In Java Come leggere il contenuto del file GitHub utilizzando l'utilità HttpURLConnection + ConvertStreamToString()
Pubblicato: 2017-12-30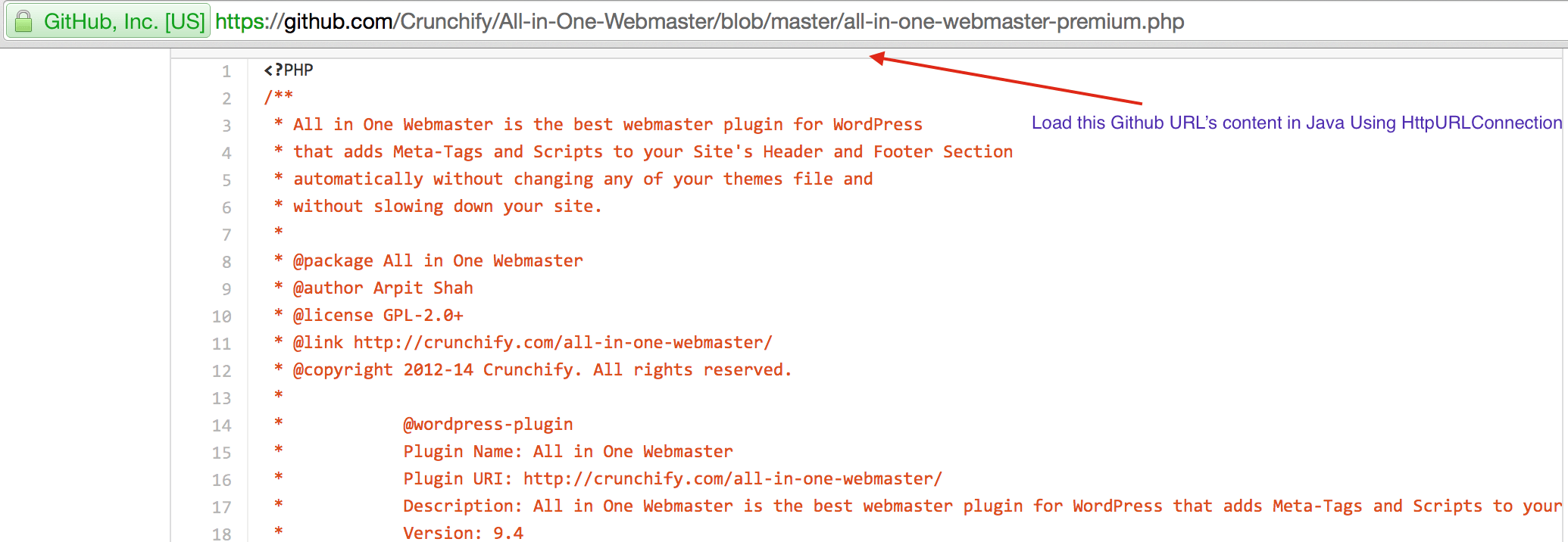
In questo tutorial Java esamineremo i passaggi per recuperare il contenuto dell'URL di GitHub utilizzando HttpURLConnection. In altre parole, di seguito è riportata un'API Java per ottenere il contenuto di un file da GitHub.
Ogni istanza HttpURLConnection viene utilizzata per effettuare una singola richiesta, ma la connessione di rete sottostante al server HTTP può essere condivisa in modo trasparente da altre istanze. getHeaderFields() Restituisce una mappa non modificabile dei campi di intestazione. Le chiavi della mappa sono stringhe che rappresentano i nomi dei campi dell'intestazione della risposta. Ogni valore della mappa è un elenco di stringhe non modificabile che rappresenta i valori dei campi corrispondenti.
Ora iniziamo:
- Crea classe
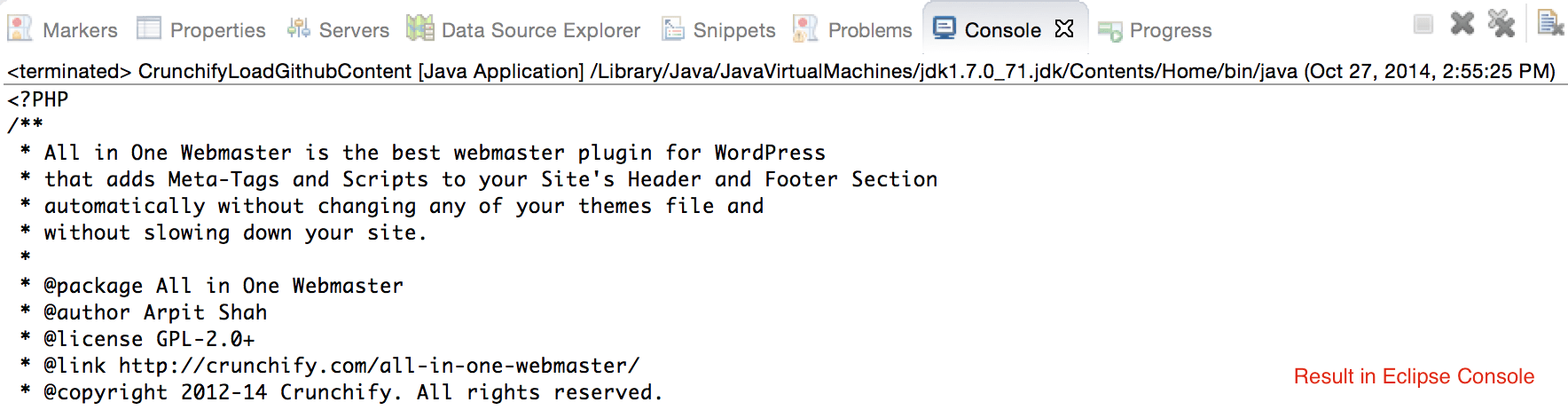
CrunchifyLoadGithubContent.java - Scaricheremo i contenuti: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (dal plugin: WP Super Cache Github Repo)
- Ottieni tutti i campi di intestazione utilizzando l'API getHeaderFields(). Abbiamo bisogno di questo per scoprire se l'URL sopra o qualsiasi altro URL viene reindirizzato o no? Nota: questo è totalmente facoltativo. In caso di reindirizzamento HTTP 301 e HTTP 302 questo sarà di aiuto.
- Crea API
crunchifyGetStringFromStream( InputStream crunchifyStream)per convertire Stream in String. - Stampa lo stesso output su Console.
NOTA: lo stato HTTP 301 significa che la risorsa (pagina) viene spostata in modo permanente in una nuova posizione. 302 è che la risorsa richiesta risieda temporaneamente sotto una diversa URI. Per lo più 301 vs 302 è importante per l'indicizzazione nei motori di ricerca poiché i loro crawler ne tengono conto e trasferiscono il page rank quando utilizzano 301.
Inoltre, si presume che l'URL di GitHub debba essere pubblico.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . IOException ; import java . io . InputStream ; import java . io . InputStreamReader ; import java . io . Reader ; import java . io . StringWriter ; import java . io . Writer ; import java . net . HttpURLConnection ; import java . net . URL ; import java . util . List ; import java . util . Map ; /** * @author Crunchify.com * */ public class CrunchifyLoadGithubContent { public static void main ( String [ ] args ) throws Throwable { String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php" ; URL crunchifyUrl = new URL ( link ) ; HttpURLConnection crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; Map < String , List <String> > crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; // If URL is getting 301 and 302 redirection HTTP code then get new URL link. // This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere for ( String header : crunchifyHeader . get ( null ) ) { if ( header . contains ( " 302 " ) | | header . contains ( " 301 " ) ) { link = crunchifyHeader . get ( "Location" ) . get ( 0 ) ; crunchifyUrl = new URL ( link ) ; crunchifyHttp = ( HttpURLConnection ) crunchifyUrl . openConnection ( ) ; crunchifyHeader = crunchifyHttp . getHeaderFields ( ) ; } } InputStream crunchifyStream = crunchifyHttp . getInputStream ( ) ; String crunchifyResponse = crunchifyGetStringFromStream ( crunchifyStream ) ; System . out . println ( crunchifyResponse ) ; } // ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream() private static String crunchifyGetStringFromStream ( InputStream crunchifyStream ) throws IOException { if ( crunchifyStream ! = null ) { Writer crunchifyWriter = new StringWriter ( ) ; char [ ] crunchifyBuffer = new char [ 2048 ] ; try { Reader crunchifyReader = new BufferedReader ( new InputStreamReader ( crunchifyStream , "UTF-8" ) ) ; int counter ; while ( ( counter = crunchifyReader . read ( crunchifyBuffer ) ) ! = - 1 ) { crunchifyWriter . write ( crunchifyBuffer , 0 , counter ) ; } } finally { crunchifyStream . close ( ) ; } return crunchifyWriter . toString ( ) ; } else { return "No Contents" ; } } } |
Durante il debug l'ho ottenuto come parte del valore di crunchifyHeader . Inoltre, questo tutorial si applica anche al repository pubblico Bitbucket.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
{ null = [ HTTP / 1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL. ] , X - Cache - Hits = [ 1 ] , ETag = [ "94a3eb8b3b5505f746aa8530667969673a8e182d" ] , Content - Length = [ 24436 ] , X - XSS - Protection = [ 1 ; mode = block ] , Expires = [ Mon , 27Oct201420 : 00 : 31GMT ] , X - Served - By = [ cache - dfw1825 - DFW ] , Source - Age = [ 14 ] , Connection = [ Keep - Alive ] , Server = [ Apache ] , X - Cache = [ HIT ] , Cache - Control = [ max - age = 300 ] , X - Content - Type - Options = [ nosniff ] , X - Frame - Options = [ deny ] , Strict - Transport - Security = [ max - age = 31536000 ] , Vary = [ Authorization , Accept - Encoding ] , Access - Control - Allow - Origin = [ https : //render.githubusercontent.com ] , Date = [ Mon , 27Oct201419 : 55 : 31GMT ] , Via = [ 1.1varnish ] , Keep - Alive = [ timeout = 10 , max = 50 ] , Accept - Ranges = [ bytes ] , Content - Type = [ text / plain ; charset = utf - 8 ] , Content - Security - Policy = [ default - src 'none' ] } |