
Was ist Normalisierung beim Data Mining und wie geht das?
Veröffentlicht: 2020-11-23Unternehmen verlassen sich zunehmend auf Daten, um mehr über ihre Kunden zu erfahren. Daher haben Datenanalysten eine größere Verantwortung, große Blöcke von Rohdaten zu untersuchen und zu analysieren und daraus aussagekräftige Kundentrends und -muster abzuleiten. Dies wird als Data-Mining bezeichnet. Datenanalysten verwenden Data-Mining-Techniken, fortschrittliche statistische Analysen und Datenvisualisierungstechnologien, um neue Erkenntnisse zu gewinnen.
Diese können einem Unternehmen helfen, effektive Marketingstrategien zu entwickeln, um die Geschäftsleistung zu verbessern, den Umsatz zu steigern und die Gemeinkosten zu senken. Obwohl es Tools und Algorithmen für das Data Mining gibt, ist es kein Zuckerschlecken, da reale Daten heterogen sind. Es gibt also einige Herausforderungen, wenn es um Data Mining geht. Lernen Sie Data Science, wenn Sie sich Fachwissen im Bereich Data Mining aneignen möchten.
Eine der häufigsten Herausforderungen besteht darin, dass Datenbanken normalerweise Attribute mit unterschiedlichen Einheiten, Bereichen und Maßstäben enthalten. Das Anwenden von Algorithmen auf solch drastisch reichende Daten liefert möglicherweise keine genauen Ergebnisse. Dies erfordert eine Datennormalisierung im Data Mining .
Es ist ein notwendiger Prozess, der erforderlich ist, um heterogene Daten zu normalisieren. Daten können in einen kleineren Bereich wie 0,0 bis 1,0 oder -1,0 bis 1,0 gelegt werden. Mit einfachen Worten, die Datennormalisierung macht Daten leichter zu klassifizieren und zu verstehen.
Inhaltsverzeichnis
Warum ist eine Normalisierung im Data Mining erforderlich?
Die Datennormalisierung wird hauptsächlich benötigt, um doppelte Daten zu minimieren oder auszuschließen. Doppelte Daten sind ein kritisches Problem. Denn es wird immer problematischer, Daten in relationalen Datenbanken zu speichern und identische Daten an mehr als einem Ort aufzubewahren. Die Normalisierung im Data Mining ist ein nützliches Verfahren, da es die Erzielung bestimmter Vorteile ermöglicht, wie unten erwähnt:
- Es ist viel einfacher, Data-Mining-Algorithmen auf einen Satz normalisierter Daten anzuwenden.
- Die Ergebnisse von Data-Mining-Algorithmen, die auf einen Satz normalisierter Daten angewendet werden, sind genauer und effektiver.
- Sobald die Daten normalisiert sind, wird die Extraktion von Daten aus Datenbanken viel schneller.
- Spezifischere Datenanalyseverfahren können auf normalisierte Daten angewendet werden.
Lesen Sie: Data-Mining-Techniken
3 beliebte Techniken zur Datennormalisierung im Data Mining
Es gibt drei gängige Methoden zur Durchführung der Normalisierung im Data Mining . Sie beinhalten:
Min-Max-Normalisierung
Was leichter zu verstehen ist – der Unterschied zwischen 200 und 1000000 oder der Unterschied zwischen 0,2 und 1. Tatsächlich werden die Daten besser lesbar, wenn der Unterschied zwischen den Mindest- und Höchstwerten geringer ist. Die Min-Max-Normalisierung funktioniert, indem sie einen Datenbereich in eine Skala umwandelt, die von 0 bis 1 reicht.
Min-Max-Normalisierungsformel
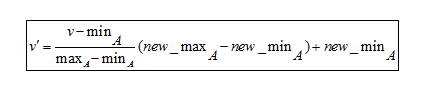
Um die Formel zu verstehen, hier ein Beispiel. Angenommen, ein Unternehmen möchte auf der Grundlage der langjährigen Berufserfahrung seiner Mitarbeiter über eine Beförderung entscheiden. Es muss also eine Datenbank analysiert werden, die so aussieht:
| Mitarbeitername | Langjährige Erfahrung |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | fünfzehn |
- Der Mindestwert ist 8
- Der Maximalwert ist 20
Da diese Formel die Daten zwischen 0 und 1 skaliert,
- Das neue Minimum ist 0
- Das neue Maximum ist 1
Dabei steht V für den jeweiligen Wert des Attributs, also 8, 10, 15, 20
Nach Anwendung der Min-Max-Normalisierungsformel sind die folgenden V'- Werte für die Attribute:
- Für 8 Jahre Erfahrung: v'= 0
- Für 10 Jahre Erfahrung: v' = 0,16
- Für 15 Jahre Erfahrung: v' = 0,58
- Für 20 Jahre Erfahrung: v' = 1
Die Min-Max-Normalisierung kann also große Zahlen auf viel kleinere Werte reduzieren. Dies macht es extrem einfach, den Unterschied zwischen den Bereichsnummern zu lesen.
Normalisierung der Dezimalskalierung
Die Dezimalskalierung ist eine weitere Technik zur Normalisierung beim Data Mining . Es funktioniert, indem es eine Zahl in einen Dezimalpunkt umwandelt.
