
Blok Bangunan Neural Network: Penjelasan Komponen Neural Network
Diterbitkan: 2020-12-16Daftar isi
pengantar
Dalam beberapa tahun terakhir, popularitas Deep learning telah menurun drastis dalam hal penggunaan dan aplikasi di setiap sektor industri. Baik itu pengenalan gambar, generasi ucapan, terjemahan, dan banyak lagi aplikasi semacam itu, hampir setiap perusahaan ingin mengintegrasikan teknologi ini ke dalam satu atau produk lain yang mereka buat. Alasan keunggulan atas algoritme pembelajaran mesin tradisional ini adalah akurasi dan kinerja efisien yang disediakan oleh model Pembelajaran Mendalam ini.
Meskipun infrastruktur memainkan peran penting dalam memberikan hasil ini, kode inti melakukan semua pemrosesan yang terlampir dalam Neural Network. Mari kita telusuri berbagai komponen jaringan ini dan kemudian kita akan melihat beberapa unit dasar menggunakan komponen ini.
Harus Dibaca: Pengenalan Model Neural Network
Berbagai Komponen Jaringan Syaraf
neuron
Blok bangunan dasar dari jaringan saraf adalah neuron. Konsep ini sangat mirip dengan jaringan saraf sebenarnya di otak manusia kita. Neuron buatan ini mengambil semua input, menggabungkannya, dan kemudian berdasarkan fungsi memberikan output neuron.
Jaringan saraf terdiri dari banyak neuron yang saling berhubungan satu sama lain dalam bentuk lapisan yang dikenal sebagai lapisan input, tersembunyi, dan output. Jaringan ini memungkinkan kita untuk memetakan segala jenis pola data kompleks ke fungsi matematika, dan ini dapat diverifikasi secara matematis menggunakan teorema aproksimasi universal.
Bobot
Model dapat memiliki bobot sehingga nilai tinggi dapat ditekan menggunakan nilai negatif. Hal ini dapat Anda artikan dengan mengambil contoh pembelian smartphone. Semakin tinggi harganya, semakin rendah peluang untuk membeli smartphone itu, tetapi jika model kami menjumlahkan semua nilai dan membandingkannya dengan ambang batas, prediksi yang salah mungkin dilakukan. Untuk meniadakan efek ini, bobot negatif harus mengurangi jumlah dan mendapatkan prediksi yang tepat.

Fungsi Aktivasi
Disebutkan dalam definisi neuron bahwa berdasarkan suatu fungsi, neuron akan mengeluarkan hasilnya baik ke lapisan berikutnya jika itu bagian dari lapisan input atau tersembunyi atau digunakan untuk pemrosesan lebih lanjut di lapisan output.
Fungsi ini disebut fungsi aktivasi, dan ini mendefinisikan keadaan neuron. Ada banyak fungsi aktivasi yang tersedia di pasar yang dapat melakukan pekerjaan itu tetapi semuanya tergantung pada kasus penggunaan. Contohnya adalah fungsi sigmoid, fungsi tanh, fungsi softmax, Relu (rectified linear unit), Relu bocor, dan masih banyak lagi.
Tingkat Pembelajaran
Itu dapat mengontrol kecepatan pembaruan berat. Pertimbangkan dua kasus di mana tingkat pembelajaran bertindak sebagai faktor penting. Jika fitur input memiliki nilai yang lebih jarang, maka kita perlu memperbarui bobot lebih sering, dan itulah mengapa tingkat pembelajaran yang lebih besar diinginkan. Demikian pula, tingkat pembelajaran yang rendah dapat bekerja dalam data yang padat.
Mari kita lihat beberapa unit dasar yang menggunakan komponen ini dalam jaringan saraf yang lebih besar.
MP Neuron
Ini adalah bentuk paling dasar dari Neuron Buatan yang menghitung jumlah input dan kemudian meneruskannya ke fungsi aktivasi untuk mendapatkan hasil akhir. Berikut adalah visualnya:
Faktor pembatas untuk ini adalah bahwa input harus biner dan tidak ada bilangan real yang diperbolehkan. Itu berarti jika kita ingin menggunakan dataset dengan nilai yang berbeda maka perlu diskalakan ke biner untuk diteruskan ke model.
Keluaran dari model ini juga biner, yang membuat sulit untuk menginterpretasikan kualitas hasil. Masukan tidak memiliki bobot, jadi kami tidak dapat mengontrol seberapa besar kontribusi fitur terhadap hasilnya.
Neuron Perceptron
Salah satu kelemahan yang signifikan dari neuron MP adalah tidak dapat menerima bilangan real sebagai input, yang dapat menyebabkan hasil yang tidak diinginkan. Artinya, jika kita ingin melewatkan fitur input ke neuron ini dengan bilangan real, perlu diturunkan ke 1 atau 0. Dalam model neuron ini, tidak ada batasan pada input, tetapi melewatkan input standar akan memberikan hasil yang lebih baik dalam waktu yang lebih singkat karena agregasi input akan adil untuk semua nilai fitur.
Sebuah algoritma pembelajaran juga diperkenalkan, yang membuat model ini lebih kuat untuk input baru. Algoritme memperbarui bobot yang diterapkan pada setiap input berdasarkan fungsi kerugian. Fungsi kerugian menentukan perbedaan antara nilai aktual dan nilai prediksi oleh model. Kehilangan kesalahan kuadrat adalah salah satu fungsi populer yang digunakan dalam model pembelajaran mendalam.

