ta koncepcja jest bardzo podobna do rzeczywistej sieci neuronowej w naszych ludzkich mózgach. Ten sztuczny neuron pobiera wszystkie dane wejściowe, agreguje je, a następnie na podstawie funkcji podaje dane wyjściowe neuronu.
Sieć neuronowa składa się z wielu takich neuronów połączonych ze sobą w postaci warstw znanych jako warstwa wejściowa, ukryta i wyjściowa. Sieć ta umożliwia nam odwzorowanie dowolnego złożonego wzorca danych na funkcję matematyczną, co można zweryfikować matematycznie za pomocą uniwersalnego twierdzenia o aproksymacji.
Wagi
Model może mieć wagi, dzięki czemu wysokie wartości mogą być pomijane przy użyciu wartości ujemnych. Możesz to zinterpretować na przykładzie zakupu smartfona. Im wyższa cena, tym mniejsze szanse na zakup tego smartfona, ale jeśli nasz model zsumuje wszystkie wartości i porówna je z progiem, może dojść do błędnej prognozy. Aby zniwelować ten efekt, wagi ujemne powinny zmniejszyć sumę i uzyskać właściwą prognozę.

Funkcja aktywacji
W definicji neuronu była wzmianka, że w oparciu o funkcję neuron wyśle wynik albo do następnej warstwy, jeśli jest częścią warstwy wejściowej lub warstwy ukrytej, albo zostanie użyty do dalszego przetwarzania w warstwie wyjściowej.
Ta funkcja nazywana jest funkcją aktywacji i określa stan neuronu. Na rynku dostępnych jest wiele funkcji aktywacji, które mogą wykonać zadanie, ale wszystko zależy od przypadku użycia. Przykładami są funkcja sigmoidalna, funkcja tanh, funkcja softmax, Relu (wyprostowana jednostka liniowa), nieszczelny Relu i wiele innych.
Szybkość nauki
Może kontrolować tempo aktualizacji wagi. Rozważ dwa przypadki, w których szybkość uczenia się działa jako ważny czynnik. Jeśli funkcja wejściowa ma mniej wartości, musimy częściej aktualizować wagi i dlatego pożądana jest większa szybkość uczenia się. Podobnie niski wskaźnik uczenia się może działać w przypadku gęstych danych.
Przyjrzyjmy się kilku podstawowym jednostkom wykorzystującym te komponenty w większych sieciach neuronowych.
MP Neuron
Jest to najbardziej podstawowa forma sztucznego neuronu, która oblicza sumę wejściową, a następnie przekazuje ją do funkcji aktywacji, aby uzyskać ostateczny wynik. Oto wizualizacja tego:
Czynnikiem ograniczającym to jest to, że wejścia powinny być binarne i nie są dozwolone żadne liczby rzeczywiste. Oznacza to, że jeśli chcemy użyć zestawu danych z różnymi wartościami, należy go przeskalować do formatu binarnego, aby można go było przekazać do modelu.
Wyniki tego modelu są również binarne, co utrudnia interpretację jakości wyników. Dane wejściowe nie mają żadnych wag, więc nie możemy kontrolować, jaki wkład będzie miała funkcja w wyniku.
Neuron perceptronowy
Jedną z istotnych wad neuronów MP jest to, że nie mogą przyjmować liczb rzeczywistych jako danych wejściowych, co może prowadzić do niepożądanych wyników. Oznacza to, że jeśli chcemy przekazać temu neuronowi cechę wejściową z liczbami rzeczywistymi, należy ją przeskalować w dół do jedynek lub zer. W tym modelu neuronowym nie ma takiego ograniczenia danych wejściowych, ale przekazanie ustandaryzowanych danych wejściowych da lepsze wyniki w krótszym czasie, ponieważ agregacja danych wejściowych byłaby sprawiedliwa dla wszystkich wartości cech.
Wprowadzono również algorytm uczenia się, dzięki czemu model ten jest jeszcze bardziej odporny na nowe dane wejściowe. Algorytm aktualizuje wagi zastosowane do każdego wejścia na podstawie funkcji straty. Funkcja straty określa różnicę między wartością rzeczywistą a przewidywaną przez model. Utrata błędu kwadratowego jest jedną z takich popularnych funkcji stosowanych w modelach uczenia głębokiego.

Ponieważ neuron Percepcji również daje wyjście binarne, strata może wynosić zero lub jeden. Oznacza to, że możemy zdefiniować funkcję straty tego typu w bardziej zwięzły sposób, jako „Gdy prognoza nie jest równa prawdziwej wartości, strata wynosi jeden i wagi muszą być aktualizowane, w przeciwnym razie zerowa strata i nie ma potrzeby aktualizacji”. Aktualizacja wag odbywa się w następujący sposób:
w = w + x jeśli wx < 0
w = w – x jeśli wx >= 0
Przeczytaj: Samouczek wykrywania obiektów TensorFlow dla początkujących
Neuron esicy
Neuron perceptron wydaje się obiecujący w porównaniu z neuronem MP, ale nadal istnieją pewne problemy, które wymagają rozwiązania. Jedną z głównych wad obu z nich jest to, że obsługują tylko klasyfikację binarną. Inną kwestią są surowe granice klasyfikacji, które pokazują tylko, czy konkretny przypadek jest możliwy. Nie pozwala na elastyczność przewidywań w postaci prawdopodobieństw, które są bardziej interpretowalne niż wyjścia binarne.