Dezimale Skalierungsformel
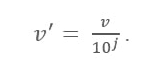
Hier:
- V' ist der neue Wert nach Anwendung der Dezimalskalierung
- V ist der jeweilige Wert des Attributs
Jetzt definiert die Ganzzahl J die Bewegung von Dezimalpunkten. Also, wie definiert man es? Sie ist gleich der Anzahl der Stellen, die im Maximalwert in der Datentabelle vorhanden sind. Hier ist ein Beispiel:

Angenommen, ein Unternehmen möchte die Gehälter der neuen Mitarbeiter vergleichen. Hier die Datenwerte:
| Mitarbeitername | Gehalt |
| ABC | 10.000 |
| XYZ | 25.000 |
| PQR | 8.000 |
| MNO | 15.000 |
Suchen Sie nun nach dem Maximalwert in den Daten. In diesem Fall sind es 25.000. Zählen Sie nun die Anzahl der Stellen in diesem Wert. In diesem Fall ist es „5“. Hier ist 'j' also gleich 5, also 100.000. Das bedeutet, dass hier das V (Wert des Attributs) durch 100.000 geteilt werden muss.
Nach Anwendung der Null-Dezimal-Skalierungsformel sind hier die neuen Werte:
| Name | Gehalt | Gehalt nach Dezimalskalierung |
| ABC | 10.000 | 0,1 |
| XYZ | 25.000 | 0,25 |
| PQR | 8.000 | 0,08 |
| MNO | 15.000 | 0,15 |
Daher kann die Dezimalskalierung große Zahlen in leicht verständliche kleinere Dezimalwerte abschwächen. Außerdem werden Daten, die verschiedenen Einheiten zugeordnet sind, leicht lesbar und verständlich, wenn sie in kleinere Dezimalwerte umgewandelt werden.
Muss gelesen werden: Ideen und Themen für Data-Mining-Projekte
Z-Score-Normalisierung
Der Z-Score-Wert gibt an, wie weit der Datenpunkt vom Mittelwert entfernt ist. Technisch misst es die Standardabweichungen unter oder über dem Mittelwert. Sie reicht von -3 Standardabweichung bis zu +3 Standardabweichung. Die Z-Score- Normalisierung beim Data Mining ist nützlich für solche Arten von Datenanalysen, bei denen ein Wert mit einem Mittelwert (Durchschnittswert) verglichen werden muss, z. B. Ergebnissen aus Tests oder Umfragen.
Beispielsweise beträgt das Gewicht einer Person 150 Pfund. Wenn es nun notwendig ist, diesen Wert mit dem Durchschnittsgewicht einer Bevölkerung zu vergleichen, die in einer riesigen Datentabelle aufgeführt ist, ist eine Z-Score-Normalisierung erforderlich, um solche Werte zu untersuchen, insbesondere wenn das Gewicht einer Person in Kilogramm aufgezeichnet wird.
Fazit
Da Daten aus unterschiedlichen Quellen stammen, ist es sehr üblich, dass jeder Datenstapel unterschiedliche Attribute enthält. Somit ist die Normalisierung im Data Mining wie die Vorverarbeitung und Vorbereitung der Daten für die Analyse.
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1 -on-1 mit Branchenmentoren, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was versteht man unter Normalisierung im Data Mining?
Bei der Normalisierung werden die Daten eines Attributs so skaliert, dass sie in einen engeren Bereich fallen, z. B. -1,0 bis 1,0 oder 0,0 bis 1,0. Dies ist im Allgemeinen für Klassifizierungsalgorithmen von Vorteil. Normalisierung ist typischerweise notwendig, wenn es um Merkmale auf verschiedenen Skalen geht; Andernfalls kann es die Wirksamkeit eines gleich signifikanten Attributs auf einer niedrigeren Skala verwässern, da andere Attribute Werte auf einer größeren Skala haben. Mit anderen Worten, wenn zahlreiche Merkmale vorhanden sind, deren Werte jedoch auf unterschiedlichen Skalen liegen, kann dies bei Data-Mining-Aktivitäten zu unangemessenen Datenmodellen führen. Als Ergebnis werden sie normalisiert, um alle Merkmale auf die gleiche Skala zu bringen.
Was sind die verschiedenen Arten der Normalisierung?
Die Normalisierung ist ein Verfahren, das für jede von Ihnen erstellte Datenbank befolgt werden sollte. Normalformen beziehen sich auf den Vorgang, eine Datenbankarchitektur zu übernehmen und eine Reihe formaler Kriterien und Regeln darauf anzuwenden. Der Normalisierungsprozess wird wie folgt klassifiziert: Erste Normalform (1 NF), Zweite Normalform (2 NF), Dritte Normalform (3 NF), Boyce-Codd-Normalform oder Vierte Normalform (BCNF oder 4 NF), Fünfte Normalform (5 NF) und Sechste Normalform (6 NF) (6 NF).
Was ist Min-Max-Normalisierung?
Eine der am weitesten verbreiteten Methoden zur Normalisierung von Daten ist die Min-Max-Normalisierung. Für jedes Merkmal wird der Mindestwert in 0 umgewandelt, der höchste Wert wird in 1 umgewandelt und alle anderen Werte werden in eine Dezimalzahl zwischen 0 und 1 umgewandelt. Wenn der Mindestwert eines Merkmals beispielsweise 20 war und die Der höchste Wert war 40, 30 würde in etwa 0,5 konvertiert werden, da er in der Mitte zwischen 20 und 40 liegt. Ein wesentlicher Nachteil der Min-Max-Normalisierung besteht darin, dass sie Ausreißer nicht gut handhabt. Wenn Sie beispielsweise 99 Werte im Bereich von 0 bis 40 haben und einer davon 100 ist, werden alle 99 Werte in Werte im Bereich von 0 bis 0,4 konvertiert.