
Что такое нормализация в интеллектуальном анализе данных и как это сделать?
Опубликовано: 2020-11-23Компании все чаще полагаются на данные, чтобы узнать больше о своих клиентах. Таким образом, аналитики данных несут большую ответственность за изучение и анализ больших блоков необработанных данных и извлечение из них значимых клиентских тенденций и моделей. Это известно как интеллектуальный анализ данных. Аналитики данных используют методы интеллектуального анализа данных, расширенный статистический анализ и технологии визуализации данных, чтобы получить новые идеи.
Это может помочь бизнесу разработать эффективные маркетинговые стратегии для повышения эффективности бизнеса, увеличения продаж и снижения накладных расходов. Хотя существуют инструменты и алгоритмы для интеллектуального анализа данных, это не легкая прогулка, поскольку данные реального мира неоднородны. Таким образом, существует довольно много проблем, когда дело доходит до интеллектуального анализа данных. Изучите науку о данных, если вы хотите получить опыт в области интеллектуального анализа данных.
Одна из распространенных проблем заключается в том, что базы данных обычно содержат атрибуты с различными единицами измерения, диапазонами и масштабами. Применение алгоритмов к таким сильно разбросанным данным может не дать точных результатов. Это требует нормализации данных при интеллектуальном анализе данных .
Это необходимый процесс, необходимый для нормализации разнородных данных. Данные могут быть помещены в меньший диапазон, например, от 0,0 до 1,0 или от -1,0 до 1,0. Проще говоря, нормализация данных упрощает их классификацию и понимание.
Оглавление
Зачем нужна нормализация в интеллектуальном анализе данных?
Нормализация данных в основном необходима для минимизации или исключения повторяющихся данных. Дублирование данных является критической проблемой. Это связано с тем, что становится все труднее хранить данные в реляционных базах данных, сохраняя идентичные данные более чем в одном месте. Нормализация в интеллектуальном анализе данных является полезной процедурой, поскольку она позволяет достичь определенных преимуществ, как указано ниже:
- Гораздо проще применять алгоритмы интеллектуального анализа данных к набору нормализованных данных.
- Результаты применения алгоритмов интеллектуального анализа данных к набору нормализованных данных являются более точными и эффективными.
- После нормализации данных извлечение данных из баз данных становится намного быстрее.
- К нормализованным данным можно применять более конкретные методы анализа данных.
Читайте: Методы интеллектуального анализа данных
3 популярных метода нормализации данных в интеллектуальном анализе данных
Существует три популярных метода нормализации при интеллектуальном анализе данных . Они включают:
Мин. Макс. Нормализация
Что легче понять — разница между 200 и 1000000 или разница между 0,2 и 1. Действительно, когда разница между минимальным и максимальным значениями меньше, данные становятся более читаемыми. Миномаксная нормализация функционирует путем преобразования диапазона данных в шкалу от 0 до 1.
Формула нормализации минимум-макс.
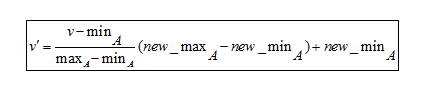
Чтобы понять формулу, вот пример. Предположим, компания хочет принять решение о повышении на основе многолетнего опыта работы своих сотрудников. Итак, ему нужно проанализировать базу данных, которая выглядит так:
| Имя сотрудника | Годы опыта |
| азбука | 8 |
| XYZ | 20 |
| PQR | 10 |
| оператор мобильной связи | 15 |
- Минимальное значение 8
- Максимальное значение – 20.
Поскольку эта формула масштабирует данные от 0 до 1,
- Новый минимум 0
- Новый максимум 1
Здесь V обозначает соответствующее значение атрибута, т. е. 8, 10, 15, 20.
После применения формулы нормализации минимум-максимум значения V' для атрибутов следующие:
- За 8 лет стажа: v'= 0
- За 10 лет опыта: v' = 0,16
- За 15 лет стажа: v' = 0,58
- За 20 лет опыта: v' = 1
Таким образом, нормализация минимум-максимум может уменьшить большие числа до гораздо меньших значений. Это позволяет чрезвычайно легко прочитать разницу между числами ранжирования.
Десятичная нормализация масштабирования
Десятичное масштабирование — еще один метод нормализации при интеллектуальном анализе данных . Он работает путем преобразования числа в десятичную точку.
Десятичная формула масштабирования
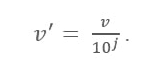
Здесь:
- V' - новое значение после применения десятичного масштабирования.
