
Normalization ใน Data Mining คืออะไรและต้องทำอย่างไร
เผยแพร่แล้ว: 2020-11-23บริษัทต่างๆ พึ่งพาข้อมูลมากขึ้นเรื่อยๆ เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับลูกค้าของตน ดังนั้น นักวิเคราะห์ข้อมูลจึงมีความรับผิดชอบมากขึ้นในการสำรวจและวิเคราะห์กลุ่มข้อมูลดิบจำนวนมาก และรวบรวมแนวโน้มและรูปแบบของลูกค้าที่มีความหมายจากข้อมูลนั้น สิ่งนี้เรียกว่าการทำเหมืองข้อมูล นักวิเคราะห์ข้อมูลใช้เทคนิคการทำเหมืองข้อมูล การวิเคราะห์ทางสถิติขั้นสูง และเทคโนโลยีการแสดงข้อมูลเพื่อให้ได้ข้อมูลเชิงลึกใหม่ๆ
สิ่งเหล่านี้สามารถช่วยให้ธุรกิจพัฒนากลยุทธ์ทางการตลาดที่มีประสิทธิภาพ เพื่อปรับปรุงผลการดำเนินธุรกิจ เพิ่มยอดขาย และลดต้นทุนค่าโสหุ้ย แม้ว่าจะมีเครื่องมือและอัลกอริธึมสำหรับการทำเหมืองข้อมูล แต่ก็ไม่ใช่เส้นทางลัด เนื่องจากข้อมูลในโลกแห่งความเป็นจริงมีความแตกต่างกัน ดังนั้นจึงมีความท้าทายค่อนข้างน้อยเมื่อพูดถึงการทำเหมืองข้อมูล เรียนรู้วิทยาศาสตร์ข้อมูลหากคุณต้องการได้รับความเชี่ยวชาญในการทำเหมืองข้อมูล
ความท้าทายทั่วไปประการหนึ่งคือ โดยปกติ ฐานข้อมูลประกอบด้วยคุณลักษณะของหน่วย ช่วง และมาตราส่วนที่แตกต่างกัน การใช้อัลกอริธึมกับข้อมูลที่มีความหลากหลายอย่างมากดังกล่าวอาจไม่ได้ผลลัพธ์ที่แม่นยำ สิ่งนี้เรียกร้องให้มีการปรับข้อมูล ให้เป็นมาตรฐานในการทำเหมือง ข้อมูล
เป็นกระบวนการที่จำเป็นในการทำให้ข้อมูลที่ต่างกันเป็นมาตรฐาน สามารถใส่ข้อมูลในช่วงที่เล็กกว่าได้ เช่น 0.0 ถึง 1.0 หรือ -1.0 ถึง 1.0 พูดง่ายๆ ก็คือ การทำให้เป็นมาตรฐานของข้อมูลทำให้ข้อมูลสามารถจำแนกและทำความเข้าใจได้ง่ายขึ้น
สารบัญ
เหตุใดจึงต้องมีการ Normalization ใน Data Mining
การปรับข้อมูลให้เป็นมาตรฐานเป็นหลักเพื่อลดหรือแยกข้อมูลที่ซ้ำกัน ความซ้ำซ้อนในข้อมูลเป็นปัญหาสำคัญ เนื่องจากเป็นปัญหามากขึ้นในการจัดเก็บข้อมูลในฐานข้อมูลเชิงสัมพันธ์ โดยเก็บข้อมูลที่เหมือนกันไว้มากกว่าหนึ่งแห่ง การทำให้เป็น มาตรฐานในการขุดข้อมูล เป็นขั้นตอนที่เป็นประโยชน์ เนื่องจากช่วยให้บรรลุข้อได้เปรียบบางประการดังที่กล่าวไว้ด้านล่าง:
- ง่ายกว่ามากที่จะใช้อัลกอริธึมการขุดข้อมูลกับชุดข้อมูลที่ทำให้เป็นมาตรฐาน