Aby rozwiązać wszystkie te problemy, wprowadzono neuron Sigmoid, który może być używany do multiklasyfikacji i wykonywania zadań regresji. Model ten wykorzystuje sigmoidalną rodzinę funkcji lub logarytmiczne:
y = 1 / (1 + e^ (-wx + b))
Jeśli wykreślimy tę funkcję, przybierze ona kształt „S”, w którym jej położenie można dostosować za pomocą różnych wartości „b”, która jest punktem przecięcia tej krzywej. Wyjście tej funkcji zawsze mieści się w zakresie od 0 do 1, bez względu na to, ile danych wejściowych jest przekazywanych. Daje to prawdopodobieństwo klasy, które jest lepsze niż sztywne wyjścia. Oznacza to również, że możemy mieć wiele klasyfikacji lub przeprowadzić regresję.
Algorytm uczenia się tego różni się od poprzednich. Tutaj wagi i odchylenie są aktualizowane zgodnie z pochodną funkcji straty.
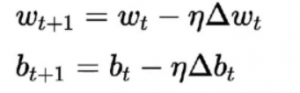
Algorytm ten jest powszechnie znany jako reguła opadania gradientu. Wyprowadzenie i szczegółowe wyjaśnienie tego jest dość długie i matematyczne, dlatego obecnie nie ma go w tym artykule. W uproszczeniu mówi, że aby uzyskać optymalne minima dla pochodnej funkcji straty, należy poruszać się w kierunku przeciwnym do gradientu.
Wniosek
To było krótkie wprowadzenie do sieci neuronowych. Widzieliśmy różne podstawowe komponenty, takie jak neuron, który działa jak mini-mózg i przetwarza dane wejściowe, wagi, które pozwalają zrównoważyć wartości, szybkość uczenia się kontrolowania tempa aktualizacji wag i funkcję aktywacji, która uruchamia neurony.
Zobaczyliśmy również, jak podstawowy neuron budulcowy może przybierać różne formy, zwiększając złożoność zadania. Zaczęliśmy od najbardziej podstawowej postaci w neuronie MP, następnie wyeliminowaliśmy pewne problemy w neuronie Perceptron, a później dodaliśmy obsługę regresji i zadań klasyfikacji wieloklasowej w neuronie sigmoidalnym.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czym jest sieć neuronowa w AI?
Sieć neuronowa lub sztuczna sieć neuronowa (ANN) odnosi się do sieci obliczeniowej inspirowanej biologią, tj. sieci neuronowych obecnych w ludzkim mózgu. Tak jak ludzki mózg składa się z miliardów neuronów, które tworzą połączoną sieć, sztuczna sieć neuronowa zawiera również neurony, które są połączone ze sobą w różnych warstwach. Te neurony są również znane jako węzły w sferze sztucznej inteligencji. Koncepcja sztucznych sieci neuronowych została opracowana w celu nadania komputerom podobnych do ludzi zdolności rozumienia rzeczy i podejmowania decyzji; węzły lub komputery tutaj są zaprogramowane do działania jak połączone komórki naszego mózgu.
Jakie umiejętności są potrzebne, aby dostać pracę w AI?
Ponieważ sztuczna inteligencja jest wysoce wyspecjalizowaną dziedziną informatyki, ci, którzy aspirują do kariery w AI, muszą posiadać pewne kwalifikacje edukacyjne oprócz umiejętności takich jak analityczne myślenie, umiejętności projektowania i umiejętności rozwiązywania problemów. Odnoszący duże sukcesy profesjonaliści AI mają również dalekowzroczność w zakresie innowacji technologicznych, które umożliwiają nowoczesnym firmom korzystanie z opłacalnych i wydajnych rozwiązań programowych potrzebnych do wyprzedzenia konkurencji. Nie trzeba dodawać, że doskonałe umiejętności komunikacji werbalnej i pisemnej są koniecznością. Wykształcenie techniczne jest niezbędne, aby docenić logiczne, inżynierskie i technologiczne perspektywy projektów AI.
Jakie są ogólne warunki wstępne uczenia się sieci neuronowych?
Aby pracować nad dowolnym projektem sztucznej inteligencji na dużą skalę, oczekuje się od Ciebie jasnego zrozumienia podstaw sztucznych sieci neuronowych. Aby zbudować podstawowe koncepcje sieci neuronowych, musisz przede wszystkim przeczytać dużo książek, artykułów i artykułów z wiadomościami. Ogólnie rzecz biorąc, wśród warunków wstępnych do studiowania pojęć sieci neuronowych istotną rolę odgrywa matematyka, aw szczególności statystyki, algebra liniowa, rachunek różniczkowy, prawdopodobieństwo. Oprócz tego niezbędne będą również umiejętności programowania komputerowego w językach takich jak Python, Java, R i C++. Bardzo pomocne mogą być tutaj umiejętności programowania na poziomie średniozaawansowanym.