
什麼是數據挖掘中的規範化以及如何做到這一點?
已發表: 2020-11-23公司越來越依賴數據來更多地了解他們的客戶。 因此,數據分析師有更大的責任去探索和分析大量的原始數據,並從中收集有意義的客戶趨勢和模式。 這被稱為數據挖掘。 數據分析師使用數據挖掘技術、高級統計分析和數據可視化技術來獲得新的見解。
這些可以幫助企業製定有效的營銷策略,以提高業務績效、擴大銷售規模並降低間接成本。 儘管有數據挖掘的工具和算法,但這並不是小菜一碟,因為現實世界的數據是異構的。 因此,在數據挖掘方面存在相當多的挑戰。 如果您想獲得數據挖掘方面的專業知識,請學習數據科學。
常見的挑戰之一是,數據庫通常包含不同單位、範圍和尺度的屬性。 將算法應用於如此廣泛的數據可能無法提供準確的結果。 這就要求數據挖掘中的數據規範化。
這是對異構數據進行規範化的必要過程。 數據可以放在更小的範圍內,例如 0.0 到 1.0 或 -1.0 到 1.0。 簡單來說,數據規範化使數據更容易分類和理解。
目錄
為什麼需要數據挖掘中的規範化?
數據歸一化主要用於最小化或排除重複數據。 數據的重複性是一個關鍵問題。 這是因為將數據存儲在關係數據庫中越來越成問題,將相同的數據保存在多個位置。 數據挖掘中的規範化是一個有益的過程,因為它可以實現如下所述的某些優點:
- 在一組標準化數據上應用數據挖掘算法要容易得多。
- 數據挖掘算法應用於一組標準化數據的結果更加準確和有效。
- 一旦數據被規範化,從數據庫中提取數據就會變得更快。
- 更具體的數據分析方法可以應用於標準化數據。
閱讀:數據挖掘技術
數據挖掘中數據規範化的 3 種流行技術
在數據挖掘中進行規範化有三種流行的方法。 它們包括:
最小最大歸一化
更容易理解的是 200 和 1000000 之間的差異或 0.2 和 1 之間的差異。確實,當最小值和最大值之間的差異較小時,數據變得更具可讀性。 最小-最大歸一化通過將數據范圍轉換為範圍從 0 到 1 的尺度來發揮作用。
最小-最大歸一化公式
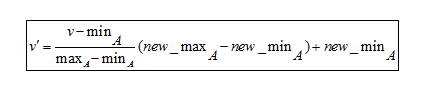
為了理解這個公式,這裡有一個例子。 假設一家公司想根據員工的工作年限來決定升職。 因此,它需要分析一個如下所示的數據庫:
| 員工姓名 | 多年經驗 |
| 美國廣播公司 | 8 |
| XYZ | 20 |
| 二維碼 | 10 |
| 移動網絡運營商 | 15 |
- 最小值為 8
- 最大值為 20
由於此公式在 0 和 1 之間縮放數據,
- 新的最小值為 0
- 新的最大值為 1
這裡,V代表屬性的相應值,即8、10、15、20
應用 min-max 歸一化公式後,以下是屬性的V'值:
- 對於 8 年的經驗: v'= 0
- 對於 10 年的經驗: v' = 0.16
- 對於 15 年的經驗: v' = 0.58
- 對於 20 年的經驗: v' = 1
因此,最小-最大歸一化可以將大數字減少到小得多的值。 這使得讀取測距數字之間的差異變得非常容易。
十進制標度歸一化
十進制縮放是數據挖掘中的另一種規範化技術。 它通過將數字轉換為小數點來發揮作用。
十進制縮放公式
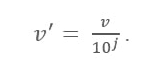
這裡:
- V' 是應用小數縮放後的新值
- V是屬性的各自值
現在,整數 J 定義了小數點的移動。 那麼,如何定義呢? 它等於數據表中最大值中存在的位數。 這是一個例子:

假設一家公司想要比較新員工的薪水。 以下是數據值:
| 員工姓名 | 薪水 |
| 美國廣播公司 | 10,000 |
| XYZ | 25,000 |
| 二維碼 | 8,000 |
| 移動網絡運營商 | 15,000 |
現在,尋找數據中的最大值。 在這種情況下,它是 25,000。 現在計算這個值的位數。 在這種情況下,它是“5”。 所以這裡的'j'等於5,即100,000。 這意味著這裡的 V(屬性值)需要除以 100,000。
應用零十進制縮放公式後,以下是新值:
| 姓名 | 薪水 | 十進制縮放後的薪水 |
| 美國廣播公司 | 10,000 | 0.1 |
| XYZ | 25, 000 | 0.25 |
| 二維碼 | 8, 000 | 0.08 |
| 移動網絡運營商 | 15,000 | 0.15 |
因此,十進制縮放可以將大數字淡化為易於理解的較小十進制值。 此外,歸屬於不同單位的數據一旦轉換為較小的十進制值,就會變得易於閱讀和理解。
必讀:數據挖掘項目的想法和主題
Z 分數歸一化
Z-Score 值是為了了解數據點與平均值的距離。 從技術上講,它測量低於或高於平均值的標準偏差。 它的範圍從 -3 標準偏差到 +3 標準偏差。 數據挖掘中的Z-score歸一化對於需要比較一個值與平均值(例如來自測試或調查的結果)的那些類型的數據分析很有用。
例如,一個人的體重是 150 磅。 現在,如果需要將該值與大量數據表中列出的人群的平均體重進行比較,則需要對這些值進行 Z-score 標準化來研究這些值,尤其是當某人的體重以千克為單位時。
結論
由於數據來自不同的來源,因此在任何一批數據中具有不同的屬性是很常見的。 因此,數據挖掘中的規範化就像預處理和準備數據以供分析。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、行業專家的指導、1與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
數據挖掘中的規範化是什麼意思?
規範化是對屬性數據進行縮放以使其落在更窄範圍內的過程,例如 -1.0 到 1.0 或 0.0 到 1.0。 一般來說,它對分類算法是有益的。 在處理各種尺度的特徵時,通常需要歸一化; 否則,由於其他屬性具有更大範圍的值,它可能會在較小範圍內稀釋同等重要屬性的功效。 換句話說,當存在許多特徵但它們的值在不同的尺度上時,這可能會導致在進行數據挖掘活動時數據模型不足。 結果,它們被歸一化以將所有特徵放在同一尺度上。
歸一化有哪些不同類型?
規範化是您創建的每個數據庫都應遵循的過程。 範式是指採用數據庫架構並向其應用一組正式標準和規則的行為。 歸一化過程分類如下:第一範式(1 NF),第二範式(2 NF),第三範式(3 NF),博伊斯科德範式或第四範式(BCNF或4 NF),第五範式(5 NF) 和第六範式 (6 NF) (6 NF)。
什麼是最小-最大歸一化?
標準化數據最流行的方法之一是最小-最大標準化。 對於每個特徵,最小值轉換為 0,最大值轉換為 1,所有其他值轉換為 0 到 1 之間的小數。例如,如果特徵的最小值為 20,則最高值為 40,30 將轉換為大約 0.5,因為它介於 20 和 40 之間。最小-最大歸一化的一個重要缺點是它不能很好地處理異常值。 例如,如果您有 0 到 40 範圍內的 99 個值,其中一個是 100,則所有 99 個值都將轉換為 0 到 0.4 範圍內的值。