În Java Cum să citiți conținutul fișierului GitHub folosind utilitarul HttpURLConnection + ConvertStreamToString()
Publicat: 2017-12-30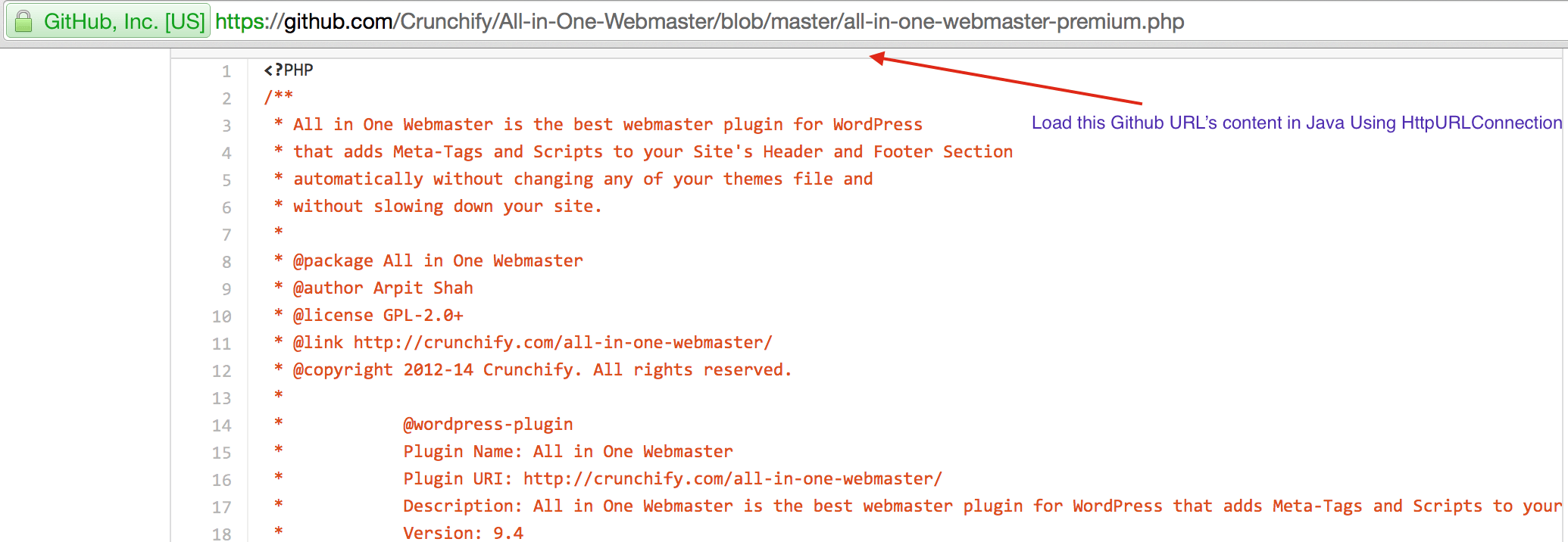
În acest tutorial Java, vom parcurge pașii pentru a prelua conținutul URL GitHub folosind HttpURLConnection. Cu alte cuvinte, mai jos este un API Java pentru a obține conținutul unui fișier din GitHub.
Fiecare instanță HttpURLConnection este folosită pentru a face o singură solicitare, dar conexiunea de rețea de bază la serverul HTTP poate fi partajată în mod transparent de alte instanțe. getHeaderFields() Returnează o hartă nemodificabilă a câmpurilor de antet. Cheile Hartă sunt șiruri de caractere care reprezintă numele câmpurilor pentru antetul răspunsului. Fiecare valoare Map este o Listă de șiruri nemodificabilă care reprezintă valorile câmpurilor corespunzătoare.
Acum să începem:
- Creați clasa
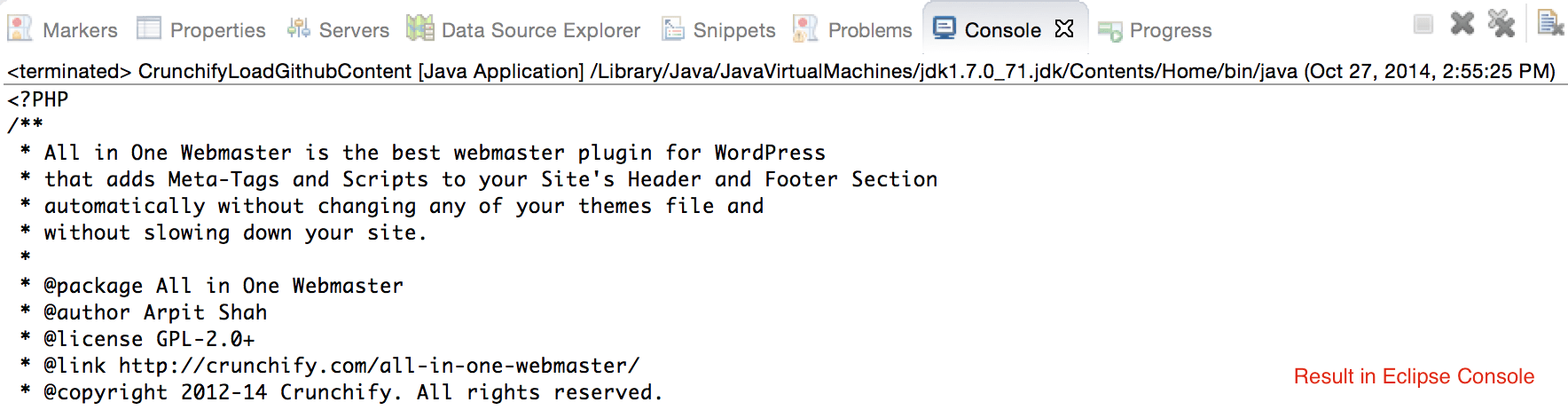
CrunchifyLoadGithubContent.java - Vom descărca conținut: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (din plugin: WP Super Cache Github Repo)
- Obțineți toate câmpurile de antet folosind API-ul getHeaderFields(). Avem nevoie de acest lucru pentru a afla dacă adresa URL de mai sus sau orice altă adresă URL este redirecționată sau nu? Notă: Acest lucru este complet opțional. În cazul redirecționării HTTP 301 și HTTP 302, acest lucru va ajuta.
- Creați API
crunchifyGetStringFromStream( InputStream crunchifyStream)pentru a converti Stream în String. - Imprimați aceeași ieșire în Consolă.
NOTĂ: Starea HTTP 301 înseamnă că resursa (pagina) este mutată permanent într-o locație nouă. 302 este că resursa solicitată se află temporar sub un alt URI. În cea mai mare parte, 301 vs 302 este important pentru indexarea în motoarele de căutare, deoarece crawlerele lor iau în considerare acest lucru și transferă rangul paginii atunci când folosesc 301.
De asemenea, există o presupunere că – URL-ul GitHub trebuie să fie public.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
În timpul depanării, am primit asta ca parte a valorii crunchifyHeader . De asemenea, acest tutorial se aplică și pentru depozitul public Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |