Em Java como ler o conteúdo do arquivo GitHub usando o utilitário HttpURLConnection + ConvertStreamToString()
Publicados: 2017-12-30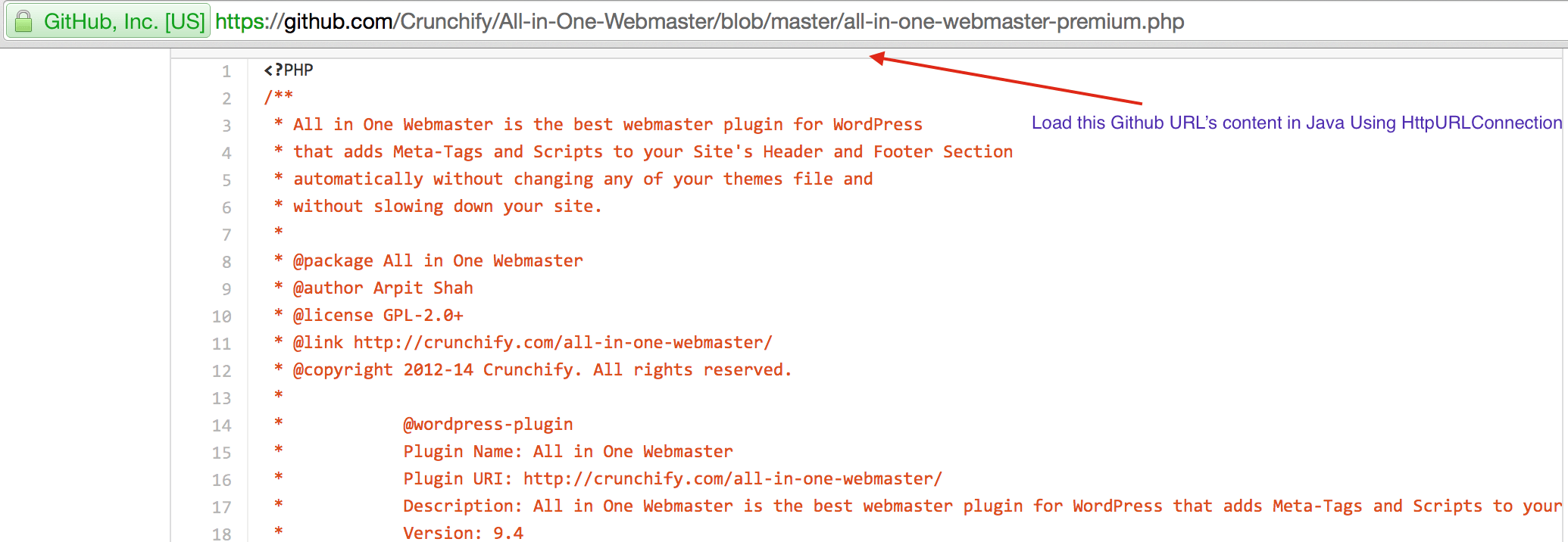
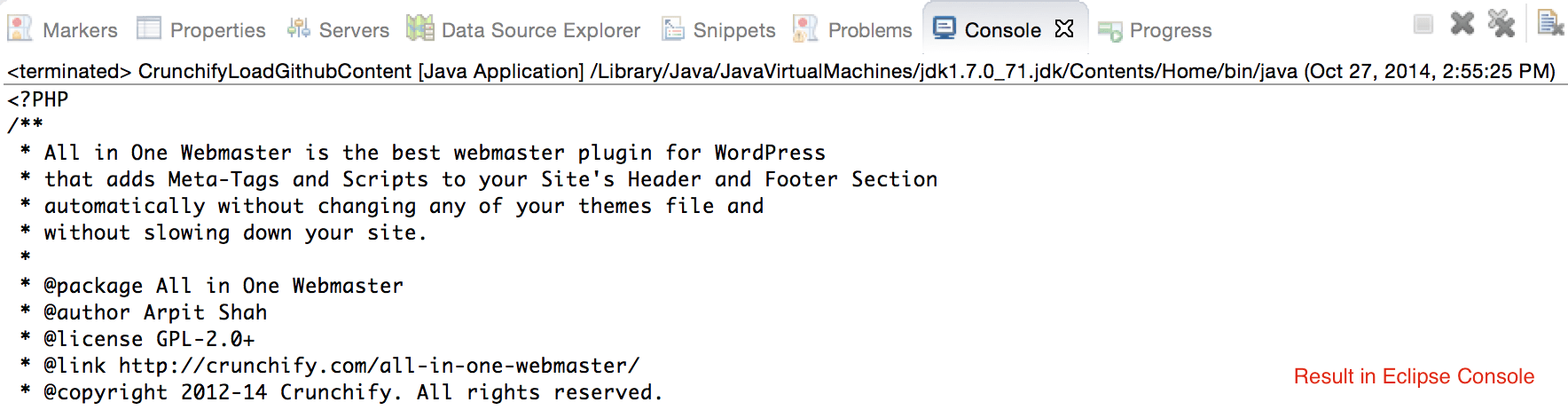
Neste tutorial de Java, veremos as etapas para recuperar o conteúdo da URL do GitHub usando HttpURLConnection. Em outras palavras, abaixo está uma API Java para obter um conteúdo de arquivo do GitHub.
Cada instância HttpURLConnection é usada para fazer uma única solicitação, mas a conexão de rede subjacente ao servidor HTTP pode ser compartilhada de forma transparente por outras instâncias. getHeaderFields() Retorna um Map não modificável dos campos de cabeçalho. As chaves Map são Strings que representam os nomes dos campos do cabeçalho de resposta. Cada valor de Mapa é uma Lista de Strings não modificável que representa os valores de campo correspondentes.
Agora vamos começar:
- Criar classe
CrunchifyLoadGithubContent.java - Vamos baixar o conteúdo: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (do plugin: WP Super Cache Github Repo)
- Obtenha todos os campos de cabeçalho usando a API getHeaderFields(). Precisamos disso para descobrir se o URL acima ou qualquer outro URL está sendo redirecionado ou não? Nota: Isso é totalmente opcional. No caso de redirecionamento HTTP 301 e HTTP 302, isso ajudará.
- Crie a API
crunchifyGetStringFromStream( InputStream crunchifyStream)para converter Stream em String. - Imprima a mesma saída no Console.
NOTA: HTTP Status 301 significa que o recurso (página) é movido permanentemente para um novo local. 302 é que o recurso solicitado reside temporariamente em um URI diferente. Principalmente 301 vs 302 é importante para indexação em mecanismos de pesquisa, pois seus rastreadores levam isso em consideração e transferem o page rank ao usar 301.
Além disso, há uma suposição de que – a URL do GitHub precisa ser pública.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Durante a depuração, obtive isso como parte do valor crunchifyHeader . Além disso, este tutorial também se aplica ao repositório público do Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |