
Qu'est-ce que la normalisation dans l'exploration de données et comment le faire ?
Publié: 2020-11-23Les entreprises s'appuient de plus en plus sur les données pour en savoir plus sur leurs clients. Ainsi, les analystes de données ont une plus grande responsabilité d'explorer et d'analyser de grands blocs de données brutes et d'en extraire des tendances et des modèles significatifs de clients. C'est ce qu'on appelle l'exploration de données. Les analystes de données utilisent des techniques d'exploration de données, des analyses statistiques avancées et des technologies de visualisation de données pour obtenir de nouvelles informations.
Ceux-ci peuvent aider une entreprise à développer des stratégies de marketing efficaces pour améliorer les performances de l'entreprise, augmenter les ventes et réduire les frais généraux. Bien qu'il existe des outils et des algorithmes pour l'exploration de données, ce n'est pas une mince affaire, car les données du monde réel sont hétérogènes. Ainsi, il existe de nombreux défis en matière d'exploration de données. Apprenez la science des données si vous souhaitez acquérir une expertise dans l'exploration de données.
L'un des défis courants est que, généralement, les bases de données contiennent des attributs d'unités, de plages et d'échelles différentes. L'application d'algorithmes à des données aussi étendues peut ne pas fournir de résultats précis. Cela appelle à la normalisation des données dans l'exploration de données .
C'est un processus nécessaire pour normaliser des données hétérogènes. Les données peuvent être placées dans une plage plus petite, telle que 0,0 à 1,0 ou -1,0 à 1,0. En termes simples, la normalisation des données facilite la classification et la compréhension des données.
Table des matières
Pourquoi la normalisation dans l'exploration de données est-elle nécessaire ?
La normalisation des données est principalement nécessaire pour minimiser ou exclure les données en double. La duplicité des données est un problème critique. En effet, il est de plus en plus problématique de stocker des données dans des bases de données relationnelles, en conservant des données identiques à plusieurs endroits. La normalisation dans l'exploration de données est une procédure bénéfique car elle permet d'obtenir certains avantages, comme indiqué ci-dessous :
- Il est beaucoup plus facile d'appliquer des algorithmes d'exploration de données sur un ensemble de données normalisées.
- Les résultats des algorithmes d'exploration de données appliqués à un ensemble de données normalisées sont plus précis et efficaces.
- Une fois les données normalisées, l'extraction des données des bases de données devient beaucoup plus rapide.
- Des méthodes d'analyse de données plus spécifiques peuvent être appliquées à des données normalisées.
Lire : Techniques d'exploration de données
3 techniques populaires pour la normalisation des données dans l'exploration de données
Il existe trois méthodes populaires pour effectuer la normalisation dans l'exploration de données . Ils comprennent:
Normalisation Min Max
Ce qui est plus facile à comprendre – la différence entre 200 et 1000000 ou la différence entre 0,2 et 1. En effet, lorsque la différence entre les valeurs minimale et maximale est moindre, les données deviennent plus lisibles. La normalisation min-max fonctionne en convertissant une plage de données en une échelle allant de 0 à 1.
Formule de normalisation Min-Max
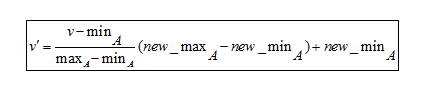
Pour comprendre la formule, voici un exemple. Supposons qu'une entreprise veuille décider d'une promotion en fonction des années d'expérience professionnelle de ses employés. Il doit donc analyser une base de données qui ressemble à ceci :
| Nom de l'employé | des années d'expérience |
| abc | 8 |
| XYZ | 20 |
| PQR | dix |
| ORM | 15 |
- La valeur minimale est 8
- La valeur maximale est de 20
Comme cette formule met les données à l'échelle entre 0 et 1,
- Le nouveau min est 0
- Le nouveau maximum est 1
Ici, V représente la valeur respective de l'attribut, c'est-à-dire 8, 10, 15, 20
Après application de la formule de normalisation min-max, voici les valeurs V' des attributs :
- Pour 8 ans d'expérience : v'= 0
- Pour 10 ans d'expérience : v' = 0,16
- Pour 15 ans d'expérience : v' = 0,58
- Pour 20 ans d'expérience : v' = 1
Ainsi, la normalisation min-max peut réduire les grands nombres à des valeurs beaucoup plus petites. Cela rend extrêmement facile la lecture de la différence entre les nombres allant.
Normalisation de l'échelle décimale
La mise à l'échelle décimale est une autre technique de normalisation dans l'exploration de données . Il fonctionne en convertissant un nombre en un point décimal.
