
Apa itu Normalisasi dalam Data Mining dan Bagaimana Cara Melakukannya?
Diterbitkan: 2020-11-23Perusahaan semakin mengandalkan data untuk mempelajari lebih lanjut tentang pelanggan mereka. Dengan demikian, analis data memiliki tanggung jawab yang lebih besar untuk mengeksplorasi dan menganalisis blok besar data mentah dan mengumpulkan tren dan pola pelanggan yang berarti darinya. Ini dikenal sebagai penambangan data. Analis data menggunakan teknik penambangan data, analisis statistik tingkat lanjut, dan teknologi visualisasi data untuk mendapatkan wawasan baru.
Ini dapat membantu bisnis mengembangkan strategi pemasaran yang efektif untuk meningkatkan kinerja bisnis, meningkatkan penjualan, dan mengurangi biaya overhead. Meskipun ada alat dan algoritme untuk penambangan data, ini bukanlah hal yang mudah, karena data dunia nyata bersifat heterogen. Jadi, ada beberapa tantangan dalam hal penambangan data. Pelajari ilmu data jika Anda ingin mendapatkan keahlian dalam penambangan data.
Salah satu tantangan umum adalah bahwa, biasanya, database berisi atribut unit, jangkauan, dan skala yang berbeda. Menerapkan algoritme ke data yang berkisar secara drastis seperti itu mungkin tidak memberikan hasil yang akurat. Ini panggilan untuk normalisasi data dalam penambangan data .
Ini adalah proses yang diperlukan untuk menormalkan data yang heterogen. Data dapat dimasukkan ke dalam rentang yang lebih kecil, seperti 0,0 hingga 1,0 atau -1,0 hingga 1,0. Dengan kata sederhana, normalisasi data membuat data lebih mudah untuk diklasifikasikan dan dipahami.
Daftar isi
Mengapa Normalisasi dalam Data Mining Diperlukan?
Normalisasi data terutama diperlukan untuk meminimalkan atau mengecualikan data duplikat. Duplikasi dalam data adalah masalah kritis. Ini karena menyimpan data dalam database relasional semakin bermasalah, menyimpan data yang identik di lebih dari satu tempat. Normalisasi dalam penambangan data adalah prosedur yang bermanfaat karena memungkinkan pencapaian keuntungan tertentu seperti yang disebutkan di bawah ini:
- Jauh lebih mudah untuk menerapkan algoritme penambangan data pada kumpulan data yang dinormalisasi.
- Hasil algoritma data mining yang diterapkan pada sekumpulan data yang dinormalisasi lebih akurat dan efektif.
- Setelah data dinormalisasi, ekstraksi data dari database menjadi jauh lebih cepat.
- Metode analisis data yang lebih spesifik dapat diterapkan pada data yang dinormalisasi.
Baca: Teknik Data Mining
3 Teknik Populer untuk Normalisasi Data dalam Data Mining
Ada tiga metode populer untuk melakukan normalisasi dalam data mining . Mereka termasuk:
Normalisasi Minimal
Apa yang lebih mudah dipahami – perbedaan antara 200 dan 1000000 atau perbedaan antara 0,2 dan 1. Memang, ketika perbedaan antara nilai minimum dan maksimum lebih kecil, data menjadi lebih mudah dibaca. Normalisasi min-max berfungsi dengan mengubah rentang data menjadi skala yang berkisar dari 0 hingga 1.
Rumus Normalisasi Min-Max
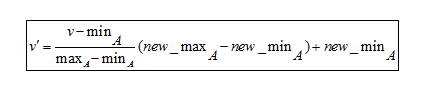
Untuk memahami rumus, berikut adalah contohnya. Misalkan sebuah perusahaan ingin memutuskan promosi berdasarkan pengalaman kerja karyawannya selama bertahun-tahun. Jadi, perlu menganalisis database yang terlihat seperti ini:
| nama karyawan | Tahun-Tahun Pengalaman |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | 15 |
- Nilai minimumnya adalah 8
- Nilai maksimum adalah 20
Karena rumus ini menskalakan data antara 0 dan 1,
- Min baru adalah 0
- Maksimum baru adalah 1
Di sini, V mewakili nilai masing-masing atribut, yaitu, 8, 10, 15, 20
Setelah menerapkan rumus normalisasi min-max, berikut adalah nilai V' untuk atribut:
- Selama 8 tahun pengalaman: v'= 0
- Selama 10 tahun pengalaman: v' = 0,16
- Selama 15 tahun pengalaman: v' = 0,58
- Selama 20 tahun pengalaman: v' = 1
Jadi, normalisasi min-max dapat mengurangi angka besar menjadi nilai yang jauh lebih kecil. Ini membuatnya sangat mudah untuk membaca perbedaan antara angka-angka rentang.
Normalisasi Penskalaan Desimal
Penskalaan desimal adalah teknik lain untuk normalisasi dalam penambangan data . Ini berfungsi dengan mengubah angka menjadi titik desimal.
