
Blocuri de construcție ale rețelelor neuronale: Componentele rețelelor neuronale explicate
Publicat: 2020-12-16Cuprins
Introducere
În ultimii ani, popularitatea învățării profunde a luat o pantă bruscă în ceea ce privește utilizarea și aplicarea în fiecare sector al industriei. Fie că este vorba despre recunoașterea imaginilor, generarea vorbirii, traducerea și multe alte astfel de aplicații, aproape fiecare companie dorește să integreze această tehnologie într-unul sau în celelalte produse pe care le construiesc. Motivul acestei supremații față de algoritmii tradiționali de învățare automată este acuratețea și performanța eficientă oferite de aceste modele de învățare profundă.
Deși infrastructura joacă un rol important în furnizarea acestor rezultate, codul de bază face toată procesarea care este inclusă într-o rețea neuronală. Să explorăm diferitele componente ale acestei rețele și apoi ne vom uita la câteva unități fundamentale care folosesc aceste componente.
Trebuie citit: Introducere model de rețea neuronală
Diverse componente ale rețelei neuronale
Neuron
Elementul de bază al unei rețele neuronale este un neuron. Acest concept este foarte asemănător cu rețeaua neuronală actuală din creierul nostru uman. Acest neuron artificial preia toate intrările, le agregează și apoi, pe baza unei funcții, dă ieșirea neuronului.
O rețea neuronală cuprinde mulți astfel de neuroni interconectați între ei sub formă de straturi cunoscute sub numele de straturile de intrare, ascunse și de ieșire. Această rețea ne permite să mapam orice tip de model complex de date la o funcție matematică, iar acest lucru poate fi verificat matematic folosind teorema de aproximare universală.
Greutăți
Modelul poate avea ponderi astfel încât valorile mari să poată fi suprimate folosind valori negative. Puteți interpreta acest lucru luând un exemplu de achiziție a unui smartphone. Cu cât prețul este mai mare, cu atât vor fi mai mici șansele de a cumpăra acel smartphone, dar dacă modelul nostru adună toate valorile și îl compară cu pragul, se poate face o predicție greșită. Pentru a anula acest efect, ponderile negative ar trebui să reducă suma și să obțină predicția corectă.

Funcția de activare
A existat o mențiune în definiția neuronului că, pe baza unei funcții, neuronul va scoate rezultatul fie la stratul următor, dacă face parte din stratul de intrare sau ascuns, fie utilizat pentru procesarea ulterioară în stratul de ieșire.
Această funcție se numește funcția de activare și aceasta definește starea neuronului. Există o mulțime de funcții de activare disponibile pe piață care pot face treaba, dar totul depinde de cazul de utilizare. Exemple sunt funcția sigmoidă, funcția tanh, funcția softmax, Relu (unitate liniară rectificată), Relu leaky și multe altele.
Rata de învățare
Poate controla ritmul actualizării greutății. Luați în considerare două cazuri în care rata de învățare acționează ca un factor important. Dacă o caracteristică de intrare are valori mai rare, atunci trebuie să actualizăm ponderile mai frecvent și de aceea se dorește o rată de învățare mai mare. În mod similar, o rată scăzută de învățare poate funcționa în date dense.
Să ne uităm la câteva unități fundamentale care folosesc aceste componente în rețele neuronale mai mari.
MP Neuron
Aceasta este cea mai de bază formă de neuron artificial care calculează suma de intrare și apoi o trece la funcția de activare pentru a obține rezultatul final. Iată o imagine a acestui lucru:
Factorul limitativ este că intrările ar trebui să fie binare și nu este permis niciun număr real. Asta înseamnă că dacă dorim să folosim un set de date cu valori diferite, atunci acesta trebuie scalat la binar pentru a fi transmis modelului.
Rezultatele acestui model sunt, de asemenea, binare, ceea ce face dificilă interpretarea calității rezultatelor. Intrările nu au nicio pondere, așa că nu putem controla cât de multă contribuție va avea o caracteristică la rezultat.
Neuronul perceptron
Unul dintre dezavantajele semnificative ale neuronilor MP a fost că nu poate accepta numere reale ca intrări, ceea ce poate duce la rezultate nedorite. Înseamnă că, dacă vrem să transmitem o caracteristică de intrare acestui neuron cu numere reale, aceasta trebuie redusă la 1 sau 0. În acest model de neuroni, nu există o astfel de limitare a intrărilor, dar trecerea intrărilor standardizate va da rezultate mai bune în mai puțin timp, deoarece agregarea intrărilor ar fi corectă pentru toate valorile caracteristicilor.
Este introdus și un algoritm de învățare, ceea ce face acest model și mai robust la noile intrări. Algoritmul actualizează ponderile aplicate fiecărei intrări pe baza funcției de pierdere. Funcția de pierdere determină diferența dintre valoarea reală și valoarea prezisă de model. Pierderea erorilor pătrate este una dintre aceste funcții populare utilizate în modelele de învățare profundă.

