
Elementos básicos de las redes neuronales: explicación de los componentes de las redes neuronales
Publicado: 2020-12-16Tabla de contenido
Introducción
En los últimos años, la popularidad del aprendizaje profundo ha tomado una pendiente abrupta en términos de uso y aplicación en todos los sectores de la industria. Ya sea que se trate de reconocimiento de imágenes, generación de voz, traducción y muchas más aplicaciones similares, casi todas las empresas quieren integrar esta tecnología en uno u otro de los productos que están construyendo. El motivo de esta supremacía sobre los algoritmos tradicionales de aprendizaje automático es la precisión y el rendimiento eficiente que ofrecen estos modelos de aprendizaje profundo.
Aunque la infraestructura juega un papel importante en la entrega de estos resultados, el código central hace todo el procesamiento que está encerrado en una red neuronal. Exploremos los diversos componentes de esta red y luego veremos algunas unidades fundamentales que utilizan estos componentes.
Debe leer: Introducción al modelo de red neuronal
Varios componentes de la red neuronal
Neurona
El componente básico de una red neuronal es una neurona. Este concepto es muy similar a la red neuronal real en nuestros cerebros humanos. Esta neurona artificial toma todas las entradas, las agrega y luego, en función de una función, proporciona la salida de la neurona.
Una red neuronal comprende muchas de estas neuronas interconectadas entre sí en forma de capas conocidas como capas de entrada, ocultas y de salida. Esta red nos permite mapear cualquier tipo de patrón de datos complejos a una función matemática, y esto se puede verificar matemáticamente usando el teorema de aproximación universal.
Pesos
El modelo puede tener pesos para que los valores altos se puedan suprimir usando valores negativos. Puede interpretar esto tomando un ejemplo de la compra de un teléfono inteligente. Cuanto mayor sea el precio, menores serán las posibilidades de comprar ese teléfono inteligente, pero si nuestro modelo suma todos los valores y lo compara con el umbral, es posible que se haga una predicción incorrecta. Para anular este efecto, los pesos negativos deberían reducir la suma y obtener la predicción correcta.

Función de activación
Hubo una mención en la definición de neurona que, según una función, la neurona enviará el resultado a la siguiente capa si es parte de la capa de entrada u oculta o si se usa para un procesamiento posterior en la capa de salida.
Esta función se denomina función de activación y define el estado de la neurona. Hay muchas funciones de activación disponibles en el mercado que pueden hacer el trabajo, pero todo depende del caso de uso. Algunos ejemplos son la función sigmoidea, la función tanh, la función softmax, Relu (unidad lineal rectificada), Relu con fugas y muchas más.
Tasa de aprendizaje
Puede controlar el ritmo de la actualización del peso. Considere dos casos en los que la tasa de aprendizaje actúa como un factor importante. Si una característica de entrada tiene valores más dispersos, entonces necesitamos actualizar los pesos con más frecuencia y es por eso que se desea una mayor tasa de aprendizaje. De manera similar, una tasa de aprendizaje baja puede funcionar en datos densos.
Veamos algunas unidades fundamentales que hacen uso de estos componentes en redes neuronales más grandes.
MP neurona
Esta es la forma más básica de Neurona Artificial que calcula la suma de entrada y luego la pasa a la función de activación para obtener la salida final. Aquí hay una imagen de esto:
El factor limitante de esto es que las entradas deben ser binarias y no se permite ningún número real. Eso significa que si queremos usar un conjunto de datos con diferentes valores, entonces debe escalarse a binario para pasarlo al modelo.
Los resultados de este modelo también son binarios, lo que dificulta la interpretación de la calidad de los resultados. Las entradas no tienen ningún peso, por lo que no podemos controlar cuánta contribución tendrá una característica al resultado.
Neurona perceptrón
Uno de los inconvenientes importantes de las neuronas MP es que no puede aceptar números reales como entradas, lo que puede generar resultados no deseados. Significa que si queremos pasar una función de entrada a esta neurona con números reales, debe reducirse a 1 o 0. En este modelo de neuronas, no existe tal limitación en las entradas, pero pasar las entradas estandarizadas dará mejores resultados en menos tiempo, ya que la agregación de entradas sería justa para todos los valores de características.
También se introduce un algoritmo de aprendizaje, lo que hace que este modelo sea aún más robusto para las nuevas entradas. El algoritmo actualiza los pesos aplicados a cada entrada en función de la función de pérdida. La función de pérdida determina la diferencia entre el valor real y el valor predicho por el modelo. La pérdida de error cuadrático es una de esas funciones populares que se utilizan en los modelos de aprendizaje profundo.

