
Czym jest normalizacja w eksploracji danych i jak to zrobić?
Opublikowany: 2020-11-23Firmy coraz częściej polegają na danych, aby dowiedzieć się więcej o swoich klientach. W związku z tym analitycy danych mają większą odpowiedzialność za badanie i analizowanie dużych bloków surowych danych i wydobywanie z nich znaczących trendów i wzorców klientów. Nazywa się to eksploracją danych. Analitycy danych wykorzystują techniki eksploracji danych, zaawansowane analizy statystyczne i technologie wizualizacji danych, aby uzyskać nowe informacje.
Mogą one pomóc firmie w opracowaniu skutecznych strategii marketingowych w celu poprawy wyników biznesowych, zwiększenia sprzedaży i obniżenia kosztów ogólnych. Chociaż istnieją narzędzia i algorytmy do eksploracji danych, nie jest to bułka z masłem, ponieważ dane w świecie rzeczywistym są heterogeniczne. W związku z tym istnieje wiele wyzwań, jeśli chodzi o eksplorację danych. Naucz się nauki o danych, jeśli chcesz zdobyć doświadczenie w eksploracji danych.
Jednym z typowych wyzwań jest to, że zazwyczaj bazy danych zawierają atrybuty różnych jednostek, zakresów i skal. Stosowanie algorytmów do tak drastycznie zmieniających się danych może nie dać dokładnych wyników. Wymaga to normalizacji danych w eksploracji danych .
Jest to niezbędny proces wymagany do normalizacji heterogenicznych danych. Dane można umieścić w mniejszym zakresie, na przykład od 0,0 do 1,0 lub od -1,0 do 1,0. W prostych słowach normalizacja danych ułatwia klasyfikację i zrozumienie danych.
Spis treści
Dlaczego potrzebna jest normalizacja w eksploracji danych?
Normalizacja danych jest potrzebna głównie w celu zminimalizowania lub wykluczenia zduplikowanych danych. Kwestią krytyczną jest duplikat danych. Dzieje się tak, ponieważ przechowywanie danych w relacyjnych bazach danych jest coraz bardziej problematyczne, przechowując identyczne dane w więcej niż jednym miejscu. Normalizacja w eksploracji danych jest procedurą korzystną, ponieważ pozwala osiągnąć pewne korzyści, o których mowa poniżej:
- Dużo łatwiej jest zastosować algorytmy eksploracji danych na zbiorze znormalizowanych danych.
- Wyniki algorytmów eksploracji danych zastosowanych do zbioru znormalizowanych danych są dokładniejsze i skuteczniejsze.
- Gdy dane zostaną znormalizowane, ekstrakcja danych z baz danych staje się znacznie szybsza.
- Do danych znormalizowanych można zastosować bardziej szczegółowe metody analizy danych.
Przeczytaj: Techniki eksploracji danych
3 popularne techniki normalizacji danych w eksploracji danych
Istnieją trzy popularne metody przeprowadzania normalizacji w eksploracji danych . Zawierają:
Minimalna maksymalna normalizacja
Co jest łatwiejsze do zrozumienia – różnica między 200 a 1000000 lub różnica między 0,2 a 1. Rzeczywiście, gdy różnica między wartością minimalną a maksymalną jest mniejsza, dane stają się bardziej czytelne. Normalizacja min-maks działa poprzez konwersję zakresu danych na skalę z zakresu od 0 do 1.
Formuła normalizacji min-maks
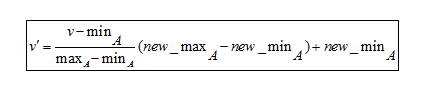
Aby zrozumieć formułę, oto przykład. Załóżmy, że firma chce podjąć decyzję o awansie w oparciu o wieloletnie doświadczenie zawodowe swoich pracowników. Musi więc przeanalizować bazę danych, która wygląda tak:
| imię i nazwisko pracownika | lata doświadczenia |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | 15 |
- Minimalna wartość to 8
- Maksymalna wartość to 20
Ponieważ ta formuła skaluje dane od 0 do 1,
- Nowa min to 0
- Nowa maksymalna wartość to 1
Tutaj V oznacza odpowiednią wartość atrybutu, tj. 8, 10, 15, 20
Po zastosowaniu wzoru normalizacji min-maks wartości V' dla atrybutów są następujące:
- Za 8 lat doświadczenia: v'= 0
- Za 10 lat doświadczenia: v' = 0,16
- Za 15 lat doświadczenia: v' = 0,58
- Za 20 lat doświadczenia: v' = 1
Tak więc normalizacja min-maks może zredukować duże liczby do znacznie mniejszych wartości. Dzięki temu niezwykle łatwo jest odczytać różnicę między liczbami zakresu.
Normalizacja skalowania dziesiętnego
Skalowanie dziesiętne to kolejna technika normalizacji w eksploracji danych . Działa poprzez konwersję liczby na kropkę dziesiętną.
Formuła skalowania dziesiętnego
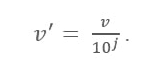
Tutaj:
- V' to nowa wartość po zastosowaniu skalowania dziesiętnego
- V jest odpowiednią wartością atrybutu
Teraz liczba całkowita J określa ruch punktów dziesiętnych. Jak więc to zdefiniować? Jest równa liczbie cyfr obecnych w maksymalnej wartości w tabeli danych. Oto przykład:

Załóżmy, że firma chce porównać pensje nowych stolarzy. Oto wartości danych:
| imię i nazwisko pracownika | Pensja |
| ABC | 10 000 |
| XYZ | 25 000 |
| PQR | 8000 |
| MNO | 15 000 |
Teraz poszukaj maksymalnej wartości w danych. W tym przypadku jest to 25 tys. Teraz policz liczbę cyfr w tej wartości. W tym przypadku jest to „5”. Więc tutaj 'j' jest równe 5, czyli 100 000. Oznacza to, że V (wartość atrybutu) należy tutaj podzielić przez 100 000.
Po zastosowaniu formuły skalowania zera dziesiętnego, oto nowe wartości:
| Imię | Pensja | Wynagrodzenie po przeskalowaniu dziesiętnym |
| ABC | 10 000 | 0,1 |
| XYZ | 25 000 | 0,25 |
| PQR | 8 000 | 0,08 |
| MNO | 15 000 | 0,15 |
W ten sposób skalowanie dziesiętne może zmniejszyć duże liczby do łatwych do zrozumienia mniejszych wartości dziesiętnych. Ponadto dane przypisane do różnych jednostek stają się łatwe do odczytania i zrozumienia po przeliczeniu na mniejsze wartości dziesiętne.
Koniecznie przeczytaj: Pomysły i tematy dotyczące projektów eksploracji danych
Normalizacja Z-Score
Wartość Z-Score ma na celu zrozumienie, jak daleko punkt danych jest od średniej. Z technicznego punktu widzenia mierzy odchylenia standardowe poniżej lub powyżej średniej. Waha się od -3 odchylenia standardowego do +3 odchylenia standardowego. Normalizacja Z-score w eksploracji danych jest przydatna w przypadku tych rodzajów analizy danych, w których istnieje potrzeba porównania wartości w odniesieniu do wartości średniej (średniej), takiej jak wyniki testów lub ankiet.
Na przykład waga osoby wynosi 150 funtów. Teraz, jeśli zachodzi potrzeba porównania tej wartości ze średnią wagą populacji wymienionej w obszernej tabeli danych, do badania takich wartości potrzebna jest normalizacja Z-score, zwłaszcza jeśli czyjaś waga jest zapisana w kilogramach.
Wniosek
Ponieważ dane pochodzą z różnych źródeł, bardzo często występują różne atrybuty w dowolnej partii danych. Tak więc normalizacja w eksploracji danych jest jak wstępne przetwarzanie i przygotowywanie danych do analizy.
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science , który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Co oznacza normalizacja w eksploracji danych?
Normalizacja to proces skalowania danych atrybutu tak, aby mieściły się w węższym zakresie, np. -1,0 do 1,0 lub 0,0 do 1,0. Jest to ogólnie korzystne dla algorytmów klasyfikacji. Normalizacja jest zazwyczaj konieczna, gdy mamy do czynienia z charakterystykami w różnych skalach; w przeciwnym razie może osłabić skuteczność równie istotnego atrybutu na niższej skali ze względu na inne atrybuty mające wartości na większej skali. Innymi słowy, gdy istnieje wiele cech, ale ich wartości są w różnych skalach, może to skutkować nieodpowiednimi modelami danych podczas wykonywania czynności eksploracji danych. W rezultacie są one znormalizowane, aby umieścić wszystkie cechy na tej samej skali.
Jakie są rodzaje normalizacji?
Normalizacja to procedura, której należy przestrzegać dla każdej tworzonej bazy danych. Normal Forms odnosi się do aktu przyjęcia architektury bazy danych i zastosowania do niej zestawu formalnych kryteriów i reguł. Proces normalizacji jest klasyfikowany w następujący sposób: pierwsza postać normalna (1 NF), druga postać normalna (2 NF), trzecia postać normalna (3 NF), postać normalna Boyce'a Codda lub czwarta postać normalna (BCNF lub 4 NF), piąta postać normalna (5 NF) i szósta forma normalna (6 NF) (6 NF).
Co to jest normalizacja min-maks?
Jedną z najbardziej rozpowszechnionych metod normalizacji danych jest normalizacja min-maks. Dla każdej cechy minimalna wartość jest konwertowana na 0, najwyższa wartość jest konwertowana na 1, a wszystkie inne wartości są konwertowane na ułamek dziesiętny z zakresu od 0 do 1. Na przykład, jeśli minimalna wartość cechy wynosiła 20, a wartość najwyższa wartość wynosiła 40, 30 zostanie przekonwertowane na około 0,5, ponieważ jest w połowie między 20 a 40. Jedną istotną wadą normalizacji min-maks jest to, że nie radzi sobie dobrze z wartościami odstającymi. Na przykład, jeśli masz 99 wartości z zakresu od 0 do 40, a jedna z nich to 100, wszystkie 99 wartości zostaną przekonwertowane na wartości z zakresu od 0 do 0,4.