- V - соответствующее значение атрибута
Теперь целое число J определяет движение десятичных точек. Итак, как это определить? Он равен количеству цифр, присутствующих в максимальном значении в таблице данных. Вот пример:

Предположим, компания хочет сравнить заработную плату новых сотрудников. Вот значения данных:
| Имя сотрудника | Зарплата |
| азбука | 10 000 |
| XYZ | 25000 |
| PQR | 8000 |
| оператор мобильной связи | 15 000 |
Теперь найдите максимальное значение в данных. В данном случае это 25000. Теперь подсчитайте количество цифр в этом значении. В данном случае это «5». Итак, здесь j равно 5, то есть 100 000. Это означает, что здесь V (значение атрибута) нужно разделить на 100 000.
После применения формулы нулевого десятичного масштабирования вот новые значения:
| Имя | Зарплата | Зарплата после десятичной шкалы |
| азбука | 10 000 | 0,1 |
| XYZ | 25 000 | 0,25 |
| PQR | 8 000 | 0,08 |
| оператор мобильной связи | 15 000 | 0,15 |
Таким образом, десятичное масштабирование может смягчить большие числа до простых для понимания меньших десятичных значений. Кроме того, данные, относящиеся к разным единицам измерения, становятся легко читаемыми и понятными после преобразования в меньшие десятичные значения.
Обязательно к прочтению: идеи и темы проекта интеллектуального анализа данных
Нормализация Z-оценки
Значение Z-Score позволяет понять, насколько далеко точка данных от среднего значения. Технически он измеряет стандартные отклонения ниже или выше среднего. Он колеблется от -3 стандартных отклонений до +3 стандартных отклонений. Нормализация Z-оценки при интеллектуальном анализе данных полезна для тех видов анализа данных, в которых необходимо сравнить значение со средним (средним) значением, например результаты тестов или опросов.
Например, вес человека составляет 150 фунтов. Теперь, если есть необходимость сравнить это значение со средним весом населения, указанным в обширной таблице данных, для изучения таких значений необходима нормализация Z-оценки, особенно если чей-то вес записан в килограммах.
Заключение
Поскольку данные поступают из разных источников, очень часто каждый пакет данных имеет разные атрибуты. Таким образом, нормализация в интеллектуальном анализе данных похожа на предварительную обработку и подготовку данных для анализа.
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных , которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Что подразумевается под нормализацией в интеллектуальном анализе данных?
Нормализация — это процесс масштабирования данных атрибута таким образом, чтобы они попадали в более узкий диапазон, например от -1,0 до 1,0 или от 0,0 до 1,0. Это полезно для алгоритмов классификации в целом. Нормализация обычно необходима при работе с характеристиками в различных масштабах; в противном случае это может ослабить эффективность столь же важного атрибута на более низкой шкале из-за других атрибутов, имеющих значения на более высокой шкале. Другими словами, когда существует множество характеристик, но их значения находятся в разных масштабах, это может привести к неадекватным моделям данных при выполнении операций интеллектуального анализа данных. В результате они нормализуются, чтобы поместить все характеристики в одну шкалу.
Какие бывают виды нормализации?
Нормализация — это процедура, которой следует следовать для каждой создаваемой вами базы данных. Обычные формы относятся к акту принятия архитектуры базы данных и применения к ней набора формальных критериев и правил. Процесс нормализации классифицируется следующим образом: первая нормальная форма (1 NF), вторая нормальная форма (2 NF), третья нормальная форма (3 NF), нормальная форма Бойса-Кодда или четвертая нормальная форма (BCNF или 4 NF), пятая нормальная форма. (5 NF) и шестая нормальная форма (6 NF) (6 NF).
Что такое минимальная нормализация?
Одним из наиболее распространенных методов нормализации данных является минимальная нормализация. Для каждого признака минимальное значение преобразуется в 0, максимальное значение преобразуется в 1, а все остальные значения преобразуются в десятичные дроби от 0 до 1. Например, если минимальное значение признака равно 20, а максимальное значение было 40, 30 будет преобразовано примерно в 0,5, поскольку оно находится на полпути между 20 и 40. Одним из существенных недостатков нормализации минимум-максимум является то, что она плохо обрабатывает выбросы. Например, если у вас есть 99 значений в диапазоне от 0 до 40, и одно из них равно 100, все 99 значений будут преобразованы в значения в диапазоне от 0 до 0,4.