W Javie Jak czytać zawartość pliku GitHub za pomocą narzędzia HttpURLConnection + ConvertStreamToString()
Opublikowany: 2017-12-30
W tym samouczku Java omówimy kroki, aby pobrać zawartość adresu URL GitHub za pomocą HttpURLConnection. Innymi słowy, poniżej znajduje się Java API do pobierania zawartości pliku z GitHub.
Każde wystąpienie HttpURLConnection jest używane do wykonania pojedynczego żądania, ale podstawowe połączenie sieciowe z serwerem HTTP może być udostępniane w sposób przezroczysty przez inne wystąpienia. getHeaderFields() Zwraca niemodyfikowalną mapę pól nagłówka. Klucze mapy to ciągi, które reprezentują nazwy pól nagłówka odpowiedzi. Każda wartość mapy jest niemodyfikowalną listą ciągów, która reprezentuje odpowiednie wartości pól.
Teraz zacznijmy:
- Utwórz klasę
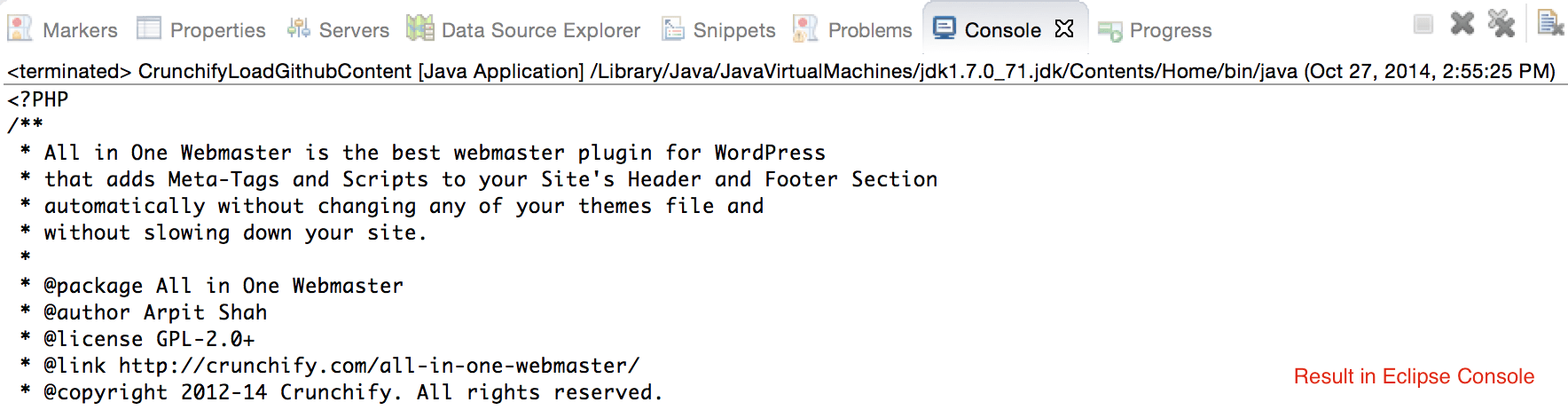
CrunchifyLoadGithubContent.java - Pobieramy zawartość: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (z wtyczki: WP Super Cache Github Repo)
- Pobierz wszystkie pola nagłówka za pomocą funkcji API getHeaderFields(). Potrzebujemy tego, aby dowiedzieć się, czy powyższy adres URL lub jakikolwiek inny adres URL jest przekierowywany, czy nie? Uwaga: jest to całkowicie opcjonalne. Pomoże to w przypadku przekierowań HTTP 301 i HTTP 302.
- Utwórz API
crunchifyGetStringFromStream( InputStream crunchifyStream), aby przekonwertować Stream na String. - Wydrukuj te same dane wyjściowe w konsoli.
UWAGA: HTTP Status 301 oznacza, że zasób (strona) zostaje przeniesiony na stałe do nowej lokalizacji. 302 jest to, że zażądał, aby zasób przebywał tymczasowo pod innym identyfikatorem URI. Przeważnie 301 vs 302 jest ważne dla indeksowania w wyszukiwarkach, ponieważ ich roboty indeksujące biorą to pod uwagę i przenoszą pozycję strony podczas korzystania z 301.
Ponadto istnieje założenie, że – adres URL GitHub musi być publiczny.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Podczas debugowania otrzymałem to jako część wartości crunchifyHeader . Ten samouczek dotyczy również publicznego repozytorium Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |