
Che cos'è la normalizzazione nel data mining e come eseguirla?
Pubblicato: 2020-11-23Le aziende si affidano sempre più ai dati per saperne di più sui propri clienti. Pertanto, gli analisti di dati hanno la responsabilità maggiore di esplorare e analizzare grandi blocchi di dati grezzi e ricavarne tendenze e modelli significativi dei clienti. Questo è noto come data mining. Gli analisti dei dati utilizzano tecniche di data mining, analisi statistiche avanzate e tecnologie di visualizzazione dei dati per ottenere nuove informazioni.
Questi possono aiutare un'azienda a sviluppare strategie di marketing efficaci per migliorare le prestazioni aziendali, aumentare le vendite e ridurre i costi generali. Sebbene esistano strumenti e algoritmi per il data mining, non è un gioco da ragazzi, poiché i dati del mondo reale sono eterogenei. Pertanto, ci sono alcune sfide quando si tratta di data mining. Impara la scienza dei dati se vuoi acquisire esperienza nel data mining.
Una delle sfide comuni è che, di solito, i database contengono attributi di unità, intervallo e scale diverse. L'applicazione di algoritmi a dati così drastici potrebbe non fornire risultati accurati. Ciò richiede la normalizzazione dei dati nel data mining .
È un processo necessario per normalizzare dati eterogenei. I dati possono essere inseriti in un intervallo più piccolo, ad esempio da 0,0 a 1,0 o da -1,0 a 1,0. In parole semplici, la normalizzazione dei dati rende i dati più facili da classificare e comprendere.
Sommario
Perché è necessaria la normalizzazione nel data mining?
La normalizzazione dei dati è necessaria principalmente per ridurre al minimo o escludere i dati duplicati. La duplicazione dei dati è un problema critico. Questo perché è sempre più problematico archiviare i dati in database relazionali, mantenendo dati identici in più di un luogo. La normalizzazione nel data mining è una procedura vantaggiosa in quanto consente di ottenere alcuni vantaggi, come indicato di seguito:
- È molto più semplice applicare algoritmi di data mining su un insieme di dati normalizzati.
- I risultati degli algoritmi di data mining applicati a un insieme di dati normalizzati sono più accurati ed efficaci.
- Una volta che i dati sono normalizzati, l'estrazione dei dati dai database diventa molto più veloce.
- Metodi di analisi dei dati più specifici possono essere applicati ai dati normalizzati.
Leggi: Tecniche di data mining
3 tecniche popolari per la normalizzazione dei dati nel data mining
Esistono tre metodi popolari per eseguire la normalizzazione nel data mining . Loro includono:
Normalizzazione minima massima
Ciò che è più facile da capire – la differenza tra 200 e 1000000 o la differenza tra 0,2 e 1. Infatti, quando la differenza tra i valori minimo e massimo è minore, i dati diventano più leggibili. La normalizzazione min-max funziona convertendo un intervallo di dati in una scala che va da 0 a 1.
Formula di normalizzazione min-max
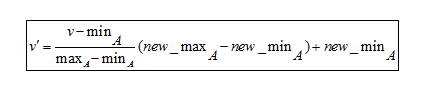
Per capire la formula, ecco un esempio. Supponiamo che un'azienda voglia decidere una promozione sulla base degli anni di esperienza lavorativa dei suoi dipendenti. Quindi, deve analizzare un database simile a questo:
| Nome dipendente | Anni di esperienza |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | 15 |
- Il valore minimo è 8
- Il valore massimo è 20
Poiché questa formula ridimensiona i dati tra 0 e 1,
- Il nuovo minimo è 0
- Il nuovo massimo è 1
Qui, V sta per il rispettivo valore dell'attributo, cioè 8, 10, 15, 20
Dopo aver applicato la formula di normalizzazione min-max, i seguenti sono i valori V' per gli attributi:
- Per 8 anni di esperienza: v'= 0
- Per 10 anni di esperienza: v' = 0,16
- Per 15 anni di esperienza: v' = 0,58
- Per 20 anni di esperienza: v' = 1
Quindi, la normalizzazione min-max può ridurre numeri grandi a valori molto più piccoli. Questo rende estremamente facile leggere la differenza tra i numeri che vanno.
Normalizzazione del ridimensionamento decimale
Il ridimensionamento decimale è un'altra tecnica per la normalizzazione nel data mining . Funziona convertendo un numero in un punto decimale.
Formula di ridimensionamento decimale
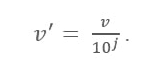
Qui:
- V' è il nuovo valore dopo aver applicato il ridimensionamento decimale
- V è il rispettivo valore dell'attributo
Ora, l'intero J definisce il movimento dei punti decimali. Quindi, come definirlo? È uguale al numero di cifre presenti nel valore massimo nella tabella dati. Ecco un esempio:

Supponiamo che un'azienda voglia confrontare gli stipendi dei nuovi falegnami. Ecco i valori dei dati:
| Nome dipendente | Stipendio |
| ABC | 10.000 |
| XYZ | 25.000 |
| PQR | 8.000 |
| MNO | 15.000 |
Ora, cerca il valore massimo nei dati. In questo caso sono 25.000. Ora conta il numero di cifre in questo valore. In questo caso, è '5'. Quindi qui 'j' è uguale a 5, cioè 100.000. Ciò significa che il V (valore dell'attributo) deve essere diviso per 100.000 qui.
Dopo aver applicato la formula di ridimensionamento decimale zero, ecco i nuovi valori:
| Nome | Stipendio | Stipendio dopo il ridimensionamento decimale |
| ABC | 10.000 | 0.1 |
| XYZ | 25.000 | 0,25 |
| PQR | 8.000 | 0.08 |
| MNO | 15.000 | 0,15 |
Pertanto, il ridimensionamento decimale può attenuare numeri grandi in valori decimali più piccoli di facile comprensione. Inoltre, i dati attribuiti a diverse unità diventano facili da leggere e comprendere una volta convertiti in valori decimali più piccoli.
Da leggere: idee e argomenti per progetti di data mining
Normalizzazione del punteggio Z
Il valore Z-Score serve a capire quanto dista il punto dati dalla media. Tecnicamente, misura le deviazioni standard al di sotto o al di sopra della media. Va da -3 deviazione standard fino a +3 deviazione standard. La normalizzazione del punteggio Z nel data mining è utile per quei tipi di analisi dei dati in cui è necessario confrontare un valore rispetto a un valore medio (medio), come i risultati di test o sondaggi.
Ad esempio, il peso di una persona è di 150 libbre. Ora, se è necessario confrontare quel valore con il peso medio di una popolazione elencata in una vasta tabella di dati, è necessaria la normalizzazione del punteggio Z per studiare tali valori, soprattutto se il peso di qualcuno è registrato in chilogrammi.
Conclusione
Poiché i dati provengono da origini diverse, è molto comune avere attributi diversi in qualsiasi batch di dati. Pertanto, la normalizzazione nel data mining è come la pre-elaborazione e la preparazione dei dati per l'analisi.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al programma Executive PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 -on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Cosa si intende per normalizzazione nel data mining?
La normalizzazione è il processo di ridimensionamento dei dati di un attributo in modo che rientrino in un intervallo più ristretto, ad esempio da -1,0 a 1,0 o da 0,0 a 1,0. È utile per gli algoritmi di classificazione in generale. La normalizzazione è in genere necessaria quando si tratta di caratteristiche su varie scale; in caso contrario, può diluire l'efficacia di un attributo ugualmente significativo su una scala inferiore a causa di altri attributi che hanno valori su una scala maggiore. In altre parole, quando esistono numerose caratteristiche ma i loro valori sono su scale diverse, ciò potrebbe comportare modelli di dati inadeguati durante le attività di data mining. Di conseguenza, vengono normalizzati per mettere tutte le caratteristiche sulla stessa scala.
Quali sono i diversi tipi di normalizzazione?
La normalizzazione è una procedura da seguire per ogni database creato. I moduli normali si riferiscono all'atto di prendere un'architettura di database e applicarvi una serie di criteri e regole formali. Il processo di normalizzazione è classificato come segue: prima forma normale (1 NF), seconda forma normale (2 NF), terza forma normale (3 NF), forma normale Boyce Codd o quarta forma normale ( BCNF o 4 NF), quinta forma normale (5 NF) e sesta forma normale (6 NF) (6 NF).
Che cos'è la normalizzazione min-max?
Uno dei metodi più diffusi per normalizzare i dati è la normalizzazione min-max. Per ogni caratteristica, il valore minimo viene convertito in 0, il valore più alto viene convertito in 1 e tutti gli altri valori vengono convertiti in un decimale compreso tra 0 e 1. Ad esempio, se il valore minimo di una caratteristica era 20 e il il valore più alto era 40, 30 sarebbe stato convertito in circa 0,5 poiché è a metà strada tra 20 e 40. Uno svantaggio significativo della normalizzazione min-max è che non gestisce bene i valori anomali. Ad esempio, se hai 99 valori compresi tra 0 e 40 e uno di essi è 100, tutti i 99 valori verranno convertiti in valori compresi tra 0 e 0,4.