Deoarece neuronul de percepție dă și ieșire binară, pierderea poate fi zero sau unu. Înseamnă că putem defini funcția de pierdere de acest tip într-un mod mai compact ca „Atunci când predicția nu este egală cu valoarea adevărată, pierderea este una și greutățile trebuie actualizate altfel pierdere zero și nu este nevoie de actualizare”. Actualizările ponderilor se fac în felul următor:
w = w + x dacă wx < 0
w = w – x dacă wx >= 0
Citiți: Tutorial de detectare a obiectelor TensorFlow pentru începători
Neuronul sigmoid
Neuronul perceptron pare promițător în comparație cu neuronul MP, dar există încă unele probleme care trebuie abordate. Un defect major în ambele este că acceptă doar clasificarea binară. O altă problemă este limitele dure de clasificare care indică doar dacă un anumit caz este posibil. Nu permite flexibilitate în predicții sub formă de probabilități care sunt mai interpretabile decât ieșirile binare.
Pentru a rezolva toate aceste probleme, a fost introdus neuronul sigmoid, care poate fi folosit pentru multi-clasificare și efectuarea sarcinilor de regresie. Acest model folosește familia sigmoidă de funcții sau logaritmice:
y = 1 / (1 + e^ (-wx + b))
Dacă trasăm această funcție, atunci ar lua forma „S” unde poziția sa poate fi ajustată folosind diferite valori ale lui „b”, care este interceptarea acestei curbe. Ieșirea acestei funcții se află întotdeauna între 0 și 1, indiferent de câte intrări sunt transmise. Acest lucru oferă probabilitatea clasei, care este mai bună decât ieșirile rigide. Aceasta înseamnă, de asemenea, că putem avea mai multe clasificări sau putem efectua regresii.
Algoritmul de învățare pentru aceasta diferă de cele anterioare. Aici ponderile și părtinirea sunt actualizate în funcție de derivata funcției de pierdere.
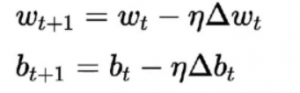
Acest algoritm este cunoscut în mod obișnuit ca regula de coborâre a gradientului. Derivarea și explicația detaliată pentru aceasta este destul de lungă și matematică, prin urmare nu este în prezent din acest articol. În termeni simpli, se afirmă că pentru a obține minime optime pentru derivata funcției de pierdere, ar trebui să ne deplasăm într-o direcție opusă gradientului.
Concluzie
Aceasta a fost o scurtă introducere în rețelele neuronale. Am văzut diferitele componente de bază, cum ar fi neuronul care acționează ca un mini-creier și procesează intrările, greutăți care permit echilibrarea valorilor, rata de învățare pentru a controla modul în care ritmul greutăților se actualizează și funcția de activare pentru a activa neuronii.
Am văzut, de asemenea, modul în care neuronul de bază poate lua diferite forme la creșterea complexității sarcinii. Am început cu cea mai de bază formă din neuronul MP, apoi eliminăm unele probleme în neuronul Perceptron, iar mai târziu adăugând suport pentru sarcini de regresie și clasificare multi-clasă în neuronul sigmoid.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Ce este o rețea neuronală în AI?
O rețea neuronală sau rețea neuronală artificială (ANN) se referă la o rețea de calcul inspirată din biologie, adică rețelele neuronale prezente în creierul uman. La fel cum creierul uman este format din miliarde de neuroni care formează o rețea interconectată, rețeaua neuronală artificială cuprinde și neuroni care sunt interconectați la diferite straturi. Acești neuroni sunt cunoscuți și ca noduri în domeniul inteligenței artificiale. Conceptul de rețele neuronale artificiale este dezvoltat pentru a conferi computerelor abilități asemănătoare oamenilor de a înțelege lucrurile și de a lua decizii; nodurile sau computerele de aici sunt programate să acționeze ca niște celule interconectate ale creierului nostru.
Ce abilități sunt necesare pentru a obține un loc de muncă în AI?
Deoarece AI este un domeniu foarte specializat al informaticii, cei care aspiră să-și construiască o carieră în AI trebuie să posede anumite calificări educaționale, în afară de abilități precum gândirea analitică, abilitățile de proiectare și abilitățile de rezolvare a problemelor. Profesioniștii AI de mare succes au, de asemenea, previziunea inovațiilor în tehnologie care permit companiilor moderne să dispună de soluții software rentabile și eficiente necesare pentru a rămâne în fruntea concurenței. Inutil să spun că abilitățile excelente de comunicare verbală și scrisă sunt o necesitate. O pregătire tehnică este necesară pentru a aprecia perspectivele logice, inginerești și tehnologice ale proiectelor AI.
Care sunt premisele generale pentru învățarea rețelelor neuronale?
Pentru a lucra la orice proiect de inteligență artificială la scară largă, este de așteptat să aveți o înțelegere clară a fundamentelor rețelelor neuronale artificiale. Pentru a vă construi conceptele de bază despre rețelele neuronale, în primul rând, trebuie să citiți ample cărți, articole și articole de știri. În general, printre premisele studierii conceptelor de rețele neuronale, matematica joacă un rol vital, mai ales lucruri precum statistica, algebra liniară, calculul, probabilitatea. În afară de aceasta, vor fi necesare și abilități de programare în limbaje precum Python, Java, R și C++. Abilitățile de programare intermediare pot fi, de asemenea, de mare ajutor aici.