En Java Comment lire le contenu du fichier GitHub à l'aide de l'utilitaire HttpURLConnection + ConvertStreamToString()
Publié: 2017-12-30
Dans ce didacticiel Java, nous passerons en revue les étapes pour récupérer le contenu de l'URL GitHub à l'aide de HttpURLConnection. En d'autres termes, vous trouverez ci-dessous une API Java permettant d'obtenir le contenu d'un fichier à partir de GitHub.
Chaque instance de HttpURLConnection est utilisée pour effectuer une requête unique, mais la connexion réseau sous-jacente au serveur HTTP peut être partagée de manière transparente par d'autres instances. getHeaderFields() Renvoie une Map non modifiable des champs d'en-tête. Les clés Map sont des chaînes qui représentent les noms des champs d'en-tête de réponse. Chaque valeur Map est une liste non modifiable de chaînes qui représente les valeurs de champ correspondantes.
Commençons maintenant :
- Créer la classe
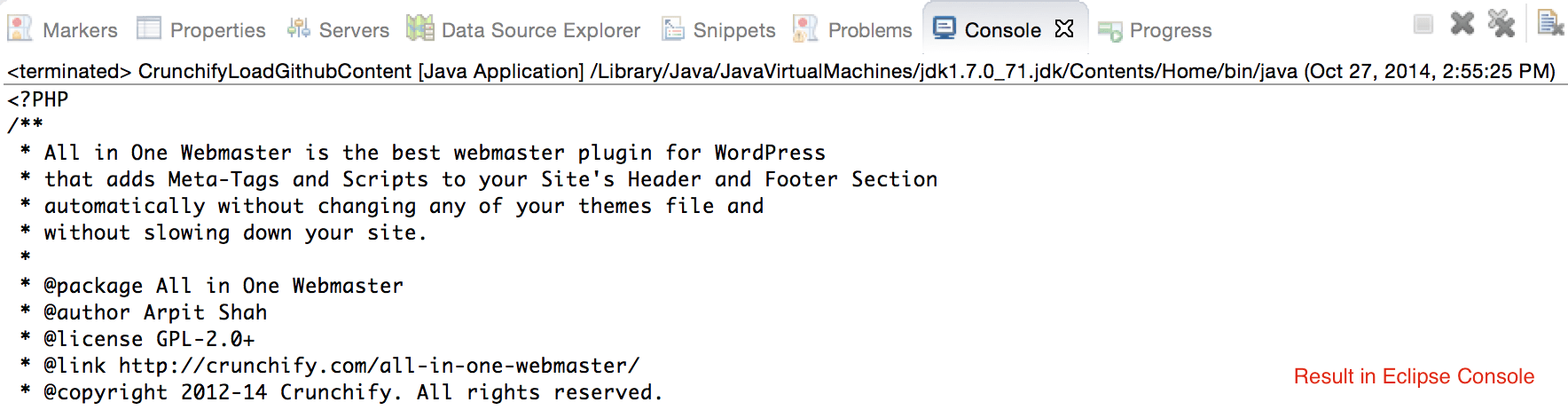
CrunchifyLoadGithubContent.java - Nous allons télécharger le contenu : https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (depuis le plugin : WP Super Cache Github Repo)
- Obtenez tous les champs d'en-tête à l'aide de l'API getHeaderFields(). Nous en avons besoin pour savoir si l'URL ci-dessus ou toute autre URL est redirigée ou non ? Remarque : Ceci est totalement facultatif. En cas de redirection HTTP 301 et HTTP 302, cela aidera.
- Créez l'API
crunchifyGetStringFromStream( InputStream crunchifyStream)pour convertir Stream en String. - Imprimez la même sortie sur la console.
REMARQUE : Le statut HTTP 301 signifie que la ressource (page) est déplacée de manière permanente vers un nouvel emplacement. 302 est qu'il a demandé que la ressource réside temporairement sous un URI différent. La plupart du temps, 301 vs 302 est important pour l'indexation dans les moteurs de recherche, car leurs robots d'exploration en tiennent compte et transfèrent le classement de la page lors de l'utilisation de 301.
En outre, il existe une hypothèse selon laquelle - l'URL GitHub doit être publique.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Lors du débogage, j'ai obtenu cela dans le cadre de la valeur crunchifyHeader . En outre, ce didacticiel s'applique également au référentiel public Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |