In Java So lesen Sie den Inhalt von GitHub-Dateien mit dem Dienstprogramm HttpURLConnection + ConvertStreamToString()
Veröffentlicht: 2017-12-30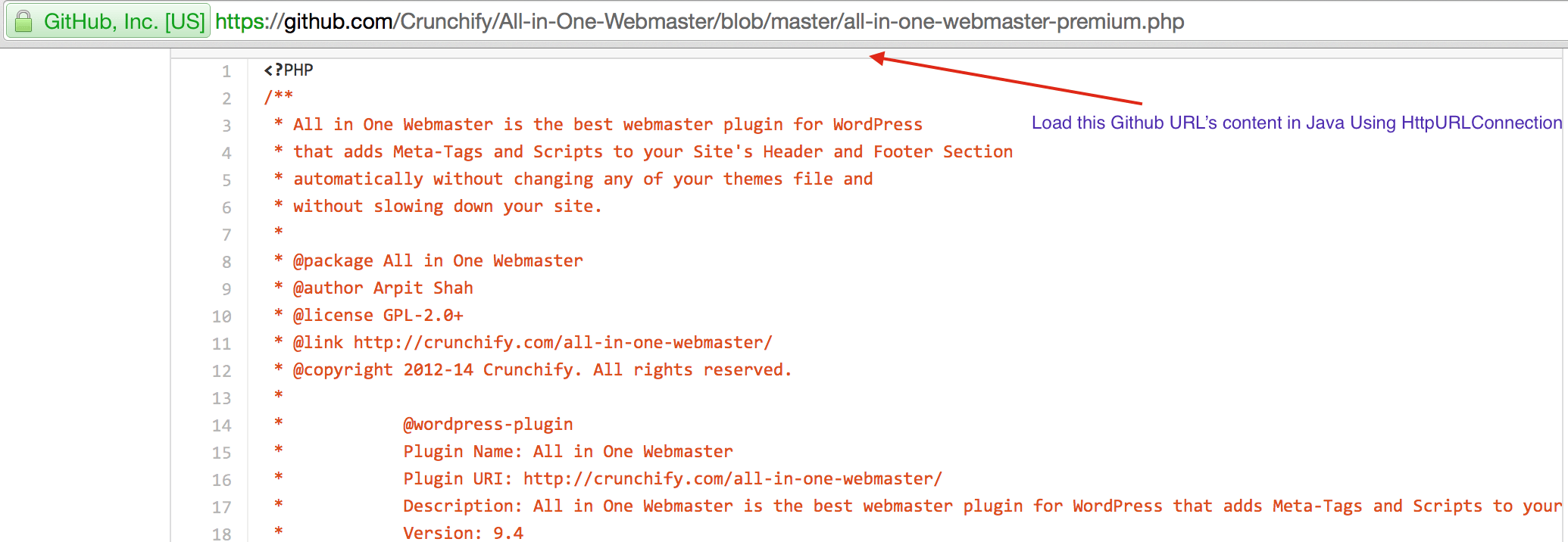
In diesem Java-Tutorial gehen wir die Schritte zum Abrufen von GitHub-URL-Inhalten mit HttpURLConnection durch. Mit anderen Worten, unten ist eine Java-API, um einen Dateiinhalt von GitHub zu erhalten.
Jede HttpURLConnection Instanz wird verwendet, um eine einzelne Anforderung zu stellen, aber die zugrunde liegende Netzwerkverbindung zum HTTP-Server kann transparent von anderen Instanzen gemeinsam genutzt werden. getHeaderFields() Gibt eine nicht modifizierbare Map der Header-Felder zurück. Die Zuordnungsschlüssel sind Zeichenfolgen, die die Feldnamen der Antwortheader darstellen. Jeder Zuordnungswert ist eine nicht änderbare Liste von Zeichenfolgen, die die entsprechenden Feldwerte darstellt.
Jetzt fangen wir an:
- Erstellen Sie die Klasse
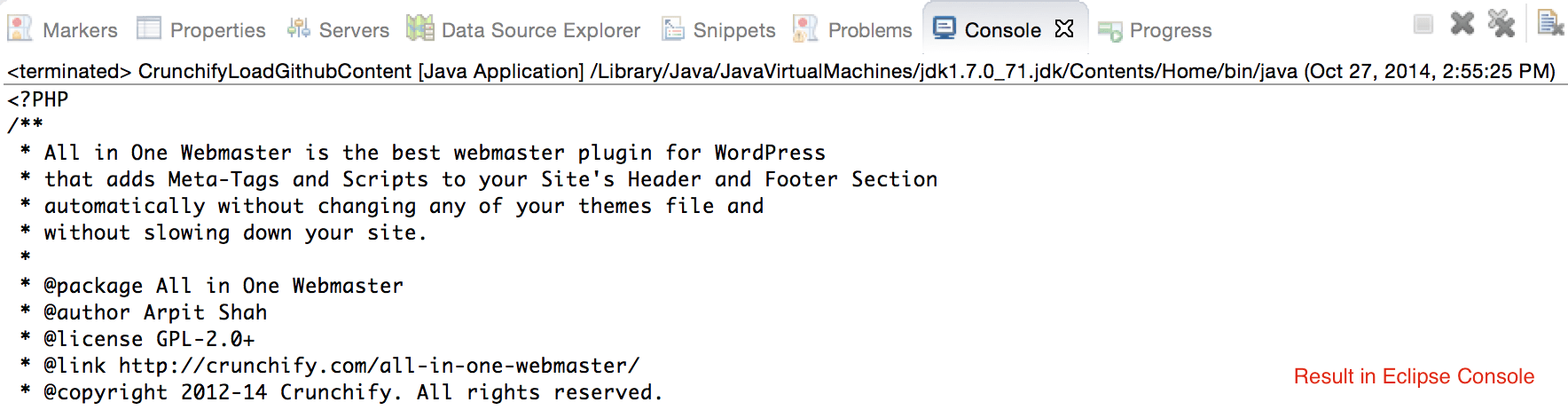
CrunchifyLoadGithubContent.java - Wir werden Inhalte herunterladen: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (vom Plugin: WP Super Cache Github Repo)
- Rufen Sie alle Header-Felder mit der getHeaderFields()-API ab. Wir brauchen dies, um herauszufinden, ob die obige URL oder eine andere URL umgeleitet wird oder nicht? Hinweis: Dies ist völlig optional. Im Falle einer HTTP 301- und HTTP 302-Weiterleitung hilft dies.
- Erstellen Sie API
crunchifyGetStringFromStream( InputStream crunchifyStream), um Stream in String zu konvertieren. - Drucken Sie die gleiche Ausgabe an die Konsole.
HINWEIS: HTTP-Status 301 bedeutet, dass die Ressource (Seite) dauerhaft an einen neuen Speicherort verschoben wird. 302 ist, dass sich die angeforderte Ressource vorübergehend unter einem anderen URI befindet. Meistens ist 301 vs. 302 wichtig für die Indizierung in Suchmaschinen, da deren Crawler dies berücksichtigen und den PageRank bei Verwendung von 301 übertragen.
Außerdem wird davon ausgegangen, dass die GitHub-URL öffentlich sein muss.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Beim Debuggen habe ich dies als Teil des crunchifyHeader Werts erhalten. Dieses Tutorial gilt auch für das öffentliche Bitbucket-Repo.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |