
从零到英雄:烧瓶生产食谱
已发表: 2022-03-11作为一名机器学习工程师和计算机视觉专家,我发现自己使用 Flask 创建 API 甚至 Web 应用程序的频率惊人地频繁。 在这篇文章中,我想分享一些技巧和有用的方法来构建一个完整的生产就绪 Flask 应用程序。
我们将涵盖以下主题:
- 配置管理。 任何现实生活中的应用程序都有一个具有特定阶段的生命周期——至少,它会是开发、测试和部署。 在每个阶段,应用程序代码应该在稍微不同的环境中工作,这需要一组不同的设置,例如数据库连接字符串、外部 API 密钥和 URL。
- 使用 Gunicorn 的自托管 Flask 应用程序。 虽然 Flask 有一个内置的 Web 服务器,但众所周知,它不适合生产,需要放在一个能够通过 WSGI 协议与 Flask 通信的真实 Web 服务器后面。 一个常见的选择是 Gunicorn——一个 Python WSGI HTTP 服务器。
- 使用 Nginx 提供静态文件和代理请求。 作为 HTTP Web 服务器,Gunicorn 反过来又是一个不适合面向 Web 的应用程序服务器。 这就是为什么我们需要 Nginx 作为反向代理并提供静态文件的原因。 如果我们需要将应用程序扩展到多台服务器,Nginx 也会负责负载平衡。
- 在专用 Linux 服务器上的 Docker 容器内部署应用程序。 长期以来,容器化部署一直是软件设计的重要组成部分。 我们的应用程序也不例外,将整齐地打包在自己的容器中(实际上是多个容器)。
- 为应用程序配置和部署 PostgreSQL 数据库。 数据库结构和迁移将由 Alembic 管理,SQLAlchemy 提供对象关系映射。
- 设置一个 Celery 任务队列来处理长时间运行的任务。 每个应用程序最终都需要它来从外部工作人员的 Web 服务器线程中卸载时间或计算密集型流程——无论是邮件发送、自动数据库内务管理还是上传图像的处理。
创建 Flask 应用程序
让我们从创建应用程序代码和资产开始。 请注意,我不会在这篇文章中讨论正确的 Flask 应用程序结构。 为简洁起见,演示应用程序包含最少数量的模块和包。
首先,创建一个目录结构并初始化一个空的 Git 存储库。
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txt接下来,我们将添加代码。
配置/__init__.py
在 config 模块中,我们将定义我们的微型配置管理框架。 这个想法是使应用程序根据APP_ENV环境变量选择的配置预设运行,此外,如果需要,添加一个选项以使用特定环境变量覆盖任何配置设置。
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return res配置/设置.py
这是一组配置类,其中一个由APP_ENV变量选择。 当应用程序运行时, __init__.py中的代码将实例化这些类之一,并使用特定环境变量(如果存在)覆盖字段值。 稍后初始化 Flask 和 Celery 配置时,我们将使用最终配置对象。
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = True任务/__init__.py
tasks 包包含 Celery 初始化代码。 Config 包,在初始化时已经在模块级别复制了所有设置,用于更新 Celery 配置对象,以防我们将来有一些 Celery 特定的设置——例如,计划任务和工作超时。
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()任务/celery_worker.py
这个模块是启动和初始化一个 Celery worker 所必需的,它将在一个单独的 Docker 容器中运行。 它初始化 Flask 应用程序上下文以访问与应用程序相同的环境。 如果不需要,可以安全地删除这些行。
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
接下来是 API 包,它使用 Flask-Restful 包定义了 REST API。 我们的应用程序只是一个演示,只有两个端点:
-
/process_data– 在 Celery worker 上启动一个 dummy long 操作并返回一个新任务的 ID。 -
/tasks/<task_id>– 按任务 ID 返回任务的状态。
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')模型/__init__.py
现在我们将为User对象添加一个 SQLAlchemy 模型,以及一个数据库引擎初始化代码。 我们的演示应用程序不会以任何有意义的方式使用User对象,但我们需要它来确保数据库迁移工作和 SQLAlchemy-Flask 集成设置正确。
