
Строительные блоки нейронных сетей: объяснение компонентов нейронных сетей
Опубликовано: 2020-12-16Оглавление
Введение
В последние годы популярность глубокого обучения резко упала с точки зрения использования и применения во всех секторах отрасли. Будь то распознавание изображений, генерация речи, перевод и многие другие подобные приложения, почти каждая компания хочет интегрировать эту технологию в тот или иной продукт, который они создают. Причиной такого превосходства над традиционными алгоритмами машинного обучения является точность и эффективность, обеспечиваемые этими моделями глубокого обучения.
Хотя инфраструктура играет важную роль в достижении этих результатов, основной код выполняет всю обработку, заключенную в нейронной сети. Давайте рассмотрим различные компоненты этой сети, а затем рассмотрим некоторые основные единицы, использующие эти компоненты.
Обязательно прочтите: Введение в модель нейронной сети
Различные компоненты нейронной сети
Нейрон
Основным строительным блоком нейронной сети является нейрон. Эта концепция очень похожа на настоящую нейронную сеть в нашем человеческом мозгу. Этот искусственный нейрон принимает все входные данные, агрегирует их, а затем на основе функции выдает выходные данные нейрона.
Нейронная сеть состоит из множества таких нейронов, связанных друг с другом в виде слоев, известных как входной, скрытый и выходной слои. Эта сеть позволяет нам сопоставить любой сложный шаблон данных с математической функцией, и это можно проверить математически, используя теорему универсального приближения.
Веса
Модель может иметь веса, чтобы высокие значения можно было подавить, используя отрицательные значения. Вы можете интерпретировать это на примере покупки смартфона. Чем выше цена, тем ниже вероятность покупки этого смартфона, но если наша модель сложит все значения и сравнит их с порогом, прогноз может быть неверным. Чтобы свести на нет этот эффект, отрицательные веса должны уменьшить сумму и получить правильный прогноз.

Функция активации
В определении нейрона упоминалось, что на основе функции нейрон выводит результат либо на следующий слой, если он является частью входного или скрытого слоя, либо используется для дальнейшей обработки в выходном слое.
Эта функция называется функцией активации, и она определяет состояние нейрона. На рынке доступно множество функций активации, которые могут выполнять эту работу, но все зависит от варианта использования. Примерами являются сигмовидная функция, функция tanh, функция softmax, Relu (выпрямленная линейная единица), дырявый Relu и многие другие.
Скорость обучения
Он может контролировать темп обновления веса. Рассмотрим два случая, когда скорость обучения выступает в качестве важного фактора. Если входная функция имеет более разреженные значения, нам нужно чаще обновлять веса, и поэтому желательна более высокая скорость обучения. Точно так же низкая скорость обучения может работать в плотных данных.
Давайте посмотрим на некоторые фундаментальные единицы, использующие эти компоненты в более крупных нейронных сетях.
МП Нейрон
Это самая основная форма искусственного нейрона, которая вычисляет входную сумму, а затем передает ее функции активации для получения окончательного результата. Вот визуальная часть этого:
Ограничивающим фактором для этого является то, что входные данные должны быть двоичными, а действительные числа не допускаются. Это означает, что если мы хотим использовать набор данных с другими значениями, то его необходимо масштабировать до двоичного, чтобы передать его в модель.
Выходы этой модели также являются бинарными, что затрудняет интерпретацию качества результатов. Входные данные не имеют весов, поэтому мы не можем контролировать, какой вклад функция будет иметь в результате.
Персептрон Нейрон
Одним из существенных недостатков МП-нейронов было то, что они не могут принимать на вход реальные числа, что может привести к нежелательным результатам. Это означает, что если мы хотим передать входную функцию этому нейрону с реальными числами, ее нужно уменьшить до 1 или 0. В этой нейронной модели такого ограничения на входные данные нет, но передача стандартизированных входных данных даст лучшие результаты за меньшее время, поскольку агрегация входных данных будет справедливой для всех значений признаков.
Также представлен алгоритм обучения, который делает эту модель еще более устойчивой к новым входным данным. Алгоритм обновляет веса, применяемые к каждому входу, на основе функции потерь. Функция потерь определяет разницу между фактическим значением и значением, предсказанным моделью. Потери в квадрате ошибки — одна из таких популярных функций, используемых в моделях глубокого обучения.