- ผลลัพธ์ของอัลกอริธึมการขุดข้อมูลที่ใช้กับชุดของข้อมูลที่ทำให้เป็นมาตรฐานนั้นแม่นยำและมีประสิทธิภาพมากขึ้น
- เมื่อข้อมูลถูกทำให้เป็นมาตรฐาน การดึงข้อมูลจากฐานข้อมูลจะเร็วขึ้นมาก
- สามารถใช้วิธีการวิเคราะห์ข้อมูลที่เฉพาะเจาะจงมากขึ้นกับข้อมูลที่ทำให้เป็นมาตรฐานได้
อ่าน: เทคนิคการทำเหมืองข้อมูล
3 เทคนิคยอดนิยมสำหรับ Data Normalization ใน Data Mining
มีสามวิธีที่ได้รับความนิยม ในการทำเหมืองข้อมูล ให้เป็น มาตรฐาน พวกเขารวมถึง:
การทำให้เป็นมาตรฐานขั้นต่ำสูงสุด
สิ่งที่เข้าใจได้ง่ายกว่า – ความแตกต่างระหว่าง 200 และ 1000000 หรือความแตกต่างระหว่าง 0.2 และ 1 แท้จริงแล้ว เมื่อความแตกต่างระหว่างค่าต่ำสุดและสูงสุดมีค่าน้อยกว่า ข้อมูลจะอ่านง่ายขึ้น ฟังก์ชันการทำให้เป็นมาตรฐานต่ำสุด-สูงสุดโดยการแปลงช่วงของข้อมูลเป็นมาตราส่วนที่มีช่วงตั้งแต่ 0 ถึง 1
สูตร Normalization ต่ำสุด-สูงสุด
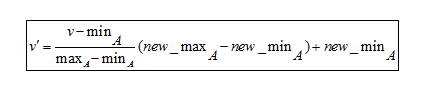
เพื่อทำความเข้าใจสูตร นี่คือตัวอย่าง สมมติว่าบริษัทต้องการตัดสินใจเลื่อนตำแหน่งโดยพิจารณาจากประสบการณ์การทำงานของพนักงาน จึงต้องวิเคราะห์ฐานข้อมูลที่มีลักษณะดังนี้:
| ชื่อพนักงาน | ปีแห่งประสบการณ์ |
| ABC | 8 |
| XYZ | 20 |
| PQR | 10 |
| MNO | 15 |
- ค่าต่ำสุดคือ8
- ค่าสูงสุดคือ 20
เนื่องจากสูตรนี้ปรับขนาดข้อมูลระหว่าง 0 ถึง 1
- ค่าต่ำสุดใหม่คือ 0
- ค่าสูงสุดใหม่คือ 1
ในที่นี้ V หมายถึงค่าของแอตทริบิวต์ที่เกี่ยวข้อง เช่น 8, 10, 15, 20
หลังจากใช้สูตรการทำให้เป็นมาตรฐานต่ำสุด-สูงสุด ต่อไปนี้คือค่า V' สำหรับแอตทริบิวต์:
- สำหรับประสบการณ์ 8 ปี: v'= 0
- สำหรับประสบการณ์ 10 ปี: v' = 0.16
- สำหรับประสบการณ์ 15 ปี: v' = 0.58
- สำหรับประสบการณ์ 20 ปี: v' = 1
ดังนั้น การทำให้เป็นมาตรฐานต่ำสุด-สูงสุดสามารถลดจำนวนจำนวนมากเป็นค่าที่น้อยกว่าได้มาก ทำให้ง่ายต่อการอ่านความแตกต่างระหว่างตัวเลขต่างๆ
การปรับมาตราส่วนทศนิยมให้เป็นมาตรฐาน
การปรับมาตราส่วนทศนิยมเป็นอีกเทคนิคหนึ่งสำหรับการ ทำให้เป็นมาตรฐานในการทำเหมือง ข้อมูล มันทำงานโดยการแปลงตัวเลขเป็นจุดทศนิยม
สูตรมาตราส่วนทศนิยม
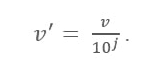
ที่นี่:
- V' คือค่าใหม่หลังจากใช้มาตราส่วนทศนิยม
- V คือค่าที่เกี่ยวข้องของแอตทริบิวต์