Como la neurona de percepción también emite una salida binaria, la pérdida puede ser cero o uno. Significa que podemos definir la función de pérdida de este tipo de una manera más compacta como "Cuando la predicción no es igual al valor real, la pérdida es uno y los pesos deben actualizarse; de lo contrario, la pérdida es cero y no se necesita actualización". Las actualizaciones en los pesos se realizan de la siguiente manera:
w = w + x si wx < 0
w = w – x si wx >= 0
Leer: Tutorial de detección de objetos de TensorFlow para principiantes
Neurona sigmoidea
La neurona perceptrón parece prometedora en comparación con la neurona MP, pero todavía hay algunos problemas que deben abordarse. Un defecto importante en ambos es que solo admiten la clasificación binaria. Otro problema son los estrictos límites de clasificación que solo muestran si un caso particular es posible. No permite flexibilidad en las predicciones en forma de probabilidades que son más interpretables que las salidas binarias.
Para resolver todos estos problemas, se introdujo la neurona sigmoidea, que se puede utilizar para tareas de clasificación múltiple y regresión. Este modelo utiliza la familia de funciones sigmoideas o logarítmicas:
y = 1 / (1 + e^ (-wx + b))
Si trazamos esta función, tomaría la forma de 'S' donde su posición se puede ajustar usando diferentes valores de 'b', que es la intersección de esta curva. La salida de esta función siempre se encuentra entre 0 y 1, sin importar cuántas entradas se pasen. Esto da la probabilidad de la clase, que es mejor que las salidas rígidas. Esto también significa que podemos tener múltiples clasificaciones o realizar una regresión.
El algoritmo de aprendizaje para esto difiere de los anteriores. Aquí los pesos y sesgos se actualizan de acuerdo con la derivada de la función de pérdida.
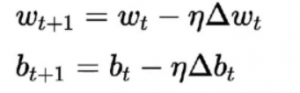
Este algoritmo se conoce comúnmente como la regla de descenso de gradiente. La derivación y la explicación detallada de esto es bastante larga y matemática, por lo que actualmente está fuera de este artículo. En términos simples, establece que para obtener un mínimo óptimo para la derivada de la función de pérdida, debemos movernos en dirección opuesta al gradiente.
Conclusión
Esta fue una breve introducción a las redes neuronales. Vimos los diversos componentes básicos, como la neurona que actúa como un mini-cerebro y procesa las entradas, los pesos que permiten equilibrar los valores, la tasa de aprendizaje para controlar cómo se actualiza el ritmo de los pesos y la función de activación para encender las neuronas.
También vimos cómo la neurona básica del bloque de construcción puede tomar diferentes formas al aumentar la complejidad de la tarea. Comenzamos con la forma más básica en la neurona MP, luego eliminamos algunos problemas en la neurona Perceptron y luego agregamos soporte para tareas de regresión y clasificación multiclase en la neurona sigmoidea.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Qué es una red neuronal en IA?
Una red neuronal o red neuronal artificial (ANN) se refiere a una red computacional inspirada en la biología, es decir, las redes neuronales presentes en el cerebro humano. Al igual que el cerebro humano consta de miles de millones de neuronas que forman una red interconectada, la red neuronal artificial también comprende neuronas que están interconectadas en varias capas. Estas neuronas también se conocen como nodos en el ámbito de la inteligencia artificial. El concepto de redes neuronales artificiales se desarrolla para impartir a las computadoras habilidades similares a las humanas para comprender cosas y tomar decisiones; los nodos o computadoras aquí están programados para actuar como células interconectadas de nuestro cerebro.
¿Qué habilidades se necesitan para conseguir un trabajo en IA?
Dado que la IA es un campo altamente especializado de la informática, aquellos que aspiran a desarrollar una carrera en IA deben poseer ciertas calificaciones educativas además de habilidades como pensamiento analítico, habilidades de diseño y capacidades de resolución de problemas. Los profesionales de IA altamente exitosos también tienen la visión de las innovaciones en tecnología que permiten a las empresas modernas las soluciones de software rentables y eficientes necesarias para mantenerse por delante de la competencia. No hace falta decir que se requieren excelentes habilidades de comunicación verbal y escrita. Se necesita una formación técnica para apreciar las perspectivas lógicas, de ingeniería y tecnológicas de los proyectos de IA.
¿Cuáles son los requisitos previos generales para aprender redes neuronales?
Para trabajar en cualquier proyecto de inteligencia artificial a gran escala, se espera que tenga una comprensión clara de los fundamentos de las redes neuronales artificiales. Para construir sus conceptos básicos de redes neuronales, primero y ante todo, debe leer muchos libros, artículos y artículos de noticias. En términos generales, entre los requisitos previos para estudiar los conceptos de redes neuronales, las matemáticas juegan un papel vital, especialmente, cosas como estadística, álgebra lineal, cálculo, probabilidad. Aparte de eso, también serán necesarias habilidades de programación informática en lenguajes como Python, Java, R y C ++. Las habilidades de programación intermedias también pueden ser de gran ayuda aquí.