Rumus Penskalaan Desimal
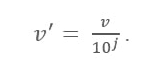
Di Sini:
- V' adalah nilai baru setelah menerapkan skala desimal
- V adalah nilai masing-masing atribut
Sekarang, bilangan bulat J mendefinisikan pergerakan titik desimal. Jadi, bagaimana mendefinisikannya? Itu sama dengan jumlah digit yang ada dalam nilai maksimum dalam tabel data. Berikut ini contohnya:

Misalkan sebuah perusahaan ingin membandingkan gaji para anggota baru. Berikut nilai datanya:
| nama karyawan | Gaji |
| ABC | 10.000 |
| XYZ | 25.000 |
| PQR | 8,000 |
| MNO | 15.000 |
Sekarang, cari nilai maksimum dalam data. Dalam hal ini, itu adalah 25.000. Sekarang hitung jumlah digit dalam nilai ini. Dalam hal ini, itu adalah '5'. Jadi disini 'j' sama dengan 5, yaitu 100.000. Ini berarti V (nilai atribut) perlu dibagi 100.000 di sini.
Setelah menerapkan rumus penskalaan desimal nol, berikut adalah nilai barunya:
| Nama | Gaji | Gaji setelah Penskalaan Desimal |
| ABC | 10.000 | 0.1 |
| XYZ | 25.000 | 0,25 |
| PQR | 8.000 | 0,08 |
| MNO | 15.000 | 0.15 |
Dengan demikian, penskalaan desimal dapat menurunkan angka besar menjadi nilai desimal yang lebih kecil yang mudah dipahami. Selain itu, data yang dikaitkan dengan unit yang berbeda menjadi mudah dibaca dan dipahami setelah diubah menjadi nilai desimal yang lebih kecil.
Harus Dibaca: Ide & Topik Proyek Data Mining
Normalisasi Z-Score
Nilai Z-Score adalah untuk memahami seberapa jauh titik data dari mean. Secara teknis, ini mengukur standar deviasi di bawah atau di atas rata-rata. Ini berkisar dari -3 standar deviasi hingga +3 standar deviasi. Normalisasi Z-score dalam data mining berguna untuk jenis analisis data di mana ada kebutuhan untuk membandingkan nilai sehubungan dengan nilai rata-rata (rata-rata), seperti hasil dari tes atau survei.
Misalnya, berat badan seseorang adalah 150 pon. Nah, jika ada kebutuhan untuk membandingkan nilai itu dengan berat rata-rata populasi yang tercantum dalam tabel data yang luas, normalisasi Z-score diperlukan untuk mempelajari nilai-nilai tersebut, terutama jika berat badan seseorang dicatat dalam kilogram.
Kesimpulan
Karena data berasal dari sumber yang berbeda, sangat umum untuk memiliki atribut yang berbeda dalam kumpulan data apa pun. Dengan demikian, normalisasi dalam data mining seperti pra-pemrosesan dan menyiapkan data untuk analisis.
Jika Anda penasaran untuk belajar tentang ilmu data, lihat Program PG Eksekutif IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan pakar industri, 1 -on-1 dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa yang dimaksud dengan Normalisasi dalam Data Mining?
Normalisasi adalah proses penskalaan data atribut sedemikian rupa sehingga berada dalam rentang yang lebih sempit, seperti -1.0 hingga 1.0 atau 0.0 hingga 1.0. Ini bermanfaat untuk algoritma klasifikasi secara umum. Normalisasi biasanya diperlukan ketika berhadapan dengan karakteristik pada berbagai skala; jika tidak, ini dapat melemahkan kemanjuran atribut yang sama signifikannya pada skala yang lebih rendah karena atribut lain memiliki nilai pada skala yang lebih besar. Dengan kata lain, ketika ada banyak karakteristik tetapi nilainya berada pada skala yang berbeda, ini mungkin menghasilkan model data yang tidak memadai saat melakukan aktivitas penambangan data. Akibatnya, mereka dinormalisasi untuk menempatkan semua karakteristik pada skala yang sama.
Apa saja jenis-jenis Normalisasi?
Normalisasi adalah prosedur yang harus diikuti untuk setiap database yang Anda buat. Bentuk Normal mengacu pada tindakan mengambil arsitektur database dan menerapkan seperangkat kriteria dan aturan formal untuk itu. Proses normalisasi diklasifikasikan sebagai berikut: Bentuk Normal Pertama (1 NF), Bentuk Normal Kedua (2 NF), Bentuk Normal Ketiga (3 NF), Bentuk Normal Boyce Codd atau Bentuk Normal Keempat ( BCNF atau 4 NF), Bentuk Normal Kelima (5 NF), dan Bentuk Normal Keenam (6 NF) (6 NF).
Apa itu Normalisasi Min-Max?
Salah satu metode yang paling umum untuk normalisasi data adalah min-max Normalization. Untuk setiap fitur, nilai minimum dikonversi ke 0, nilai tertinggi dikonversi ke 1, dan semua nilai lainnya dikonversi ke desimal antara 0 dan 1. Misalnya, jika nilai minimum fitur adalah 20 dan nilai tertinggi adalah 40, 30 akan dikonversi menjadi sekitar 0,5 karena berada di tengah antara 20 dan 40. Salah satu kelemahan signifikan dari Normalisasi min-max adalah ia tidak menangani outlier dengan baik. Misalnya, jika Anda memiliki 99 nilai mulai dari 0 hingga 40, dan salah satunya adalah 100, semua 99 nilai akan dikonversi ke nilai mulai dari 0 hingga 0,4.