
什么是数据挖掘中的规范化以及如何做到这一点?
已发表: 2020-11-23公司越来越依赖数据来更多地了解他们的客户。 因此,数据分析师有更大的责任去探索和分析大量的原始数据,并从中收集有意义的客户趋势和模式。 这被称为数据挖掘。 数据分析师使用数据挖掘技术、高级统计分析和数据可视化技术来获得新的见解。
这些可以帮助企业制定有效的营销策略,以提高业务绩效、扩大销售规模并降低间接成本。 尽管有数据挖掘的工具和算法,但这并不是小菜一碟,因为现实世界的数据是异构的。 因此,在数据挖掘方面存在相当多的挑战。 如果您想获得数据挖掘方面的专业知识,请学习数据科学。
常见的挑战之一是,数据库通常包含不同单位、范围和尺度的属性。 将算法应用于如此广泛的数据可能无法提供准确的结果。 这就要求数据挖掘中的数据规范化。
这是对异构数据进行规范化的必要过程。 数据可以放在更小的范围内,例如 0.0 到 1.0 或 -1.0 到 1.0。 简单来说,数据规范化使数据更容易分类和理解。
目录
为什么需要数据挖掘中的规范化?
数据归一化主要用于最小化或排除重复数据。 数据的重复性是一个关键问题。 这是因为将数据存储在关系数据库中越来越成问题,将相同的数据保存在多个位置。 数据挖掘中的规范化是一个有益的过程,因为它可以实现如下所述的某些优点:
- 在一组标准化数据上应用数据挖掘算法要容易得多。
- 数据挖掘算法应用于一组标准化数据的结果更加准确和有效。
- 一旦数据被规范化,从数据库中提取数据就会变得更快。
- 更具体的数据分析方法可以应用于标准化数据。
阅读:数据挖掘技术
数据挖掘中数据规范化的 3 种流行技术
在数据挖掘中进行规范化有三种流行的方法。 它们包括:
最小最大归一化
更容易理解的是 200 和 1000000 之间的差异或 0.2 和 1 之间的差异。确实,当最小值和最大值之间的差异较小时,数据变得更具可读性。 最小-最大归一化通过将数据范围转换为范围从 0 到 1 的尺度来发挥作用。
最小-最大归一化公式
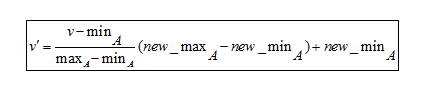
为了理解这个公式,这里有一个例子。 假设一家公司想根据员工的工作年限来决定升职。 因此,它需要分析一个如下所示的数据库:
| 员工姓名 | 多年经验 |
| 美国广播公司 | 8 |
| XYZ | 20 |
| 二维码 | 10 |
| 移动网络运营商 | 15 |
- 最小值为 8
- 最大值为 20
由于此公式在 0 和 1 之间缩放数据,
- 新的最小值为 0
- 新的最大值为 1
这里,V代表属性的相应值,即8、10、15、20
应用 min-max 归一化公式后,以下是属性的V'值:
- 对于 8 年的经验: v'= 0
- 对于 10 年的经验: v' = 0.16
- 对于 15 年的经验: v' = 0.58
- 对于 20 年的经验: v' = 1
因此,最小-最大归一化可以将大数字减少到小得多的值。 这使得读取测距数字之间的差异变得非常容易。
十进制标度归一化
十进制缩放是数据挖掘中的另一种规范化技术。 它通过将数字转换为小数点来发挥作用。
十进制缩放公式
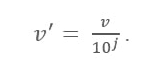
这里:
- V' 是应用小数缩放后的新值
- V是属性的各自值
现在,整数 J 定义了小数点的移动。 那么,如何定义呢? 它等于数据表中最大值中存在的位数。 这是一个例子:

假设一家公司想要比较新员工的薪水。 以下是数据值:
| 员工姓名 | 薪水 |
| 美国广播公司 | 10,000 |
| XYZ | 25,000 |
| 二维码 | 8,000 |
| 移动网络运营商 | 15,000 |
现在,寻找数据中的最大值。 在这种情况下,它是 25,000。 现在计算这个值的位数。 在这种情况下,它是“5”。 所以这里的'j'等于5,即100,000。 这意味着这里的 V(属性值)需要除以 100,000。
应用零十进制缩放公式后,以下是新值:
| 姓名 | 薪水 | 十进制缩放后的薪水 |
| 美国广播公司 | 10,000 | 0.1 |
| XYZ | 25, 000 | 0.25 |
| 二维码 | 8, 000 | 0.08 |
| 移动网络运营商 | 15,000 | 0.15 |
因此,十进制缩放可以将大数字淡化为易于理解的较小十进制值。 此外,归属于不同单位的数据一旦转换为较小的十进制值,就会变得易于阅读和理解。
必读:数据挖掘项目的想法和主题
Z 分数归一化
Z-Score 值是为了了解数据点与平均值的距离。 从技术上讲,它测量低于或高于平均值的标准偏差。 它的范围从 -3 标准偏差到 +3 标准偏差。 数据挖掘中的Z-score归一化对于需要比较一个值与平均值(例如来自测试或调查的结果)的那些类型的数据分析很有用。
例如,一个人的体重是 150 磅。 现在,如果需要将该值与大量数据表中列出的人群的平均体重进行比较,则需要对这些值进行 Z-score 标准化来研究这些值,尤其是当某人的体重以千克为单位时。
结论
由于数据来自不同的来源,因此在任何一批数据中具有不同的属性是很常见的。 因此,数据挖掘中的规范化就像预处理和准备数据以供分析。
如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、行业专家的指导、1与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
数据挖掘中的规范化是什么意思?
规范化是对属性数据进行缩放以使其落在更窄范围内的过程,例如 -1.0 到 1.0 或 0.0 到 1.0。 一般来说,它对分类算法是有益的。 在处理各种尺度的特征时,通常需要归一化; 否则,由于其他属性具有更大范围的值,它可能会在较小范围内稀释同等重要属性的功效。 换句话说,当存在许多特征但它们的值在不同的尺度上时,这可能会导致在进行数据挖掘活动时数据模型不足。 结果,它们被归一化以将所有特征放在同一尺度上。
归一化有哪些不同类型?
规范化是您创建的每个数据库都应遵循的过程。 范式是指采用数据库架构并向其应用一组正式标准和规则的行为。 归一化过程分类如下:第一范式(1 NF),第二范式(2 NF),第三范式(3 NF),博伊斯科德范式或第四范式(BCNF或4 NF),第五范式(5 NF) 和第六范式 (6 NF) (6 NF)。
什么是最小-最大归一化?
标准化数据最流行的方法之一是最小-最大标准化。 对于每个特征,最小值转换为 0,最大值转换为 1,所有其他值转换为 0 到 1 之间的小数。例如,如果特征的最小值为 20,则最高值为 40,30 将转换为大约 0.5,因为它介于 20 和 40 之间。最小-最大归一化的一个重要缺点是它不能很好地处理异常值。 例如,如果您有 0 到 40 范围内的 99 个值,其中一个是 100,则所有 99 个值都将转换为 0 到 0.4 范围内的值。