
Éléments constitutifs des réseaux de neurones : les composants des réseaux de neurones expliqués
Publié: 2020-12-16Table des matières
introduction
Ces dernières années, la popularité de l'apprentissage en profondeur a pris une pente abrupte en termes d'utilisation et d'application dans tous les secteurs de l'industrie. Qu'il s'agisse de reconnaissance d'images, de génération de parole, de traduction et de bien d'autres applications similaires, presque toutes les entreprises souhaitent intégrer cette technologie dans l'un ou l'autre des produits qu'elles construisent. La raison de cette suprématie sur les algorithmes d'apprentissage automatique traditionnels est la précision et les performances efficaces fournies par ces modèles d'apprentissage en profondeur.
Bien que l'infrastructure joue un rôle important dans la fourniture de ces résultats, le code central effectue tout le traitement qui est enfermé dans un réseau de neurones. Explorons les différents composants de ce réseau, puis nous examinerons certaines unités fondamentales utilisant ces composants.
Doit lire : Introduction au modèle de réseau neuronal
Divers composants du réseau de neurones
Neurone
La pierre angulaire d'un réseau de neurones est un neurone. Ce concept est très similaire au réseau neuronal réel de notre cerveau humain. Ce neurone artificiel prend toutes les entrées, les agrège, puis sur la base d'une fonction donne la sortie du neurone.
Un réseau neuronal comprend de nombreux neurones de ce type interconnectés les uns aux autres sous la forme de couches appelées couches d'entrée, cachées et de sortie. Ce réseau nous permet de mapper n'importe quel type de modèle de données complexe à une fonction mathématique, et cela peut être vérifié mathématiquement à l'aide du théorème d'approximation universel.
Poids
Le modèle peut avoir des pondérations afin que les valeurs élevées puissent être supprimées à l'aide de valeurs négatives. Vous pouvez interpréter cela en prenant un exemple d'achat de smartphone. Plus le prix est élevé, plus les chances d'acheter ce smartphone sont faibles, mais si notre modèle additionne toutes les valeurs et les compare au seuil, la mauvaise prédiction peut être faite. Pour annuler cet effet, les poids négatifs doivent réduire la somme et obtenir la bonne prédiction.

Fonction d'activation
Il y avait une mention dans la définition du neurone selon laquelle, sur la base d'une fonction, le neurone enverra le résultat soit à la couche suivante s'il fait partie de la couche d'entrée ou cachée, soit utilisé pour un traitement ultérieur dans la couche de sortie.
Cette fonction s'appelle la fonction d'activation et définit l'état du neurone. Il existe de nombreuses fonctions d'activation disponibles sur le marché qui peuvent faire le travail, mais tout dépend du cas d'utilisation. Les exemples sont la fonction sigmoïde, la fonction tanh, la fonction softmax, Relu (unité linéaire rectifiée), Relu qui fuit et bien d'autres.
Taux d'apprentissage
Il peut contrôler le rythme de la mise à jour du poids. Considérons deux cas où le taux d'apprentissage agit comme un facteur important. Si une caractéristique d'entrée a des valeurs plus éparses, nous devons mettre à jour les pondérations plus fréquemment, et c'est pourquoi un taux d'apprentissage plus élevé est souhaité. De même, un faible taux d'apprentissage peut fonctionner dans des données denses.
Examinons quelques unités fondamentales utilisant ces composants dans des réseaux de neurones plus vastes.
Neurone MP
Il s'agit de la forme la plus élémentaire de neurone artificiel qui calcule la somme d'entrée, puis la transmet à la fonction d'activation pour obtenir la sortie finale. Voici un visuel de ceci :
Le facteur limitant est que les entrées doivent être binaires et qu'aucun nombre réel n'est autorisé. Cela signifie que si nous voulons utiliser un ensemble de données avec des valeurs différentes, cela doit être mis à l'échelle en binaire pour être transmis au modèle.
Les sorties de ce modèle sont également binaires, ce qui rend difficile l'interprétation de la qualité des résultats. Les entrées n'ont pas de poids, nous ne pouvons donc pas contrôler la contribution d'une fonctionnalité au résultat.
Neurone perceptron
L'un des inconvénients majeurs des neurones MP était qu'ils ne pouvaient pas accepter de nombres réels en entrée, ce qui pouvait conduire à des résultats indésirables. Cela signifie que si nous voulons transmettre une caractéristique d'entrée à ce neurone avec des nombres réels, il doit être réduit à 1 ou à 0. Dans ce modèle de neurone, il n'y a pas une telle limitation sur les entrées, mais le passage d'entrées standardisées donnera de meilleurs résultats en moins de temps car l'agrégation des entrées serait équitable pour toutes les valeurs de caractéristiques.
Un algorithme d'apprentissage est également introduit, ce qui rend ce modèle encore plus robuste aux nouvelles entrées. L'algorithme met à jour les pondérations appliquées à chaque entrée en fonction de la fonction de perte. La fonction de perte détermine la différence entre la valeur réelle et la valeur prédite par le modèle. La perte d'erreur quadratique est l'une de ces fonctions populaires utilisées dans les modèles d'apprentissage en profondeur.

