
Od zera do bohatera: przepisy na produkcję kolb
Opublikowany: 2022-03-11Jako inżynier ds. uczenia maszynowego i ekspert w dziedzinie wizji komputerowej, zaskakująco często tworzę interfejsy API, a nawet aplikacje internetowe za pomocą Flask. W tym poście chcę podzielić się kilkoma wskazówkami i przydatnymi przepisami na zbudowanie kompletnej, gotowej do produkcji aplikacji Flask.
Omówimy następujące tematy:
- Zarządzanie konfiguracją. Każda rzeczywista aplikacja ma cykl życia z określonymi etapami — przynajmniej będzie to tworzenie, testowanie i wdrażanie. Na każdym etapie kod aplikacji powinien działać w nieco innym środowisku, co wymaga posiadania innego zestawu ustawień, takich jak parametry połączenia z bazą danych, klucze zewnętrznych interfejsów API i adresy URL.
- Self-hosting aplikacji Flask z Gunicorn. Chociaż Flask ma wbudowany serwer sieciowy, jak wszyscy wiemy, nie nadaje się on do produkcji i musi być umieszczony za prawdziwym serwerem sieciowym, który może komunikować się z Flask za pomocą protokołu WSGI. Częstym wyborem jest Gunicorn — serwer HTTP WSGI w Pythonie.
- Obsługa plików statycznych i żądania proxy za pomocą Nginx. Będąc serwerem WWW HTTP, Gunicorn z kolei jest serwerem aplikacji, który nie jest przystosowany do działania w sieci. Dlatego potrzebujemy Nginx jako odwrotnego proxy i do obsługi plików statycznych. W przypadku, gdy będziemy musieli skalować naszą aplikację do wielu serwerów, Nginx zajmie się również równoważeniem obciążenia.
- Wdrażanie aplikacji w kontenerach Dockera na dedykowanym serwerze Linux. Wdrożenie kontenerowe jest od dłuższego czasu istotną częścią projektowania oprogramowania. Nasza aplikacja nie jest inna i będzie starannie zapakowana we własnym pojemniku (w rzeczywistości w wielu pojemnikach).
- Konfiguracja i wdrożenie bazy danych PostgreSQL dla aplikacji. Struktura bazy danych i migracje będą zarządzane przez Alembic z SQLAlchemy zapewniającym mapowanie obiektowo-relacyjne.
- Konfigurowanie kolejki zadań Celery do obsługi długotrwałych zadań. Każda aplikacja będzie ostatecznie tego wymagać, aby odciążyć czasochłonne lub intensywne procesy obliczeniowe — czy to wysyłanie poczty, automatyczne porządkowanie bazy danych, czy przetwarzanie przesłanych obrazów — z wątków serwera WWW na zewnętrznych pracownikach.
Tworzenie aplikacji Flask
Zacznijmy od stworzenia kodu aplikacji i zasobów. Zwróć uwagę, że w tym poście nie zajmę się poprawną strukturą aplikacji Flask. Aplikacja demonstracyjna składa się z minimalnej liczby modułów i pakietów ze względu na zwięzłość i przejrzystość.
Najpierw utwórz strukturę katalogów i zainicjuj puste repozytorium Git.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtNastępnie dodamy kod.
config/__init__.py
W module konfiguracyjnym zdefiniujemy naszą małą strukturę zarządzania konfiguracją. Chodzi o to, aby aplikacja zachowywała się zgodnie z ustawieniami konfiguracyjnymi wybranymi przez zmienną środowiskową APP_ENV , a także dodaj opcję zastąpienia dowolnego ustawienia konfiguracji określoną zmienną środowiskową, jeśli jest to wymagane.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/settings.py
Jest to zestaw klas konfiguracyjnych, z których jedna jest wybierana przez zmienną APP_ENV . Po uruchomieniu aplikacji kod w __init__.py utworzy wystąpienie jednej z tych klas, nadpisując wartości pól określonymi zmiennymi środowiskowymi, jeśli są one obecne. Użyjemy ostatecznego obiektu konfiguracyjnego podczas późniejszej inicjalizacji konfiguracji Flask i Celery.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Truezadania/__init__.py
Pakiet zadań zawiera kod inicjujący Celery. Pakiet konfiguracyjny, który będzie już zawierał wszystkie ustawienia skopiowane na poziomie modułu podczas inicjalizacji, służy do aktualizacji obiektu konfiguracyjnego Celery na wypadek, gdybyśmy mieli w przyszłości pewne ustawienia specyficzne dla Celery – na przykład zaplanowane zadania i limity czasu pracy.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()zadania/celery_pracownik.py
Ten moduł jest wymagany do uruchomienia i zainicjowania pracownika Celery, który będzie działał w osobnym kontenerze Docker. Inicjuje kontekst aplikacji Flask, aby mieć dostęp do tego samego środowiska, co aplikacja. Jeśli nie jest to wymagane, linie te można bezpiecznie usunąć.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Dalej idzie pakiet API, który definiuje API REST przy użyciu pakietu Flask-Restful. Nasza aplikacja jest tylko wersją demonstracyjną i będzie miała tylko dwa punkty końcowe:
-
/process_data– Rozpoczyna fikcyjną długą operację na pracowniku Celery i zwraca identyfikator nowego zadania. -
/tasks/<task_id>— zwraca stan zadania według identyfikatora zadania.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')modele/__init__.py
Teraz dodamy model SQLAlchemy dla obiektu User oraz kod inicjalizacji silnika bazy danych. Obiekt User nie będzie używany przez naszą aplikację demonstracyjną w żaden znaczący sposób, ale będziemy go potrzebować, aby upewnić się, że migracje baz danych działają, a integracja SQLAlchemy-Flask jest prawidłowo skonfigurowana.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Zwróć uwagę, jak UUID jest generowany automatycznie jako identyfikator obiektu przez wyrażenie domyślne.
aplikacja.py
Na koniec utwórzmy główny plik aplikacji Flask.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Oto jesteśmy:
- Konfiguracja podstawowego logowania w odpowiednim formacie z czasem, poziomem i identyfikatorem procesu
- Definiowanie funkcji tworzenia aplikacji Flask z inicjalizacją API i „Hello, world!” strona
- Definiowanie punktu wejścia do uruchamiania aplikacji w czasie tworzenia
wsgi.py
Ponadto będziemy potrzebować osobnego modułu do uruchomienia aplikacji Flask z Gunicornem. Będzie miał tylko dwie linie:
from app import create_app app = create_app()Kod aplikacji jest gotowy. Naszym kolejnym krokiem jest stworzenie konfiguracji Dockera.
Budowanie kontenerów Docker
Nasza aplikacja będzie wymagała do uruchomienia wielu kontenerów Docker:
- Kontener aplikacji do obsługi stron szablonowych i eksponowania punktów końcowych interfejsu API. Dobrym pomysłem jest rozdzielenie tych dwóch funkcji w produkcji, ale w naszej aplikacji demonstracyjnej nie mamy żadnych szablonów stron. W kontenerze będzie działał serwer sieciowy Gunicorn, który będzie komunikował się z Flask za pomocą protokołu WSGI.
- Pojemnik na seler do wykonywania długich zadań. Jest to ten sam kontener aplikacji, ale z niestandardowym poleceniem uruchamiania, aby uruchomić Celery zamiast Gunicorn.
- Kontener selerowy — podobny do powyższego, ale przeznaczony do zadań wywoływanych regularnie, takich jak usuwanie kont użytkowników, którzy nigdy nie potwierdzili swojego adresu e-mail.
- Pojemnik RabbitMQ. Celery wymaga brokera komunikatów do komunikowania się między pracownikami a aplikacją oraz przechowywania wyników zadań. RabbitMQ to powszechny wybór, ale możesz też użyć Redisa lub Kafki.
- Kontener bazy danych z PostgreSQL.
Naturalnym sposobem łatwego zarządzania wieloma kontenerami jest użycie Docker Compose. Ale najpierw będziemy musieli utworzyć plik Dockerfile, aby zbudować obraz kontenera dla naszej aplikacji. Umieśćmy to w katalogu projektu.

FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoTen plik nakazuje Dockerowi:
- Zainstaluj wszystkie zależności za pomocą Pipenv
- Dodaj folder aplikacji do kontenera
- Ujawnij port TCP 5000 hostowi
- Ustaw domyślne polecenie uruchamiania kontenera na wywołanie Gunicorn
Omówmy więcej, co dzieje się w ostatniej linii. Uruchamia Gunicorn określając klasę robotniczą jako geven. Gevent to lekka biblioteka współbieżności do kooperacyjnej wielozadaniowości. Zapewnia znaczny wzrost wydajności przy obciążeniach związanych z operacjami we/wy, zapewniając lepsze wykorzystanie procesora w porównaniu z wielozadaniowością z wywłaszczaniem systemu operacyjnego dla wątków. Parametr --workers to liczba procesów roboczych. Dobrym pomysłem jest ustawienie go na liczbę rdzeni na serwerze.
Gdy już mamy Dockerfile dla kontenera aplikacji, możemy stworzyć plik docker-compose.yml , który zdefiniuje wszystkie kontenery, których aplikacja będzie wymagała do uruchomienia.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationZdefiniowaliśmy następujące usługi:
-
broker-rabbitmq– kontener brokera komunikatów RabbitMQ. Dane uwierzytelniające połączenia są definiowane przez zmienne środowiskowe -
db-postgres– kontener PostgreSQL i jego dane uwierzytelniające -
migration– kontener aplikacji, który wykona migrację bazy danych za pomocą Flask-Migrate i zakończy. Kontenery API są od niego zależne i będą działać później. -
api– główny kontener aplikacji -
api-workeriapi-beat– Kontenery uruchamiające pracowników Celery dla zadań otrzymanych z API oraz zadań zaplanowanych
Każdy kontener aplikacji otrzyma również zmienną APP_ENV z polecenia docker docker-compose up .
Gdy mamy już gotowe wszystkie zasoby aplikacji, umieśćmy je na GitHub, co pomoże nam wdrożyć kod na serwerze.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterKonfiguracja serwera
Nasz kod znajduje się teraz na GitHub, a wszystko, co pozostało, to wykonanie wstępnej konfiguracji serwera i wdrożenie aplikacji. W moim przypadku serwerem jest instancja AWS z systemem AMI Linux. W przypadku innych wersji Linuksa instrukcje mogą się nieznacznie różnić. Zakładam też, że serwer ma już zewnętrzny adres IP, DNS jest skonfigurowany z rekordem A wskazującym na ten IP, a dla domeny wystawiane są certyfikaty SSL.
Wskazówka dotycząca bezpieczeństwa: nie zapomnij zezwolić na porty 80 i 443 dla ruchu HTTP(S), portu 22 dla SSH w konsoli hostingowej (lub używając iptables ) i zamknąć zewnętrzny dostęp do wszystkich innych portów! Pamiętaj, aby zrobić to samo dla protokołu IPv6 !
Instalowanie zależności
Po pierwsze, będziemy potrzebować Nginx i Dockera działającego na serwerze, plus Git do pobrania kodu. Zalogujmy się przez SSH i użyjmy menedżera pakietów, aby je zainstalować.
sudo yum install -y docker docker-compose nginx gitKonfiguracja Nginx
Następnym krokiem jest konfiguracja Nginx. Główny plik konfiguracyjny nginx.conf jest często dobry bez zmian. Pamiętaj jednak, aby sprawdzić, czy odpowiada Twoim potrzebom. Dla naszej aplikacji utworzymy nowy plik konfiguracyjny w folderze conf.d Konfiguracja najwyższego poziomu ma dyrektywę obejmującą wszystkie pliki .conf z niej.
cd /etc/nginx/conf.d sudo vim flask-deploy.confOto plik konfiguracyjny witryny Flask dla Nginx, wraz z bateriami. Posiada następujące cechy:
- SSL jest skonfigurowany. Powinieneś posiadać ważne certyfikaty dla swojej domeny, np. darmowy certyfikat Let's Encrypt.
- Żądania
www.your-site.comsą przekierowywane doyour-site.com - Żądania HTTP są przekierowywane na bezpieczny port HTTPS.
- Zwrotny serwer proxy jest skonfigurowany do przekazywania żądań do lokalnego portu 5000.
- Pliki statyczne są obsługiwane przez Nginx z folderu lokalnego.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } Po edycji pliku uruchom sudo nginx -s reload i sprawdź, czy są jakieś błędy.