ตอนนี้ จำนวนเต็ม J กำหนดการเคลื่อนที่ของจุดทศนิยม แล้วจะกำหนดได้อย่างไร? เท่ากับจำนวนหลักที่แสดงในค่าสูงสุดในตารางข้อมูล นี่คือตัวอย่าง:

สมมติว่าบริษัทต้องการเปรียบเทียบเงินเดือนของช่างไม้ใหม่ นี่คือค่าข้อมูล:
| ชื่อพนักงาน | เงินเดือน |
| ABC | 10,000 |
| XYZ | 25,000 |
| PQR | 8,000 |
| MNO | 15,000 |
ตอนนี้ ให้มองหาค่าสูงสุดในข้อมูล ในกรณีนี้คือ 25,000 ตอนนี้นับจำนวนหลักในค่านี้ ในกรณีนี้ มันคือ '5' ตรงนี้ 'j' เท่ากับ 5 คือ 100,000 ซึ่งหมายความว่าต้องหาร V (ค่าของแอตทริบิวต์) ด้วย 100,000 ที่นี่
หลังจากใช้สูตรการปรับมาตราส่วนทศนิยมศูนย์แล้ว ค่าใหม่มีดังนี้
| ชื่อ | เงินเดือน | เงินเดือนหลังการปรับทศนิยม |
| ABC | 10,000 | 0.1 |
| XYZ | 25, 000 | 0.25 |
| PQR | 8,000 | 0.08 |
| MNO | 15,000 | 0.15 |
ดังนั้น การปรับมาตราส่วนทศนิยมสามารถลดจำนวนตัวเลขจำนวนมากให้เป็นค่าทศนิยมขนาดเล็กที่เข้าใจง่าย นอกจากนี้ ข้อมูลที่มาจากหน่วยต่างๆ จะอ่านและทำความเข้าใจได้ง่ายเมื่อถูกแปลงเป็นค่าทศนิยมที่เล็กกว่า
ต้องอ่าน: แนวคิดและหัวข้อโครงการขุดข้อมูล
การทำให้เป็นมาตรฐาน Z-Score
ค่า Z-Score คือการเข้าใจว่าจุดข้อมูลอยู่ห่างจากค่าเฉลี่ยมากแค่ไหน ในทางเทคนิค มันจะวัดค่าเบี่ยงเบนมาตรฐานที่ต่ำกว่าหรือสูงกว่าค่าเฉลี่ย มีตั้งแต่ -3 ส่วนเบี่ยงเบนมาตรฐานถึง +3 ส่วนเบี่ยงเบนมาตรฐาน การทำให้เป็นมาตรฐานของ คะแนน Z ในการทำเหมืองข้อมูล มีประโยชน์สำหรับการวิเคราะห์ข้อมูลประเภทดังกล่าว ซึ่งมีความจำเป็นต้องเปรียบเทียบค่าที่สัมพันธ์กับค่าเฉลี่ย (ค่าเฉลี่ย) เช่น ผลลัพธ์จากการทดสอบหรือการสำรวจ
ตัวอย่างเช่น น้ำหนักของบุคคลคือ 150 ปอนด์ ในตอนนี้ หากจำเป็นต้องเปรียบเทียบค่านั้นกับน้ำหนักเฉลี่ยของประชากรที่ระบุไว้ในตารางข้อมูลขนาดใหญ่ จำเป็นต้องมีการปรับค่า Z-score ให้เป็นมาตรฐานเพื่อศึกษาค่าดังกล่าว โดยเฉพาะอย่างยิ่งถ้าน้ำหนักของใครบางคนถูกบันทึกเป็นกิโลกรัม
บทสรุป
เนื่องจากข้อมูลมาจากแหล่งต่างๆ จึงเป็นเรื่องธรรมดามากที่จะมีแอตทริบิวต์ที่แตกต่างกันในชุดข้อมูลใดๆ ดังนั้นการ ทำให้เป็นมาตรฐานในการขุดข้อมูล จึงเหมือนกับการประมวลผลล่วงหน้าและการเตรียมข้อมูลสำหรับการวิเคราะห์
หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ลองดู โปรแกรม Executive PG ของ IIIT-B & upGrad ใน Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1 -on-1 พร้อมที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
Normalization ใน Data mining หมายถึงอะไร
การทำให้เป็นมาตรฐานคือกระบวนการปรับขนาดข้อมูลของแอตทริบิวต์ให้อยู่ในช่วงที่แคบลง เช่น -1.0 ถึง 1.0 หรือ 0.0 ถึง 1.0 เป็นประโยชน์สำหรับอัลกอริธึมการจำแนกประเภทโดยทั่วไป การทำให้เป็นมาตรฐานโดยทั่วไปมีความจำเป็นเมื่อต้องรับมือกับคุณลักษณะต่างๆ ในระดับต่างๆ มิฉะนั้น อาจเจือจางประสิทธิภาพของแอตทริบิวต์ที่มีนัยสำคัญเท่าเทียมกันในระดับที่ต่ำกว่าเนื่องจากคุณลักษณะอื่นๆ ที่มีค่าในระดับที่มากกว่า กล่าวอีกนัยหนึ่ง เมื่อลักษณะต่างๆ มีอยู่มากมายแต่ค่าของมันอยู่ในระดับต่างๆ อาจส่งผลให้ตัวแบบข้อมูลไม่เพียงพอเมื่อทำกิจกรรมการขุดข้อมูล เป็นผลให้พวกเขาถูกทำให้เป็นมาตรฐานเพื่อให้คุณลักษณะทั้งหมดอยู่ในระดับเดียวกัน
Normalization ประเภทต่าง ๆ มีอะไรบ้าง?
การทำให้เป็นมาตรฐานคือขั้นตอนที่ควรปฏิบัติตามสำหรับแต่ละฐานข้อมูลที่คุณสร้าง แบบฟอร์มปกติหมายถึงการกระทำของสถาปัตยกรรมฐานข้อมูลและการนำชุดเกณฑ์และกฎเกณฑ์ที่เป็นทางการไปใช้กับสถาปัตยกรรมนั้น กระบวนการนอร์มัลไลซ์เซชันแบ่งได้ดังนี้ First Normal Form (1 NF), Second Normal Form (2 NF), Third Normal Form (3 NF), Boyce Codd Normal Form หรือ Fourth Normal Form ( BCNF หรือ 4 NF), Fifth Normal Form (5 NF) และรูปแบบปกติที่หก (6 NF) (6 NF)
Min-Max Normalization คืออะไร?
วิธีการหนึ่งที่แพร่หลายที่สุดสำหรับการทำให้ข้อมูลเป็นมาตรฐานคือการทำให้เป็นมาตรฐานต่ำสุด-สูงสุด สำหรับแต่ละจุดสนใจ ค่าต่ำสุดจะถูกแปลงเป็น 0 ค่าสูงสุดจะถูกแปลงเป็น 1 และค่าอื่นๆ ทั้งหมดจะถูกแปลงเป็นทศนิยมระหว่าง 0 ถึง 1 ตัวอย่างเช่น หากค่าต่ำสุดของจุดสนใจคือ 20 และ ค่าสูงสุดคือ 40 โดย 30 จะถูกแปลงเป็นประมาณ 0.5 เนื่องจากอยู่กึ่งกลางระหว่าง 20 ถึง 40 ข้อเสียเปรียบที่สำคัญประการหนึ่งของการทำให้เป็นมาตรฐานต่ำสุด-สูงสุดคือไม่สามารถจัดการกับค่าผิดปกติได้ดี ตัวอย่างเช่น หากคุณมี 99 ค่าตั้งแต่ 0 ถึง 40 และหนึ่งในนั้นคือ 100 ค่าทั้งหมด 99 ค่าจะถูกแปลงเป็นค่าตั้งแต่ 0 ถึง 0.4