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)请注意 UUID 是如何在默认表达式中自动生成为对象 ID 的。
应用程序.py
最后,让我们创建一个主 Flask 应用程序文件。
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>我们到了:
- 使用时间、级别和进程 ID 以适当的格式配置基本日志记录
- 使用 API 初始化和“Hello, world!”定义 Flask 应用程序创建函数页
- 定义在开发期间运行应用程序的入口点
wsgi.py
此外,我们需要一个单独的模块来使用 Gunicorn 运行 Flask 应用程序。 它将只有两行:
from app import create_app app = create_app()应用程序代码已准备就绪。 我们的下一步是创建一个 Docker 配置。
构建 Docker 容器
我们的应用程序将需要多个 Docker 容器来运行:
- 应用程序容器,用于提供模板页面并公开 API 端点。 在生产中拆分这两个功能是个好主意,但我们的演示应用程序中没有任何模板页面。 该容器将运行 Gunicorn Web 服务器,该服务器将通过 WSGI 协议与 Flask 通信。
- 芹菜工人容器执行长任务。 这是同一个应用程序容器,但使用自定义运行命令来启动 Celery,而不是 Gunicorn。
- Celery beat 容器——与上面类似,但用于定期调用的任务,例如删除从未确认其电子邮件的用户的帐户。
- RabbitMQ 容器。 Celery 需要消息代理来在工作人员和应用程序之间进行通信,并存储任务结果。 RabbitMQ 是常见的选择,但您也可以使用 Redis 或 Kafka。
- 带有 PostgreSQL 的数据库容器。
轻松管理多个容器的一种自然方法是使用 Docker Compose。 但首先,我们需要创建一个 Dockerfile 来为我们的应用程序构建一个容器镜像。 让我们把它放到项目目录中。
FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level info该文件指示 Docker:

- 使用 Pipenv 安装所有依赖项
- 将应用程序文件夹添加到容器
- 将 TCP 端口 5000 暴露给主机
- 将容器的默认启动命令设置为 Gunicorn 调用
让我们更多地讨论最后一行发生的事情。 它运行 Gunicorn,将工人类指定为 gevent。 Gevent 是一个用于协作多任务的轻量级并发库。 它在 I/O 绑定负载上提供了相当大的性能提升,与操作系统的线程抢占式多任务处理相比,提供了更好的 CPU 利用率。 --workers参数是工作进程的数量。 将其设置为等于服务器上的内核数是个好主意。
一旦我们有了应用程序容器的 Dockerfile,我们就可以创建一个docker-compose.yml文件,该文件将定义应用程序运行所需的所有容器。
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration我们定义了以下服务:
-
broker-rabbitmq– RabbitMQ 消息代理容器。 连接凭据由环境变量定义 db-postgres– PostgreSQL 容器及其凭据migration– 一个应用容器,它将使用 Flask-Migrate 执行数据库迁移并退出。 API 容器依赖于它,并将在之后运行。-
api- 主应用程序容器 api-worker和api-beat– 为从 API 接收的任务和计划任务运行 Celery 工作者的容器
每个应用程序容器还将从 docker docker-compose up命令接收APP_ENV变量。
一旦我们准备好所有应用程序资产,让我们将它们放在 GitHub 上,这将帮助我们在服务器上部署代码。
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin master配置服务器
我们的代码现在在 GitHub 上,剩下的就是执行初始服务器配置和部署应用程序。 在我的例子中,服务器是一个运行 AMI Linux 的 AWS 实例。 对于其他 Linux 风格,说明可能略有不同。 我还假设服务器已经有一个外部 IP 地址,DNS 配置了指向这个 IP 的 A 记录,并且为域颁发了 SSL 证书。
安全提示:不要忘记在您的主机控制台(或使用iptables )中允许端口 80 和 443 用于 HTTP(S) 流量,端口 22 用于 SSH,并关闭对所有其他端口的外部访问! 一定要对IPv6协议做同样的事情!
安装依赖
首先,我们需要在服务器上运行 Nginx 和 Docker,再加上 Git 来拉取代码。 让我们通过 SSH 登录并使用包管理器来安装它们。
sudo yum install -y docker docker-compose nginx git配置 Nginx
下一步是配置 Nginx。 主要的nginx.conf配置文件通常保持原样。 不过,请务必检查它是否适合您的需求。 对于我们的应用程序,我们将在conf.d文件夹中创建一个新的配置文件。 顶级配置有一个指令来包含其中的所有.conf文件。
cd /etc/nginx/conf.d sudo vim flask-deploy.conf这是 Nginx 的 Flask 站点配置文件,包括电池。 它具有以下特点:
- SSL 已配置。 您应该拥有适用于您的域的有效证书,例如免费的 Let's Encrypt 证书。
-
www.your-site.com请求被重定向到your-site.com - HTTP 请求被重定向到安全的 HTTPS 端口。
- 反向代理配置为将请求传递到本地端口 5000。
- 静态文件由 Nginx 从本地文件夹提供。
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } 编辑完文件后,运行sudo nginx -s reload看看有没有错误。
设置 GitHub 凭证
使用单独的“部署”VCS 帐户来部署项目和 CI/CD 系统是一个很好的做法。 这样您就不会因为暴露自己帐户的凭据而冒险。 为了进一步保护项目存储库,您还可以将此类帐户的权限限制为只读访问。 对于 GitHub 存储库,您需要一个组织帐户来执行此操作。 要部署我们的演示应用程序,我们只需在服务器上创建一个公钥并将其注册到 GitHub 上即可访问我们的项目,而无需每次都输入凭据。
要创建新的 SSH 密钥,请运行:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" 然后登录 GitHub 并在帐户设置中从~/.ssh/id_rsa.pub添加您的公钥。
部署应用
最后的步骤非常简单——我们需要从 GitHub 获取应用程序代码并使用 Docker Compose 启动所有容器。
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d 在第一次运行时省略-d (以分离模式启动容器)以查看终端中每个容器的输出并检查可能的问题可能是一个好主意。 另一种选择是随后使用docker logs检查每个单独的容器。 让我们看看我们所有的容器是否都使用docker ps.
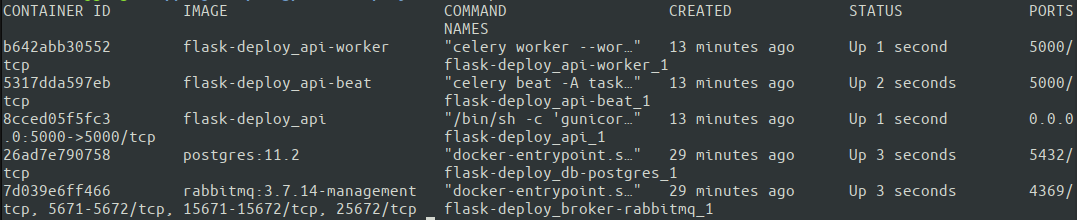
伟大的。 所有五个容器都已启动并运行。 Docker Compose 根据 docker-compose.yml 中指定的服务自动分配容器名称。 现在是时候最终测试整个配置是如何工作的了! 最好从外部机器运行测试,以确保服务器具有正确的网络设置。
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txt而已。 我们在 AWS 实例上运行的应用程序具有简约但完全可用于生产的配置。 希望它能帮助您快速开始构建现实生活中的应用程序并避免一些常见错误! 完整的代码可在 GitHub 存储库中获得。
结论
在本文中,我们讨论了构建、配置、打包和部署 Flask 应用程序到生产环境的一些最佳实践。 这是一个非常大的话题,不可能在一篇博文中完全涵盖。 以下是我们未解决的重要问题列表:
本文不包括:
- 持续集成和持续部署
- 自动测试
- 日志运输
- API监控
- 将应用程序扩展到多台服务器
- 保护源代码中的凭据
但是,您可以使用此博客上的其他一些重要资源来学习如何做到这一点。 例如,要探索日志记录,请参阅 Python 日志记录:深度教程,或有关 CI/CD 和自动化测试的一般概述,请参阅如何构建有效的初始部署管道。 我把这些的实现留给读者作为练习。
谢谢阅读!