
データマイニングの正規化とは何ですか?その方法は?
公開: 2020-11-23企業は、顧客について詳しく知るためにデータにますます依存するようになっています。 したがって、データアナリストは、生データの大きなブロックを調査および分析し、そこから意味のある顧客の傾向とパターンを収集するという大きな責任を負っています。 これはデータマイニングとして知られています。 データアナリストは、データマイニング技術、高度な統計分析、およびデータ視覚化テクノロジーを使用して、新しい洞察を獲得します。
これらは、ビジネスが業績を改善し、売上を拡大し、間接費を削減するための効果的なマーケティング戦略を開発するのに役立ちます。 データマイニング用のツールとアルゴリズムはありますが、実際のデータは異種であるため、簡単なことではありません。 したがって、データマイニングに関しては、かなりの数の課題があります。 データマイニングの専門知識を習得したい場合は、データサイエンスを学びましょう。
一般的な課題の1つは、通常、データベースにさまざまな単位、範囲、およびスケールの属性が含まれていることです。 このような大幅な範囲のデータにアルゴリズムを適用すると、正確な結果が得られない場合があります。 これには、データマイニングでのデータの正規化が必要です。
異種データを正規化するために必要なプロセスです。 データは、0.0から1.0または-1.0から1.0などのより狭い範囲に入れることができます。 簡単に言うと、データの正規化により、データの分類と理解が容易になります。
目次
データマイニングで正規化が必要なのはなぜですか?
データの正規化は、主に重複データを最小化または除外するために必要です。 データの重複は重大な問題です。 これは、データをリレーショナルデータベースに保存し、同一のデータを複数の場所に保持することがますます問題になるためです。 データマイニングの正規化は、以下に説明する特定の利点を実現できるため、有益な手順です。
- 正規化されたデータのセットにデータマイニングアルゴリズムを適用する方がはるかに簡単です。
- 正規化されたデータのセットに適用されたデータマイニングアルゴリズムの結果は、より正確で効果的です。
- データが正規化されると、データベースからのデータの抽出がはるかに高速になります。
- より具体的なデータ分析方法は、正規化されたデータに適用できます。
読む:データマイニング技術
データマイニングにおけるデータ正規化のための3つの一般的な手法
データマイニングで正規化を実行するには、3つの一般的な方法があります。 それらが含まれます:
最小最大正規化
理解しやすいこと– 200と1000000の差、または0.2と1の差。実際、最小値と最大値の差が小さいほど、データが読みやすくなります。 min-max正規化は、データの範囲を0から1の範囲のスケールに変換することによって機能します。
最小-最大正規化式
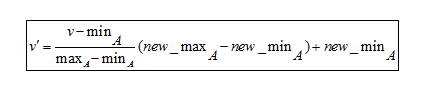
式を理解するために、ここに例があります。 会社が従業員の長年の実務経験に基づいて昇進を決定したいとします。 したがって、次のようなデータベースを分析する必要があります。
| 従業員名 | 長年の経験 |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | 15 |
- 最小値は8です
- 最大値は20です
この式はデータを0から1の間でスケーリングするため、
- 新しい最小値は0です
- 新しい最大値は1です
ここで、Vは属性のそれぞれの値、つまり8、10、15、20を表します。
min-max正規化式を適用した後、属性のV'値は次のようになります。
- 8年間の経験: v'= 0
- 10年の経験: v'= 0.16
- 15年の経験: v'= 0.58
- 20年の経験: v'= 1
したがって、最小-最大正規化により、大きな数をはるかに小さな値に減らすことができます。 これにより、レンジング番号の違いを非常に簡単に読み取ることができます。
10進スケーリングの正規化
10進スケーリングは、データマイニングで正規化するためのもう1つの手法です。 数値を小数点に変換して機能します。
10進スケーリング式
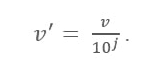
ここ:
- V'は、10進スケーリングを適用した後の新しい値です
- Vは属性のそれぞれの値です
ここで、整数Jは小数点の移動を定義します。 それで、それをどのように定義するのですか? これは、データテーブルの最大値に存在する桁数と同じです。 次に例を示します。

会社が新しい参加者の給与を比較したいとします。 データ値は次のとおりです。
| 従業員名 | 給料 |
| ABC | 10,000 |
| XYZ | 25,000 |
| PQR | 8,000 |
| MNO | 15,000 |
ここで、データの最大値を探します。 この場合、25,000です。 次に、この値の桁数を数えます。 この場合は「5」です。 したがって、ここで「j」は5、つまり100,000に等しくなります。 これは、V(属性の値)をここで100,000で割る必要があることを意味します。
ゼロ小数スケーリング式を適用した後、新しい値は次のとおりです。
| 名前 | 給料 | 10進スケーリング後の給与 |
| ABC | 10,000 | 0.1 |
| XYZ | 25、000 | 0.25 |
| PQR | 8、000 | 0.08 |
| MNO | 15,000 | 0.15 |
したがって、10進スケーリングでは、大きな数値をトーンダウンして、理解しやすい小さな10進値にすることができます。 また、異なる単位に起因するデータは、小さい10進値に変換されると、読みやすく、理解しやすくなります。
必読:データマイニングプロジェクトのアイデアとトピック
Zスコアの正規化
Zスコア値は、データポイントが平均からどれだけ離れているかを理解するためのものです。 技術的には、平均より下または上の標準偏差を測定します。 -3標準偏差から+3標準偏差までの範囲です。 データマイニングのZスコアの正規化は、テストや調査の結果など、平均(平均)値に対して値を比較する必要がある種類のデータ分析に役立ちます。
たとえば、人の体重は150ポンドです。 現在、その値を膨大なデータの表にリストされている母集団の平均体重と比較する必要がある場合、特に誰かの体重がキログラムで記録されている場合は、そのような値を調べるためにZスコアの正規化が必要です。
結論
データはさまざまなソースから取得されるため、データのバッチごとにさまざまな属性を持つことが非常に一般的です。 したがって、データマイニングの正規化は、分析用のデータを前処理して準備するようなものです。
データサイエンスについて知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
データマイニングの正規化とはどういう意味ですか?
正規化は、属性のデータを-1.0から1.0または0.0から1.0などのより狭い範囲内に収まるようにスケーリングするプロセスです。 これは、一般的な分類アルゴリズムにとって有益です。 さまざまなスケールの特性を処理する場合、通常、正規化が必要です。 そうしないと、他の属性がより大きなスケールで値を持っているために、より低いスケールで同じように重要な属性の有効性が薄れる可能性があります。 つまり、多数の特性が存在するが、それらの値がさまざまなスケールである場合、データマイニングアクティビティを実行するときにデータモデルが不十分になる可能性があります。 結果として、それらはすべての特性を同じスケールに置くように正規化されます。
正規化のさまざまなタイプは何ですか?
正規化は、作成するデータベースごとに従う必要のある手順です。 正規形とは、データベースアーキテクチャを採用し、それに一連の正式な基準とルールを適用する行為を指します。 正規化プロセスは次のように分類されます:第1正規形(1 NF)、第2正規形(2 NF)、第3正規形(3 NF)、ボイスコッド正規形または第4正規形(BCNFまたは4 NF)、第5正規形(5 NF)、および第6正規形(6 NF)(6 NF)。
最小-最大正規化とは何ですか?
データを正規化するための最も一般的な方法の1つは、最小-最大正規化です。 各フィーチャについて、最小値は0に変換され、最大値は1に変換され、他のすべての値は0〜1の小数に変換されます。たとえば、フィーチャの最小値が20で、最高値は40でしたが、20と40の中間であるため、30は約0.5に変換されます。min-max正規化の重大な欠点の1つは、外れ値を適切に処理できないことです。 たとえば、0から40の範囲の99個の値があり、そのうちの1つが100の場合、99個の値すべてが0から0.4の範囲の値に変換されます。