Karena neuron Persepsi juga memberikan keluaran biner, kerugiannya bisa nol atau satu. Ini berarti kita dapat mendefinisikan fungsi kerugian jenis ini dengan cara yang lebih ringkas sebagai "Ketika prediksi tidak sama dengan nilai sebenarnya, kerugiannya adalah satu dan bobot perlu diperbarui jika tidak, kerugian nol dan tidak diperlukan pembaruan". Pembaruan dalam bobot dilakukan dengan cara berikut:
w = w + x jika wx < 0
w = w – x jika wx >= 0
Baca: Tutorial Deteksi Objek TensorFlow Untuk Pemula
Neuron sigmoid
Neuron perceptron tampaknya menjanjikan dibandingkan dengan neuron MP, tetapi masih ada beberapa masalah yang perlu ditangani. Salah satu kelemahan utama di keduanya adalah bahwa mereka hanya mendukung klasifikasi biner. Masalah lainnya adalah batas klasifikasi yang keras yang hanya menampilkan apakah kasus tertentu mungkin terjadi. Itu tidak memungkinkan fleksibilitas dalam prediksi dalam bentuk probabilitas yang lebih dapat ditafsirkan daripada keluaran biner.
Untuk mengatasi semua masalah ini, neuron Sigmoid diperkenalkan, yang dapat digunakan untuk multi-klasifikasi dan melakukan tugas regresi. Model ini menggunakan keluarga fungsi sigmoid atau logaritma:
y = 1 / (1 + e^ (-wx + b))
Jika kita memplot fungsi ini maka akan mengambil bentuk 'S' dimana posisinya dapat diatur dengan menggunakan nilai 'b' yang berbeda yang merupakan titik potong dari kurva ini. Output dari fungsi ini selalu terletak antara 0 dan 1, tidak peduli berapa banyak input yang dilewatkan. Ini memberikan probabilitas kelas, yang lebih baik daripada keluaran kaku. Ini juga berarti kita dapat memiliki beberapa klasifikasi atau melakukan regresi.
Algoritma pembelajaran untuk ini berbeda dari yang sebelumnya. Di sini bobot dan bias diperbarui sesuai dengan turunan dari fungsi kerugian.
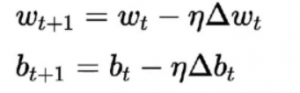
Algoritma ini umumnya dikenal sebagai aturan Gradient Descent. Derivasi dan penjelasan rinci untuk ini cukup panjang dan matematis, oleh karena itu saat ini keluar dari artikel ini. Secara sederhana, ini menyatakan bahwa untuk mendapatkan minimum optimal untuk turunan dari fungsi kerugian, kita harus bergerak ke arah yang berlawanan dengan gradien.
Kesimpulan
Ini adalah pengantar singkat untuk Neural Networks. Kami melihat berbagai komponen dasar seperti neuron yang bertindak sebagai otak mini dan memproses input, bobot yang memungkinkan untuk menyeimbangkan nilai, tingkat pembelajaran untuk mengontrol bagaimana kecepatan pembaruan bobot dan fungsi aktivasi untuk mengaktifkan neuron.
Kami juga melihat bagaimana neuron blok bangunan dasar dapat mengambil bentuk yang berbeda dalam meningkatkan kompleksitas tugas. Kami mulai dengan bentuk paling dasar di neuron MP, kemudian menghilangkan beberapa masalah di neuron Perceptron, dan kemudian menambahkan dukungan untuk regresi dan tugas klasifikasi multi-kelas di neuron sigmoid.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa itu jaringan saraf di AI?
Jaringan saraf atau jaringan saraf tiruan (JST) mengacu pada jaringan komputasi yang terinspirasi oleh biologi, yaitu jaringan saraf yang ada di otak manusia. Sama seperti otak manusia yang terdiri dari miliaran neuron yang membentuk jaringan yang saling berhubungan, jaringan saraf tiruan juga terdiri dari neuron yang saling berhubungan pada berbagai lapisan. Neuron ini juga dikenal sebagai node dalam bidang kecerdasan buatan. Konsep jaringan saraf tiruan dikembangkan untuk memberikan komputer kemampuan seperti manusia untuk memahami berbagai hal dan membuat keputusan; node atau komputer di sini diprogram untuk bertindak seperti sel-sel otak kita yang saling berhubungan.
Keterampilan apa yang dibutuhkan untuk mendapatkan pekerjaan di AI?
Karena AI adalah bidang ilmu komputer yang sangat terspesialisasi, mereka yang bercita-cita untuk membangun karir di AI harus memiliki kualifikasi pendidikan tertentu selain keterampilan seperti pemikiran analitis, kemampuan desain, dan kemampuan memecahkan masalah. Profesional AI yang sangat sukses juga memiliki pandangan ke depan terhadap inovasi dalam teknologi yang memungkinkan bisnis modern dengan solusi perangkat lunak yang hemat biaya dan efisien yang diperlukan untuk tetap menjadi yang terdepan dalam persaingan. Tak perlu dikatakan, keterampilan komunikasi verbal dan tertulis yang sangat baik adalah suatu keharusan. Latar belakang pendidikan teknis diperlukan untuk menghargai perspektif logis, teknik, dan teknologi proyek AI.
Apa prasyarat umum untuk mempelajari jaringan saraf?
Untuk mengerjakan proyek kecerdasan buatan skala besar, Anda diharapkan memiliki pemahaman yang jelas tentang dasar-dasar jaringan saraf tiruan. Untuk membangun konsep dasar jaringan saraf Anda, pertama dan terpenting, Anda harus membaca banyak buku, artikel, dan artikel berita. Secara umum, di antara prasyarat untuk mempelajari konsep jaringan saraf, matematika memainkan peran penting, terutama, hal-hal seperti statistik, aljabar linier, kalkulus, probabilitas. Selain itu, keterampilan pemrograman komputer dalam bahasa seperti Python, Java, R, dan C++, juga akan diperlukan. Keterampilan pemrograman tingkat menengah juga dapat sangat membantu di sini.