Formule de mise à l'échelle décimale
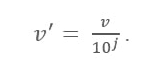
Ici:
- V' est la nouvelle valeur après application de la mise à l'échelle décimale
- V est la valeur respective de l'attribut
Maintenant, l'entier J définit le mouvement des points décimaux. Alors, comment le définir ? Il est égal au nombre de chiffres présents dans la valeur maximale de la table de données. Voici un exemple:

Supposons qu'une entreprise veuille comparer les salaires des nouveaux entrants. Voici les valeurs des données :
| Nom de l'employé | Un salaire |
| abc | 10 000 |
| XYZ | 25 000 |
| PQR | 8 000 |
| ORM | 15 000 |
Maintenant, recherchez la valeur maximale dans les données. Dans ce cas, c'est 25 000. Comptez maintenant le nombre de chiffres dans cette valeur. Dans ce cas, c'est '5'. Donc ici 'j' est égal à 5, c'est-à-dire 100 000. Cela signifie que le V (valeur de l'attribut) doit être divisé par 100 000 ici.
Après avoir appliqué la formule de mise à l'échelle zéro décimale, voici les nouvelles valeurs :
| Nom | Un salaire | Salaire après mise à l'échelle décimale |
| abc | 10 000 | 0,1 |
| XYZ | 25 000 | 0,25 |
| PQR | 8 000 | 0,08 |
| ORM | 15 000 | 0,15 |
Ainsi, la mise à l'échelle décimale peut atténuer les grands nombres en valeurs décimales plus petites faciles à comprendre. De plus, les données attribuées à différentes unités deviennent faciles à lire et à comprendre une fois qu'elles sont converties en valeurs décimales plus petites.
Doit lire: Idées et sujets de projet d'exploration de données
Normalisation du score Z
La valeur Z-Score consiste à comprendre à quel point le point de données est éloigné de la moyenne. Techniquement, il mesure les écarts types au-dessous ou au-dessus de la moyenne. Il varie de -3 écart type à +3 écart type. La normalisation du score Z dans l'exploration de données est utile pour les types d'analyse de données dans lesquels il est nécessaire de comparer une valeur par rapport à une valeur moyenne (moyenne), comme les résultats de tests ou d'enquêtes.
Par exemple, le poids d'une personne est de 150 livres. Maintenant, s'il est nécessaire de comparer cette valeur avec le poids moyen d'une population répertoriée dans un vaste tableau de données, la normalisation du score Z est nécessaire pour étudier ces valeurs, en particulier si le poids d'une personne est enregistré en kilogrammes.
Conclusion
Comme les données proviennent de différentes sources, il est très courant d'avoir des attributs différents dans un lot de données. Ainsi, la normalisation dans l'exploration de données s'apparente au prétraitement et à la préparation des données pour l'analyse.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1 -on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Qu'entend-on par normalisation dans l'exploration de données ?
La normalisation est le processus de mise à l'échelle des données d'un attribut de manière à ce qu'elles se situent dans une plage plus étroite, comme -1,0 à 1,0 ou 0,0 à 1,0. Il est bénéfique pour les algorithmes de classification en général. La normalisation est généralement nécessaire lorsqu'il s'agit de caractéristiques à différentes échelles ; sinon, cela peut diluer l'efficacité d'un attribut tout aussi significatif sur une échelle inférieure en raison d'autres attributs ayant des valeurs sur une plus grande échelle. En d'autres termes, lorsque de nombreuses caractéristiques existent mais que leurs valeurs sont à différentes échelles, cela peut entraîner des modèles de données inadéquats lors des activités d'exploration de données. En conséquence, ils sont normalisés pour mettre toutes les caractéristiques sur la même échelle.
Quels sont les différents types de normalisation ?
La normalisation est une procédure qui doit être suivie pour chaque base de données que vous créez. Les formes normales font référence à l'acte de prendre une architecture de base de données et d'y appliquer un ensemble de critères et de règles formels. Le processus de normalisation est classé comme suit : première forme normale (1 NF), deuxième forme normale (2 NF), troisième forme normale (3 NF), forme normale Boyce Codd ou quatrième forme normale (BCNF ou 4 NF), cinquième forme normale (5 NF) et sixième forme normale (6 NF) (6 NF).
Qu'est-ce que la normalisation Min-Max ?
L'une des méthodes les plus répandues pour normaliser les données est la normalisation min-max. Pour chaque caractéristique, la valeur minimale est convertie en 0, la valeur la plus élevée est convertie en 1 et toutes les autres valeurs sont converties en un nombre décimal compris entre 0 et 1. Par exemple, si la valeur minimale d'une caractéristique était de 20 et que la la valeur la plus élevée était de 40, 30 serait converti en environ 0,5 puisqu'il se situe à mi-chemin entre 20 et 40. Un inconvénient important de la normalisation min-max est qu'elle ne gère pas bien les valeurs aberrantes. Par exemple, si vous avez 99 valeurs comprises entre 0 et 40, et que l'une d'entre elles vaut 100, les 99 valeurs seront toutes converties en valeurs comprises entre 0 et 0,4.