Comme le neurone Perception émet également une sortie binaire, la perte peut être nulle ou un. Cela signifie que nous pouvons définir la fonction de perte de ce type de manière plus compacte comme "Lorsque la prédiction n'est pas égale à la vraie valeur, la perte est de un et les poids doivent être mis à jour sinon aucune perte et aucune mise à jour n'est nécessaire". Les mises à jour dans les poids se font de la manière suivante :
w = w + x si wx < 0
w = w – x si wx >= 0
Lire : Tutoriel de détection d'objets TensorFlow pour les débutants
Neurone sigmoïde
Le neurone perceptron semble prometteur par rapport au neurone MP, mais il reste encore quelques problèmes à résoudre. Un défaut majeur dans les deux est qu'ils ne prennent en charge que la classification binaire. Un autre problème est les limites de classification strictes qui indiquent uniquement si un cas particulier est possible. Il ne permet pas de flexibilité dans les prédictions sous forme de probabilités qui sont plus interprétables que les sorties binaires.
Pour résoudre tous ces problèmes, le neurone sigmoïde a été introduit, qui peut être utilisé pour la multi-classification et effectuer des tâches de régression. Ce modèle utilise la famille de fonctions sigmoïdes ou logarithmiques :
y = 1 / (1 + e^ (-wx + b))
Si nous traçons cette fonction, elle prendrait alors la forme en « S » où sa position peut être ajustée en utilisant différentes valeurs de « b », qui est l'ordonnée à l'origine de cette courbe. La sortie de cette fonction est toujours comprise entre 0 et 1, quel que soit le nombre d'entrées transmises. Cela donne la probabilité de la classe, qui est meilleure que les sorties rigides. Cela signifie également que nous pouvons avoir plusieurs classifications ou effectuer une régression.
L'algorithme d'apprentissage pour cela diffère des précédents. Ici, les poids et les biais sont mis à jour en fonction de la dérivée de la fonction de perte.
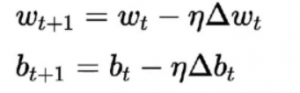
Cet algorithme est communément connu sous le nom de règle de descente de gradient. La dérivation et l'explication détaillée de ceci sont assez longues et mathématiques, elles sont donc actuellement hors de cet article. En termes simples, il indique que pour obtenir un minimum optimal pour la dérivée de la fonction de perte, nous devons nous déplacer dans une direction opposée au gradient.
Conclusion
Il s'agissait d'une brève introduction aux réseaux de neurones. Nous avons vu les différents composants de base tels que le neurone qui agit comme un mini-cerveau et traite les entrées, les poids qui permettent d'équilibrer les valeurs, le taux d'apprentissage pour contrôler le rythme de mise à jour des poids et la fonction d'activation pour activer les neurones.
Nous avons également vu comment le neurone de base peut prendre différentes formes en augmentant la complexité de la tâche. Nous avons commencé avec la forme la plus élémentaire du neurone MP, puis nous avons éliminé certains problèmes du neurone Perceptron, puis ajouté la prise en charge des tâches de régression et de classification multi-classes dans le neurone sigmoïde.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Qu'est-ce qu'un réseau de neurones en IA ?
Un réseau de neurones ou réseau de neurones artificiels (ANN) désigne un réseau informatique inspiré de la biologie, c'est-à-dire les réseaux de neurones présents dans le cerveau humain. Tout comme le cerveau humain est constitué de milliards de neurones qui forment un réseau interconnecté, le réseau de neurones artificiels comprend également des neurones interconnectés à différentes couches. Ces neurones sont également appelés nœuds dans le domaine de l'intelligence artificielle. Le concept de réseaux de neurones artificiels est développé pour conférer aux ordinateurs des capacités humaines à comprendre les choses et à prendre des décisions ; les nœuds ou ordinateurs ici sont programmés pour agir comme des cellules interconnectées de notre cerveau.
Quelles sont les compétences nécessaires pour obtenir un emploi dans l'IA ?
Étant donné que l'IA est un domaine hautement spécialisé de l'informatique, ceux qui aspirent à faire carrière dans l'IA doivent posséder certaines qualifications éducatives en plus de compétences telles que la pensée analytique, les capacités de conception et les capacités de résolution de problèmes. Les professionnels de l'IA très performants ont également la prévoyance des innovations technologiques qui permettent aux entreprises modernes de disposer de solutions logicielles rentables et efficaces nécessaires pour garder une longueur d'avance sur la concurrence. Inutile de dire que d'excellentes compétences en communication verbale et écrite sont indispensables. Une formation technique est nécessaire pour apprécier les perspectives logiques, techniques et technologiques des projets d'IA.
Quels sont les prérequis généraux pour apprendre les réseaux de neurones ?
Pour travailler sur un projet d'intelligence artificielle à grande échelle, il sera attendu de vous que vous ayez une compréhension claire des principes fondamentaux des réseaux de neurones artificiels. Pour construire vos concepts de base des réseaux de neurones, vous devez d'abord et avant tout lire de nombreux livres, articles et articles de presse. D'une manière générale, parmi les conditions préalables à l'étude des concepts de réseaux de neurones, les mathématiques jouent un rôle essentiel, en particulier des choses comme les statistiques, l'algèbre linéaire, le calcul, les probabilités. En dehors de cela, des compétences en programmation informatique dans des langages tels que Python, Java, R et C ++ seront également nécessaires. Des compétences intermédiaires en programmation peuvent également être d'une grande aide ici.