
Blocos de construção de redes neurais: componentes de redes neurais explicados
Publicados: 2020-12-16Índice
Introdução
Nos últimos anos, a popularidade do Deep Learning teve uma queda abrupta em termos de uso e aplicação em todos os setores da indústria. Seja reconhecimento de imagem, geração de fala, tradução e muitos outros aplicativos, quase todas as empresas desejam integrar essa tecnologia em um ou outro produto que estão construindo. O motivo dessa supremacia sobre os algoritmos tradicionais de aprendizado de máquina é a precisão e o desempenho eficiente fornecidos por esses modelos de Deep Learning.
Embora a infraestrutura desempenhe um papel importante na entrega desses resultados, o código central faz todo o processamento que está contido em uma rede neural. Vamos explorar os vários componentes dessa rede e, em seguida, veremos algumas unidades fundamentais usando esses componentes.
Deve ler: Introdução ao modelo de rede neural
Vários componentes da rede neural
Neurônio
O bloco de construção básico de uma rede neural é um neurônio. Este conceito é muito semelhante à rede neural real em nossos cérebros humanos. Esse neurônio artificial pega todas as entradas, agrega-as e, em seguida, com base em uma função, fornece a saída do neurônio.
Uma rede neural compreende muitos desses neurônios interconectados entre si na forma de camadas conhecidas como camadas de entrada, ocultas e de saída. Essa rede nos permite mapear qualquer tipo de padrão de dados complexo para uma função matemática, e isso pode ser verificado matematicamente usando o teorema da aproximação universal.
Pesos
O modelo pode ter pesos para que valores altos possam ser suprimidos usando valores negativos. Você pode interpretar isso tomando um exemplo de compra de um smartphone. Quanto maior o preço, menores serão as chances de adquirir aquele smartphone, mas se nosso modelo somar todos os valores e comparar com o limite, a previsão errada pode ser feita. Para anular esse efeito, os pesos negativos devem reduzir a soma e obter a previsão correta.

Função de ativação
Houve uma menção na definição do neurônio que, com base em uma função, o neurônio enviará o resultado para a próxima camada se for parte da camada de entrada ou oculta ou usado para processamento adicional na camada de saída.
Essa função é chamada de função de ativação e define o estado do neurônio. Existem muitas funções de ativação disponíveis no mercado que podem fazer o trabalho, mas tudo depende do caso de uso. Exemplos são a função sigmoid, a função tanh, a função softmax, Relu (unidade linear retificada), Relu com vazamento e muito mais.
Taxa de Aprendizagem
Ele pode controlar o ritmo da atualização de peso. Considere dois casos em que a taxa de aprendizado atua como um fator importante. Se um recurso de entrada tiver mais valores esparsos, precisamos atualizar os pesos com mais frequência, e é por isso que uma taxa de aprendizado maior é desejada. Da mesma forma, uma baixa taxa de aprendizado pode funcionar em dados densos.
Vejamos algumas unidades fundamentais que fazem uso desses componentes em redes neurais maiores.
Neurônio MP
Esta é a forma mais básica de Neurônio Artificial que calcula a soma de entrada e depois a passa para a função de ativação para obter a saída final. Aqui está um visual disso:
O fator limitante para isso é que as entradas devem ser binárias e nenhum número real é permitido. Isso significa que, se quisermos usar um conjunto de dados com valores diferentes, ele precisa ser dimensionado para binário para ser passado para o modelo.
As saídas deste modelo também são binárias, o que dificulta a interpretação da qualidade dos resultados. As entradas não têm pesos, então não podemos controlar quanta contribuição um recurso terá para o resultado.
Neurônio Perceptron
Uma das desvantagens significativas dos neurônios MP é que eles não podem aceitar números reais como entradas, o que pode levar a resultados indesejáveis. Isso significa que, se quisermos passar um recurso de entrada para esse neurônio com números reais, ele precisa ser reduzido para 1 ou 0. Neste modelo de neurônio, não há tal limitação nas entradas, mas passar entradas padronizadas dará melhores resultados em menos tempo, pois a agregação de entradas seria justa para todos os valores de recursos.
Um algoritmo de aprendizado também é introduzido, o que torna este modelo ainda mais robusto para novas entradas. O algoritmo atualiza os pesos aplicados a cada entrada com base na função de perda. A função de perda determina a diferença entre o valor real e o valor previsto pelo modelo. A perda de erro ao quadrado é uma dessas funções populares usadas em modelos de aprendizado profundo.

Como o neurônio de percepção também fornece saída binária, a perda pode ser zero ou um. Isso significa que podemos definir a função de perda desse tipo de forma mais compacta como “Quando a previsão não é igual ao valor real, a perda é um e os pesos precisam ser atualizados, senão a perda zero e nenhuma atualização necessária”. As atualizações nos pesos são feitas da seguinte forma:
w = w + x se wx < 0
w = w – x se wx >= 0
Leia: Tutorial de detecção de objetos do TensorFlow para iniciantes
Neurônio sigmóide
O neurônio perceptron parece promissor em comparação com o neurônio MP, mas ainda existem algumas questões que precisam ser abordadas. Uma grande falha em ambos é que eles suportam apenas a classificação binária. Outra questão são os limites rígidos de classificação que apenas mostram se um caso específico é possível. Ele não permite flexibilidade nas previsões na forma de probabilidades que são mais interpretáveis do que saídas binárias.
Para resolver todos esses problemas, foi introduzido o neurônio Sigmoid, que pode ser usado para multiclassificação e tarefas de regressão. Este modelo usa a família de funções sigmoid ou logarítmica:
y = 1 / (1 + e^ (-wx + b))
Se plotarmos essa função, ela assumirá a forma de 'S', onde sua posição pode ser ajustada usando diferentes valores de 'b', que é a interceptação dessa curva. A saída desta função sempre fica entre 0 e 1, não importa quantas entradas sejam passadas. Isso fornece a probabilidade da classe, que é melhor do que as saídas rígidas. Isso também significa que podemos ter várias classificações ou realizar regressão.
O algoritmo de aprendizado para isso difere dos anteriores. Aqui os pesos e viés são atualizados de acordo com a derivada da função de perda.
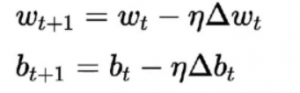
Esse algoritmo é comumente conhecido como regra de descida do gradiente. A derivação e explicação detalhada para isso é bastante longa e matemática, portanto, atualmente está fora deste artigo. Em termos simples, ele afirma que para obter um mínimo ótimo para a derivada da função de perda, devemos nos mover na direção oposta ao gradiente.
Conclusão
Esta foi uma breve introdução às Redes Neurais. Vimos os vários componentes básicos, como o neurônio que atua como um minicérebro e processa as entradas, pesos que permitem equilibrar valores, taxa de aprendizado para controlar como o ritmo dos pesos se atualiza e a função de ativação para acionar os neurônios.
Também vimos como o neurônio básico do bloco de construção pode assumir diferentes formas ao aumentar a complexidade da tarefa. Começamos com a forma mais básica no neurônio MP, eliminando alguns problemas no neurônio Perceptron e, posteriormente, adicionando suporte para tarefas de regressão e classificação multiclasse no neurônio sigmóide.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
O que é uma rede neural em IA?
Uma rede neural ou rede neural artificial (RNA) refere-se a uma rede computacional inspirada na biologia, ou seja, as redes neurais presentes no cérebro humano. Assim como o cérebro humano consiste em bilhões de neurônios que formam uma rede interconectada, a rede neural artificial também compreende neurônios que estão interconectados em várias camadas. Esses neurônios também são conhecidos como nós no reino da inteligência artificial. O conceito de redes neurais artificiais é desenvolvido para transmitir aos computadores habilidades humanas para compreender coisas e tomar decisões; os nós ou computadores aqui são programados para agir como células interconectadas do nosso cérebro.
Quais habilidades são necessárias para conseguir um emprego em IA?
Como a IA é um campo altamente especializado da ciência da computação, aqueles que desejam construir uma carreira em IA devem possuir certas qualificações educacionais, além de habilidades como pensamento analítico, habilidades de design e recursos de resolução de problemas. Profissionais de IA altamente bem-sucedidos também têm a visão de inovações em tecnologia que permitem às empresas modernas soluções de software econômicas e eficientes necessárias para se manter à frente da concorrência. Escusado será dizer que excelentes habilidades de comunicação verbal e escrita são uma obrigação. Uma formação técnica educacional é necessária para apreciar as perspectivas lógicas, de engenharia e tecnológicas dos projetos de IA.
Quais são os pré-requisitos gerais para aprender redes neurais?
Para trabalhar em qualquer projeto de inteligência artificial em larga escala, espera-se que você tenha uma compreensão clara dos fundamentos das redes neurais artificiais. Para construir seus conceitos básicos de redes neurais, em primeiro lugar, você deve ler amplos livros, artigos e artigos de notícias. De um modo geral, entre os pré-requisitos para estudar os conceitos de redes neurais, a matemática desempenha um papel vital, especialmente, coisas como estatística, álgebra linear, cálculo, probabilidade. Além disso, habilidades de programação de computadores em linguagens como Python, Java, R e C++ também serão necessárias. Habilidades de programação intermediárias também podem ser de grande ajuda aqui.