Поскольку нейрон восприятия также выдает двоичный вывод, потеря может быть равна нулю или единице. Это означает, что мы можем определить функцию потерь этого типа более компактно: «Когда прогноз не равен истинному значению, потеря равна единице, и веса необходимо обновить, иначе потери равны нулю и обновление не требуется». Обновление весов производится следующим образом:
w = w + x, если wx < 0
w = w – x, если wx >= 0
Читайте: Учебное пособие по обнаружению объектов TensorFlow для начинающих
Сигмовидный нейрон
Нейрон персептрона кажется многообещающим по сравнению с нейроном MP, но все еще есть некоторые проблемы, которые необходимо решить. Один из основных недостатков в обоих из них заключается в том, что они поддерживают только бинарную классификацию. Другой проблемой являются жесткие границы классификации, которые выводят только то, возможен ли конкретный случай. Он не допускает гибкости в прогнозах в виде вероятностей, которые более интерпретируемы, чем двоичные выходные данные.
Для решения всех этих проблем был введен сигмовидный нейрон, который можно использовать для мультиклассификации и выполнения задач регрессии. В этой модели используется семейство сигмовидных или логарифмических функций:
у = 1 / (1 + е ^ (-wx + b))
Если мы построим эту функцию, то она примет форму «S», где ее положение можно отрегулировать, используя различные значения «b», которые являются точкой пересечения этой кривой. Выход этой функции всегда находится между 0 и 1, независимо от того, сколько входных данных передано. Это дает вероятность класса, которая лучше, чем жесткие выходные данные. Это также означает, что мы можем иметь несколько классификаций или выполнять регрессию.
Алгоритм обучения для этого отличается от предыдущих. Здесь веса и смещение обновляются в соответствии с производной функции потерь.
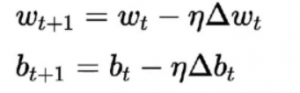
Этот алгоритм широко известен как правило градиентного спуска. Вывод и подробное объяснение этого довольно длинное и математическое, поэтому в настоящее время оно не входит в эту статью. Проще говоря, в нем говорится, что для получения оптимальных минимумов для производной функции потерь мы должны двигаться в направлении, противоположном градиенту.
Заключение
Это было краткое введение в нейронные сети. Мы видели различные базовые компоненты, такие как нейрон, который действует как мини-мозг и обрабатывает входные данные, веса, которые позволяют сбалансировать значения, скорость обучения, чтобы контролировать скорость обновления весов, и функцию активации, запускающую нейроны.
Мы также увидели, как основной нейрон-строительный блок может принимать различные формы при увеличении сложности задачи. Мы начали с самой простой формы в нейроне MP, затем устранили некоторые проблемы в нейроне Perceptron, а затем добавили поддержку задач регрессии и многоклассовой классификации в сигмовидном нейроне.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Что такое нейронная сеть в ИИ?
Нейронная сеть или искусственная нейронная сеть (ИНС) относится к вычислительной сети, вдохновленной биологией, т. е. к нейронным сетям, присутствующим в человеческом мозгу. Подобно тому, как человеческий мозг состоит из миллиардов нейронов, образующих взаимосвязанную сеть, искусственная нейронная сеть также состоит из нейронов, связанных между собой на разных уровнях. Эти нейроны также известны как узлы в области искусственного интеллекта. Концепция искусственных нейронных сетей разработана для того, чтобы наделить компьютеры человеческими способностями понимать вещи и принимать решения; узлы или компьютеры здесь запрограммированы действовать как взаимосвязанные клетки нашего мозга.
Какие навыки необходимы, чтобы получить работу в сфере ИИ?
Поскольку ИИ является узкоспециализированной областью компьютерных наук, те, кто стремится построить карьеру в области ИИ, должны обладать определенными образовательными ценностями, помимо таких навыков, как аналитическое мышление, способности к проектированию и способности решать проблемы. Успешные специалисты в области искусственного интеллекта также предвидят инновации в технологиях, которые позволяют современным предприятиям использовать экономичные и эффективные программные решения, необходимые для того, чтобы оставаться впереди конкурентов. Излишне говорить, что отличные устные и письменные коммуникативные навыки являются обязательными. Необходимо техническое образование, чтобы оценить логические, инженерные и технологические перспективы проектов ИИ.
Каковы общие предпосылки для изучения нейронных сетей?
Для работы над любым крупномасштабным проектом искусственного интеллекта от вас потребуется четкое понимание основ искусственных нейронных сетей. Чтобы построить свои базовые концепции нейронных сетей, прежде всего, вы должны прочитать достаточно книг, статей и новостных статей. Вообще говоря, среди предпосылок для изучения концепций нейронных сетей математика играет жизненно важную роль, особенно такие вещи, как статистика, линейная алгебра, исчисление, вероятность. Кроме того, также потребуются навыки компьютерного программирования на таких языках, как Python, Java, R и C++. Промежуточные навыки программирования также могут здесь очень помочь.