Konfigurowanie poświadczeń GitHub
Dobrą praktyką jest posiadanie oddzielnego konta „deployment” VCS do wdrażania projektu i systemu CI/CD. W ten sposób nie ryzykujesz, ujawniając dane uwierzytelniające swojego konta. Aby dodatkowo chronić repozytorium projektu, możesz również ograniczyć uprawnienia takiego konta do dostępu tylko do odczytu. W przypadku repozytorium GitHub potrzebujesz do tego konta organizacji. Aby wdrożyć naszą aplikację demonstracyjną, po prostu utworzymy klucz publiczny na serwerze i zarejestrujemy go na GitHub, aby uzyskać dostęp do naszego projektu bez wprowadzania danych uwierzytelniających za każdym razem.
Aby utworzyć nowy klucz SSH, uruchom:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Następnie zaloguj się na GitHub i dodaj swój klucz publiczny z ~/.ssh/id_rsa.pub w ustawieniach konta.
Wdrażanie aplikacji
Ostatnie kroki są dość proste — musimy pobrać kod aplikacji z GitHub i uruchomić wszystkie kontenery za pomocą Docker Compose.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Dobrym pomysłem może być pominięcie -d (które uruchamia kontener w trybie odłączonym) przy pierwszym uruchomieniu, aby zobaczyć dane wyjściowe każdego kontenera bezpośrednio w terminalu i sprawdzić możliwe problemy. Inną opcją jest późniejsze sprawdzenie każdego kontenera za pomocą docker logs dokera. Zobaczmy, czy wszystkie nasze kontenery działają z docker ps.
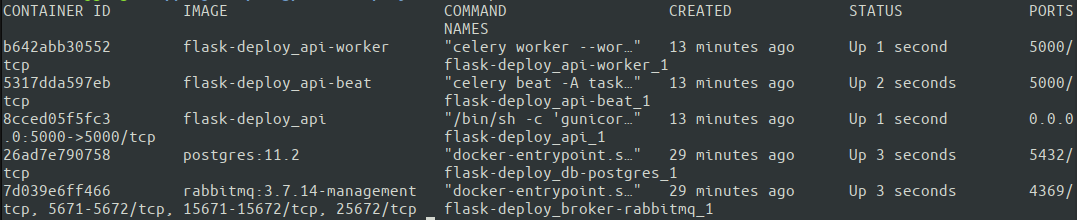
Świetnie. Wszystkie pięć kontenerów działa. Docker Compose przypisane nazwy kontenerów automatycznie na podstawie usługi określonej w docker-compose.yml. Teraz nadszedł czas, aby w końcu przetestować działanie całej konfiguracji! Najlepiej uruchomić testy z zewnętrznego komputera, aby upewnić się, że serwer ma prawidłowe ustawienia sieciowe.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtOtóż to. Mamy minimalistyczną, ale w pełni gotową do produkcji konfigurację naszej aplikacji działającej na instancji AWS. Mam nadzieję, że pomoże Ci to szybko rozpocząć tworzenie prawdziwej aplikacji i uniknąć niektórych typowych błędów! Pełny kod jest dostępny w repozytorium GitHub.
Wniosek
W tym artykule omówiliśmy niektóre z najlepszych praktyk dotyczących strukturyzacji, konfigurowania, pakowania i wdrażania aplikacji Flask w środowisku produkcyjnym. To bardzo obszerny temat, którego nie da się w pełni omówić w jednym wpisie na blogu. Oto lista ważnych pytań, na które nie odpowiedzieliśmy:
Ten artykuł nie obejmuje:
- Ciągła integracja i ciągłe wdrażanie
- Automatyczne testowanie
- Wysyłka dziennika
- Monitorowanie API
- Skalowanie aplikacji do wielu serwerów
- Ochrona danych uwierzytelniających w kodzie źródłowym
Możesz jednak dowiedzieć się, jak to zrobić, korzystając z innych świetnych zasobów na tym blogu. Na przykład, aby zapoznać się z rejestrowaniem, zobacz Rejestrowanie w języku Python: samouczek dogłębny lub ogólne omówienie CI/CD i testów automatycznych, zobacz Jak zbudować skuteczny początkowy potok wdrażania. Wprowadzanie ich w życie pozostawiam Tobie, Czytelniku, ćwiczeniem.
Dziękuje za przeczytanie!