В Java Как прочитать содержимое файла GitHub с помощью утилиты HttpURLConnection + ConvertStreamToString()
Опубликовано: 2017-12-30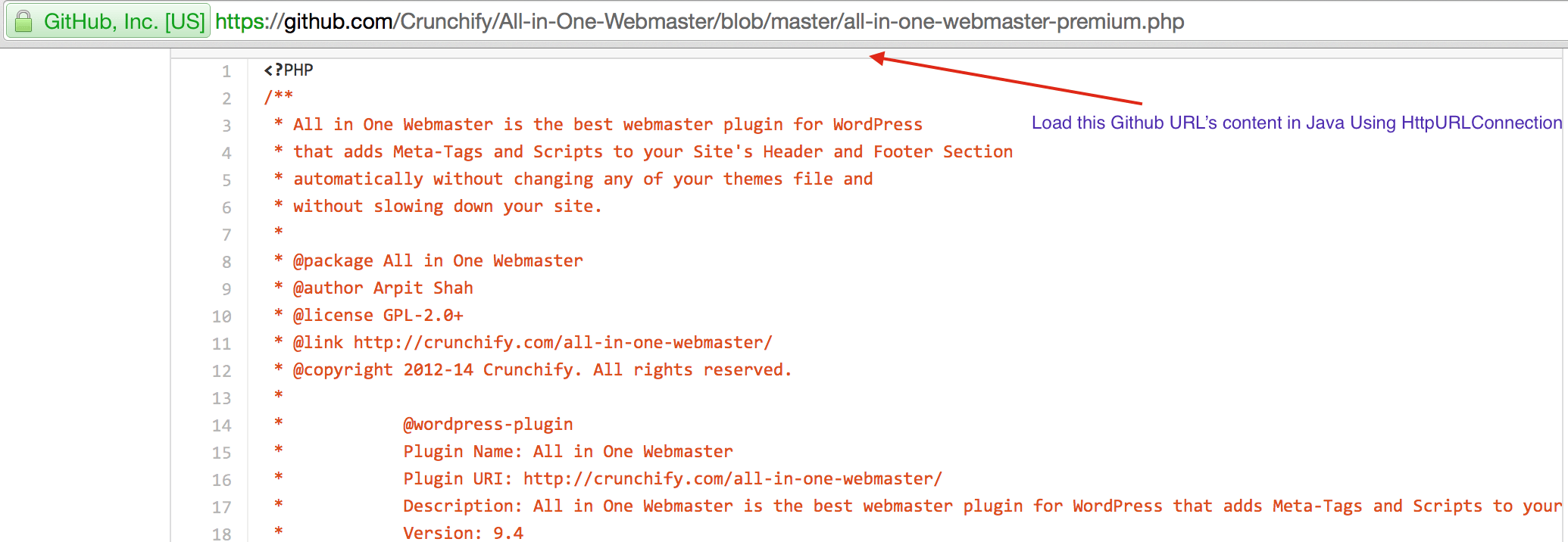
В этом руководстве по Java мы рассмотрим шаги для получения содержимого URL-адреса GitHub с помощью HttpURLConnection. Другими словами, ниже приведен Java API для получения содержимого файла с GitHub.
Каждый экземпляр HttpURLConnection используется для выполнения одного запроса, но базовое сетевое соединение с HTTP-сервером может прозрачно совместно использоваться другими экземплярами. getHeaderFields() Возвращает неизменяемую карту полей заголовка. Ключи карты — это строки, представляющие имена полей заголовка ответа. Каждое значение карты представляет собой неизменяемый список строк, который представляет соответствующие значения полей.
Теперь приступим:
- Создайте класс
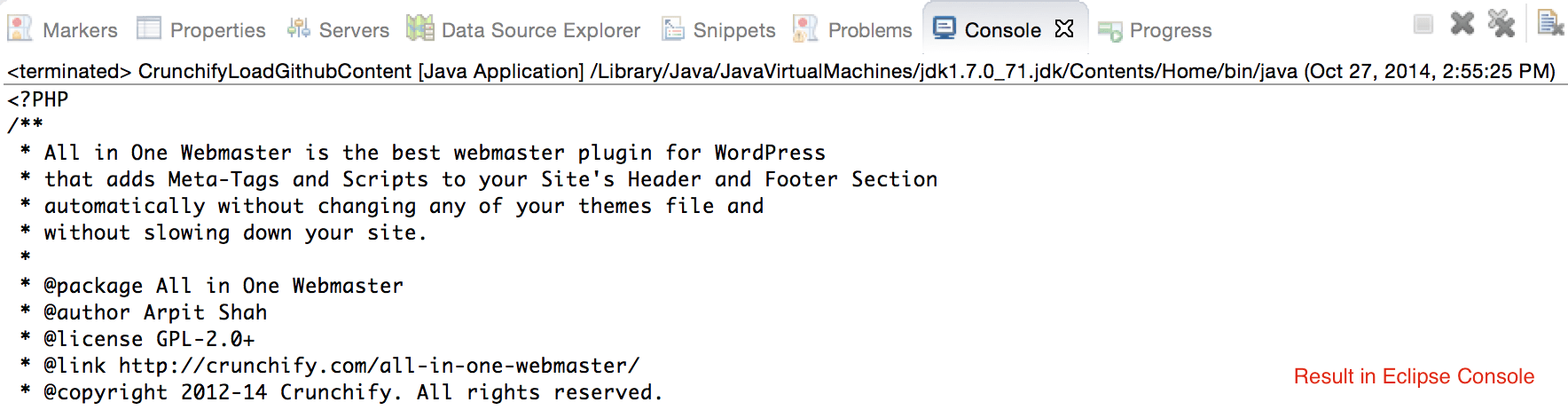
CrunchifyLoadGithubContent.java - Мы загрузим содержимое: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (из плагина: WP Super Cache Github Repo)
- Получите все поля заголовка, используя API getHeaderFields(). Нам нужно это, чтобы узнать, перенаправляется ли указанный выше URL или любой другой URL или нет? Примечание. Это совершенно необязательно. В случае перенаправления HTTP 301 и HTTP 302 это поможет.
- Создайте API
crunchifyGetStringFromStream( InputStream crunchifyStream)для преобразования потока в строку. - Выведите тот же вывод в консоль.
ПРИМЕЧАНИЕ. Статус HTTP 301 означает, что ресурс (страница) навсегда перемещен в новое место. 302 заключается в том, что запрашиваемый ресурс временно находится под другим URI. В основном 301 против 302 важен для индексации в поисковых системах, поскольку их сканеры учитывают это и передают рейтинг страницы при использовании 301.
Кроме того, предполагается, что URL-адрес GitHub должен быть общедоступным.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Во время отладки я получил это как часть значения crunchifyHeader . Кроме того, это руководство применимо и к общедоступному репозиторию Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |