
神经网络的构建块:解释神经网络的组件
已发表: 2020-12-16目录
介绍
近年来,深度学习的普及在行业各个领域的使用和应用方面都出现了急剧下降。 无论是图像识别、语音生成、翻译以及更多此类应用,几乎每家公司都希望将这项技术集成到他们正在构建的一个或其他产品中。 这种超越传统机器学习算法的优势的原因是这些深度学习模型提供的准确性和高效性能。
尽管基础设施在提供这些结果方面发挥着重要作用,但核心代码完成了包含在神经网络中的所有处理。 让我们探索这个网络的各种组件,然后我们将看看使用这些组件的一些基本单元。
必读:神经网络模型介绍
神经网络的各种组件
神经元
神经网络的基本构建块是神经元。 这个概念与我们人类大脑中的实际神经网络非常相似。 这个人工神经元接受所有的输入,聚合它们,然后基于一个函数给出神经元的输出。
神经网络由许多这样的神经元组成,这些神经元以称为输入层、隐藏层和输出层的层的形式相互连接。 该网络使我们能够将任何类型的复杂数据模式映射到数学函数,这可以使用通用逼近定理在数学上进行验证。
重量
该模型可以具有权重,以便可以使用负值抑制高值。 您可以通过购买智能手机的例子来解释这一点。 价格越高,购买该智能手机的机会就越低,但如果我们的模型将所有值相加并将其与阈值进行比较,则可能会做出错误的预测。 为了消除这种影响,负权重应该减少总和并获得正确的预测。

激活函数
在神经元定义中提到,基于函数,如果神经元是输入层或隐藏层的一部分,或者用于输出层的进一步处理,神经元会将结果输出到下一层。
这个函数称为激活函数,它定义了神经元的状态。 市场上有很多激活功能可以完成这项工作,但这一切都取决于用例。 例如 sigmoid 函数、tanh 函数、softmax 函数、Relu(整流线性单元)、leaky Relu 等等。
学习率
它可以控制权重更新的速度。 考虑学习率作为重要因素的两种情况。 如果输入特征具有更稀疏的值,那么我们需要更频繁地更新权重,这就是需要更大学习率的原因。 同样,低学习率可以在密集数据中工作。
让我们看一下在更大的神经网络中使用这些组件的一些基本单元。
MP神经元
这是人工神经元的最基本形式,它计算输入总和,然后将其传递给激活函数以获得最终输出。 这是一个视觉效果:
对此的限制因素是输入应该是二进制的并且不允许实数。 这意味着如果我们想使用具有不同值的数据集,则需要将其缩放为二进制才能传递给模型。
该模型的输出也是二进制的,因此很难解释结果的质量。 输入没有任何权重,因此我们无法控制特征对结果的贡献程度。
感知器神经元
MP 神经元的一个显着缺点是它不能接受实数作为输入,这可能会导致不良结果。 这意味着如果我们想将输入特征传递给这个具有实数的神经元,则需要将其缩小到 1 或 0。 在这个神经元模型中,对输入没有这样的限制,但是通过标准化的输入会在更短的时间内给出更好的结果,因为输入的聚合对于所有特征值都是公平的。

还引入了一种学习算法,这使得该模型对新输入更加稳健。 该算法根据损失函数更新应用于每个输入的权重。 损失函数决定了模型的实际值和预测值之间的差异。 平方误差损失是深度学习模型中使用的一种流行函数。
由于感知神经元也给出二进制输出,因此损失可以为零或一。 这意味着我们可以将这种类型的损失函数以更紧凑的方式定义为“当预测不等于真实值时,损失为 1,需要更新权重,否则为零损失且不需要更新”。 权重的更新通过以下方式完成:
w = w + x 如果 wx < 0
w = w – x 如果 wx >= 0
阅读:面向初学者的 TensorFlow 对象检测教程
乙状结肠神经元
与 MP 神经元相比,感知器神经元似乎很有前景,但仍有一些问题需要解决。 它们的一个主要缺陷是它们只支持二进制分类。 另一个问题是严格的分类边界,仅输出特定情况是否可能。 它不允许以比二进制输出更易解释的概率形式进行预测的灵活性。
为了解决所有这些问题,引入了 Sigmoid 神经元,可用于多分类和回归任务。 该模型使用 sigmoid 系列函数或对数:
y = 1 / (1 + e^ (-wx + b))
如果我们绘制这个函数,那么它将采用“S”形,可以通过使用不同的“b”值来调整它的位置,“b”是这条曲线的截距。 无论传递多少输入,此函数的输出始终介于 0 和 1 之间。 这给出了类的概率,这比刚性输出要好。 这也意味着我们可以有多个分类或执行回归。
用于此的学习算法与以前的不同。 这里根据损失函数的导数更新权重和偏差。
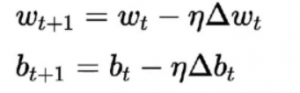
该算法通常称为梯度下降规则。 对此的推导和详细解释非常冗长且数学化,因此目前不在本文中。 简单来说,它表明要获得损失函数导数的最优最小值,我们应该沿着与梯度相反的方向移动。
结论
这是对神经网络的简要介绍。 我们看到了各种基本组件,例如充当迷你大脑并处理输入的神经元、允许平衡值的权重、控制权重更新速度的学习率以及激活神经元的激活函数。
我们还看到了基本的构建块神经元如何在增加任务的复杂性方面采取不同的形式。 我们从 MP 神经元中最基本的形式开始,然后消除感知器神经元中的一些问题,然后在 sigmoid 神经元中添加对回归和多类分类任务的支持。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
什么是人工智能中的神经网络?
神经网络或人工神经网络(ANN)是指受生物学启发的计算网络,即存在于人脑中的神经网络。 就像人脑由数十亿个神经元组成一个相互连接的网络一样,人工神经网络也包括在各个层相互连接的神经元。 这些神经元在人工智能领域也被称为节点。 开发人工神经网络的概念是为了赋予计算机类似人类的理解事物和形成决策的能力; 这里的节点或计算机被编程为像我们大脑的相互连接的细胞一样。
在人工智能领域找到工作需要哪些技能?
由于人工智能是一个高度专业化的计算机科学领域,因此想要在人工智能领域建立职业生涯的人,除了具备分析思维、设计能力和解决问题能力等技能外,还必须具备一定的学历。 非常成功的人工智能专业人士还具有技术创新的远见,这使现代企业能够拥有在竞争中保持领先所需的经济高效的软件解决方案。 不用说,出色的口头和书面沟通技巧是必须的。 技术教育背景对于理解 AI 项目的逻辑、工程和技术观点是必要的。
学习神经网络的一般先决条件是什么?
要从事任何大型人工智能项目,您需要对人工神经网络的基本原理有清晰的了解。 要构建神经网络的基本概念,首先,您必须阅读大量书籍、文章和新闻文章。 一般来说,在学习神经网络概念的先决条件中,数学起着至关重要的作用,尤其是统计学、线性代数、微积分、概率等。 除此之外,还需要 Python、Java、R 和 C++ 等语言的计算机编程技能。 中级编程技能在这里也有很大帮助。