在 Java 中如何使用 HttpURLConnection + ConvertStreamToString() 实用程序读取 GitHub 文件内容
已发表: 2017-12-30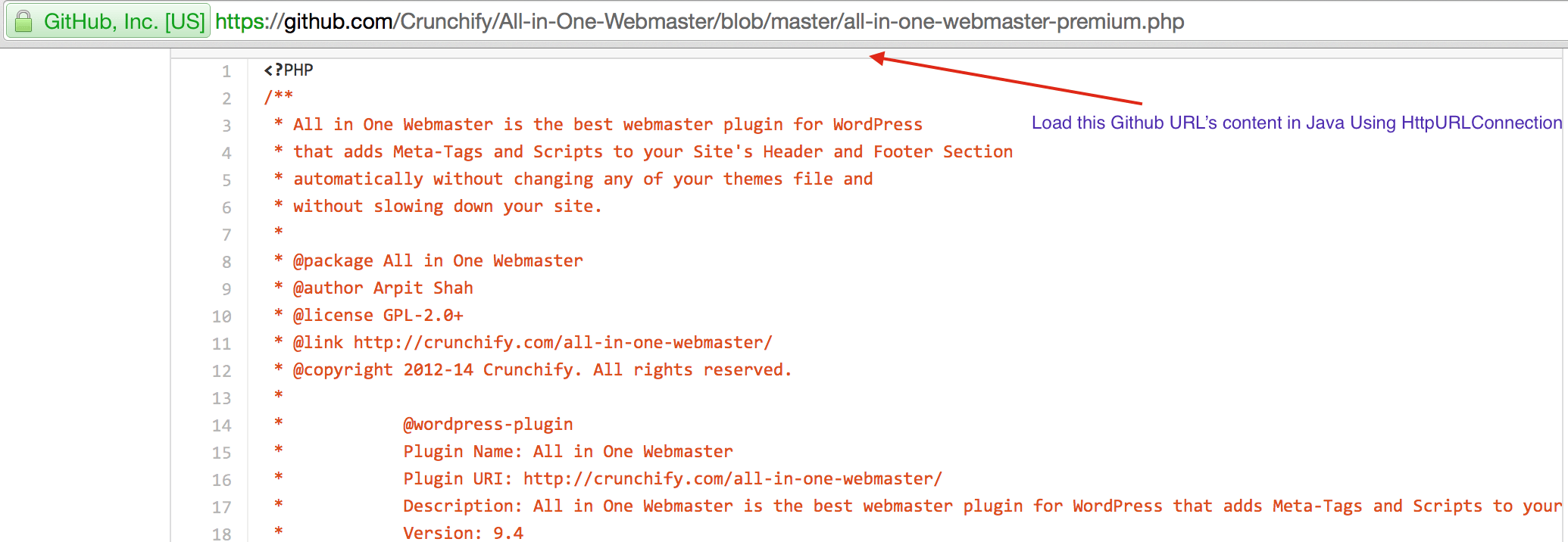
在本 Java 教程中,我们将介绍使用 HttpURLConnection 检索 GitHub URL 内容的步骤。 换句话说,下面是一个从 GitHub 获取文件内容的 Java API。
每个HttpURLConnection实例用于发出单个请求,但到 HTTP 服务器的底层网络连接可能会被其他实例透明地共享。 getHeaderFields()返回标题字段的不可修改 Map。 Map 键是表示响应标头字段名称的字符串。 每个 Map 值都是一个不可修改的字符串列表,表示相应的字段值。
现在让我们开始吧:
- 创建类
CrunchifyLoadGithubContent.java - 我们将下载内容:https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php(来自插件:WP Super Cache Github Repo)
- 使用 getHeaderFields() API 获取所有标题字段。 我们需要这个来确定上述 URL 或任何其他 URL 是否被重定向? 注意:这完全是可选的。 在 HTTP 301 和 HTTP 302 重定向的情况下,这将有所帮助。
- 创建 API
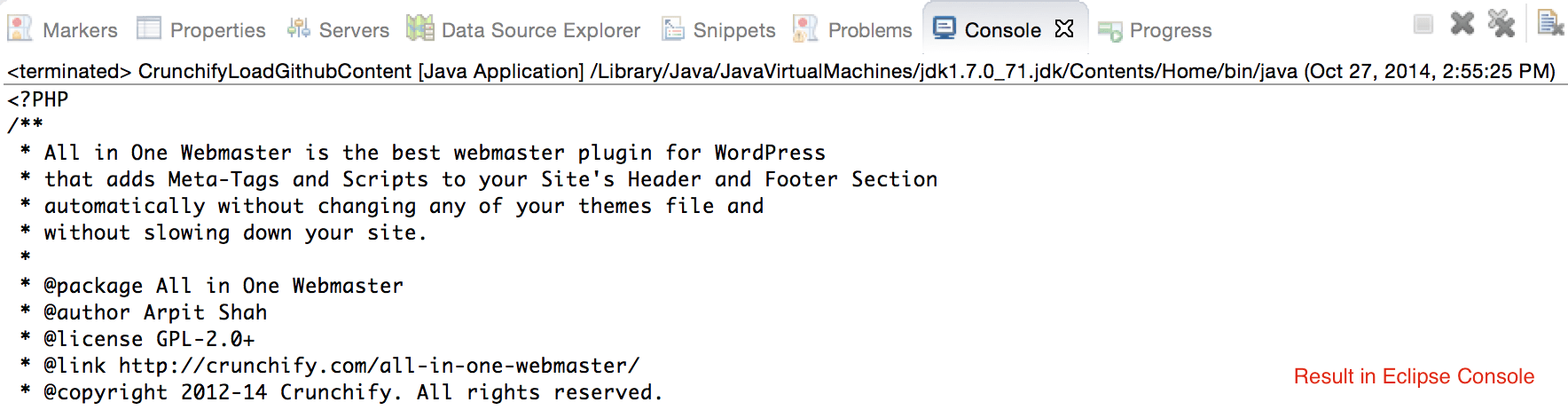
crunchifyGetStringFromStream( InputStream crunchifyStream)将 Stream 转换为 String。 - 将相同的输出打印到控制台。
注意: HTTP 状态 301 表示资源(页面)被永久移动到新位置。 302 是他请求的资源临时驻留在不同的 URI 下。 大多数情况下,301 vs 302 对于搜索引擎中的索引很重要,因为它们的爬虫会考虑到这一点,并在使用 301 时转移页面排名。
此外,还有一个假设——GitHub URL 需要公开。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
在调试时,我把它作为crunchifyHeader值的一部分。 此外,本教程也适用于 Bitbucket 公共仓库。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |