
Zero to Hero: Ricette per la produzione di fiaschette
Pubblicato: 2022-03-11In qualità di ingegnere di apprendimento automatico ed esperto di visione artificiale, mi ritrovo a creare API e persino app Web con Flask sorprendentemente spesso. In questo post, voglio condividere alcuni suggerimenti e ricette utili per creare un'applicazione Flask completa e pronta per la produzione.
Tratteremo i seguenti argomenti:
- Gestione della configurazione. Qualsiasi applicazione reale ha un ciclo di vita con fasi specifiche, per lo meno si tratterebbe di sviluppo, test e distribuzione. In ogni fase, il codice dell'applicazione dovrebbe funzionare in un ambiente leggermente diverso, che richiede un diverso set di impostazioni, come stringhe di connessione al database, chiavi API esterne e URL.
- Applicazione Flask self-hosting con Gunicorn. Nonostante Flask abbia un web server integrato, come tutti sappiamo non è adatto alla produzione e necessita di essere messo dietro un vero web server in grado di comunicare con Flask attraverso un protocollo WSGI. Una scelta comune per questo è Gunicorn, un server HTTP WSGI Python.
- Servire file statici e richieste di proxy con Nginx. Pur essendo un web server HTTP, Gunicorn, a sua volta, è un application server non adatto ad affrontare il web. Ecco perché abbiamo bisogno di Nginx come proxy inverso e per servire file statici. Nel caso in cui dovessimo ridimensionare la nostra applicazione su più server, Nginx si occuperà anche del bilanciamento del carico.
- Distribuzione di un'app all'interno di contenitori Docker su un server Linux dedicato. La distribuzione in container è stata una parte essenziale della progettazione del software per un periodo piuttosto lungo. La nostra applicazione non è diversa e sarà ben confezionata nel proprio contenitore (più contenitori, in effetti).
- Configurazione e distribuzione di un database PostgreSQL per l'applicazione. La struttura del database e le migrazioni saranno gestite da Alembic con SQLAlchemy che fornisce la mappatura relazionale degli oggetti.
- Configurazione di una coda di attività Celery per gestire attività di lunga durata. Ogni applicazione alla fine richiederà questo per scaricare tempo o processi ad alta intensità di calcolo, che si tratti di invio di posta, gestione automatica del database o elaborazione di immagini caricate, dai thread del server Web su lavoratori esterni.
Creazione dell'app Flask
Iniziamo creando un codice dell'applicazione e degli asset. Tieni presente che in questo post non affronterò la corretta struttura dell'applicazione Flask. L'app demo è composta da un numero minimo di moduli e pacchetti per motivi di brevità e chiarezza.
Innanzitutto, crea una struttura di directory e inizializza un repository Git vuoto.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtSuccessivamente, aggiungeremo il codice.
config/__init__.py
Nel modulo di configurazione, definiremo il nostro piccolo framework di gestione della configurazione. L'idea è di fare in modo che l'app si comporti in base alla configurazione preimpostata selezionata dalla variabile di ambiente APP_ENV , inoltre, aggiungere un'opzione per sovrascrivere qualsiasi impostazione di configurazione con una variabile di ambiente specifica, se necessario.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/impostazioni.py
Questo è un insieme di classi di configurazione, una delle quali è selezionata dalla variabile APP_ENV . Quando l'applicazione viene eseguita, il codice in __init__.py istanzia una di queste classi sovrascrivendo i valori del campo con variabili di ambiente specifiche, se presenti. Useremo un oggetto di configurazione finale durante l'inizializzazione della configurazione di Flask e Celery in un secondo momento.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Trueattività/__init__.py
Il pacchetto delle attività contiene il codice di inizializzazione del sedano. Il pacchetto Config, che avrà già tutte le impostazioni copiate a livello di modulo al momento dell'inizializzazione, viene utilizzato per aggiornare l'oggetto di configurazione di Celery nel caso in cui avremo alcune impostazioni specifiche di Celery in futuro, ad esempio attività pianificate e timeout di lavoro.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()task/celery_worker.py
Questo modulo è necessario per avviare e inizializzare un lavoratore Celery, che verrà eseguito in un contenitore Docker separato. Inizializza il contesto dell'applicazione Flask per avere accesso allo stesso ambiente dell'applicazione. Se ciò non è necessario, queste linee possono essere rimosse in sicurezza.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Poi va il pacchetto API, che definisce l'API REST usando il pacchetto Flask-Restful. La nostra app è solo una demo e avrà solo due endpoint:
-
/process_data– Avvia un'operazione fittizia su un lavoratore Celery e restituisce l'ID di una nuova attività. -
/tasks/<task_id>– Restituisce lo stato di un'attività in base all'ID attività.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')modelli/__init__.py
Ora aggiungeremo un modello SQLAlchemy per l'oggetto User e un codice di inizializzazione del motore di database. L'oggetto User non verrà utilizzato dalla nostra app demo in alcun modo significativo, ma ne avremo bisogno per assicurarci che le migrazioni del database funzionino e che l'integrazione SQLAlchemy-Flask sia impostata correttamente.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Nota come l'UUID viene generato automaticamente come ID oggetto per impostazione predefinita.
app.py
Infine, creiamo un file principale dell'applicazione Flask.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Eccoci qui:
- Configurazione della registrazione di base in un formato appropriato con ora, livello e ID processo
- Definizione della funzione di creazione dell'app Flask con inizializzazione API e "Hello, world!" pagina
- Definizione di un punto di ingresso per eseguire l'app durante il tempo di sviluppo
wsgi.py
Inoltre, avremo bisogno di un modulo separato per eseguire l'applicazione Flask con Gunicorn. Avrà solo due righe:
from app import create_app app = create_app()Il codice dell'applicazione è pronto. Il nostro prossimo passo è creare una configurazione Docker.
Costruzione di container Docker
La nostra applicazione richiederà più contenitori Docker per l'esecuzione:
- Contenitore dell'applicazione per servire pagine basate su modelli ed esporre gli endpoint API. È una buona idea dividere queste due funzioni nella produzione, ma non abbiamo pagine basate su modelli nella nostra app demo. Il contenitore eseguirà il server Web Gunicorn che comunicherà con Flask tramite il protocollo WSGI.
- Contenitore lavoratore sedano per eseguire compiti lunghi. Questo è lo stesso contenitore dell'applicazione, ma con un comando di esecuzione personalizzato per avviare Celery, invece di Gunicorn.
- Celery beat container, simile al precedente, ma per attività richiamate con una pianificazione regolare, come la rimozione di account di utenti che non hanno mai confermato la propria posta elettronica.
- Contenitore RabbitMQ. Celery richiede un broker di messaggi per comunicare tra i lavoratori e l'app e archiviare i risultati delle attività. RabbitMQ è una scelta comune, ma puoi anche usare Redis o Kafka.
- Contenitore di database con PostgreSQL.
Un modo naturale per gestire facilmente più contenitori è utilizzare Docker Compose. Ma prima, dovremo creare un Dockerfile per creare un'immagine del contenitore per la nostra applicazione. Mettiamolo nella directory del progetto.

FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoQuesto file indica a Docker di:
- Installa tutte le dipendenze usando Pipenv
- Aggiungi una cartella dell'applicazione al contenitore
- Esporre la porta TCP 5000 all'host
- Imposta il comando di avvio predefinito del contenitore su una chiamata Gunicorn
Discutiamo di più cosa succede nell'ultima riga. Esegue Gunicorn specificando la classe operaia come gevent. Gevent è una libreria di concorrenza leggera per il multitasking cooperativo. Offre considerevoli miglioramenti delle prestazioni sui carichi legati all'I/O, fornendo un migliore utilizzo della CPU rispetto al multitasking preventivo del sistema operativo per i thread. Il parametro --workers è il numero di processi di lavoro. È una buona idea impostarlo uguale a un numero di core sul server.
Una volta che abbiamo un Dockerfile per il contenitore dell'applicazione, possiamo creare un file docker-compose.yml , che definirà tutti i contenitori che l'applicazione richiederà per essere eseguita.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationAbbiamo definito i seguenti servizi:
-
broker-rabbitmq– Un contenitore di broker di messaggi RabbitMQ. Le credenziali di connessione sono definite da variabili di ambiente -
db-postgres– Un contenitore PostgreSQL e le sue credenziali -
migration: un contenitore di app che eseguirà la migrazione del database con Flask-Migrate ed esce. I contenitori API dipendono da esso e verranno eseguiti in seguito. -
api– Il contenitore principale dell'applicazione -
api-workereapi-beat: contenitori che eseguono Celery worker per le attività ricevute dall'API e le attività pianificate
Ogni contenitore di app riceverà anche la variabile APP_ENV dal comando docker docker-compose up .
Una volta che tutte le risorse dell'applicazione sono pronte, mettiamole su GitHub, che ci aiuterà a distribuire il codice sul server.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterConfigurazione del server
Il nostro codice è ora su un GitHub e tutto ciò che resta è eseguire la configurazione iniziale del server e distribuire l'applicazione. Nel mio caso, il server è un'istanza AWS che esegue AMI Linux. Per altre versioni di Linux, le istruzioni potrebbero differire leggermente. Presumo inoltre che il server abbia già un indirizzo IP esterno, che il DNS sia configurato con un record A che punta a questo IP e che vengano emessi certificati SSL per il dominio.
Suggerimento per la sicurezza: non dimenticare di consentire le porte 80 e 443 per il traffico HTTP(S), la porta 22 per SSH nella tua console di hosting (o usando iptables ) e chiudere l'accesso esterno a tutte le altre porte! Assicurati di fare lo stesso per il protocollo IPv6 !
Installazione delle dipendenze
Innanzitutto, avremo bisogno di Nginx e Docker in esecuzione sul server, oltre a Git per estrarre il codice. Accediamo tramite SSH e utilizziamo un gestore di pacchetti per installarli.
sudo yum install -y docker docker-compose nginx gitConfigurazione di Nginx
Il prossimo passo è configurare Nginx. Il file di configurazione principale nginx.conf è spesso buono così com'è. Tuttavia, assicurati di controllare se è adatto alle tue esigenze. Per la nostra app, creeremo un nuovo file di configurazione in una cartella conf.d La configurazione di primo livello ha una direttiva per includere tutti i file .conf da essa.
cd /etc/nginx/conf.d sudo vim flask-deploy.confEcco un file di configurazione del sito Flask per Nginx, batterie incluse. Ha le seguenti caratteristiche:
- SSL è configurato. Dovresti disporre di certificati validi per il tuo dominio, ad esempio un certificato Let's Encrypt gratuito.
- Le richieste di
www.your-site.comvengono reindirizzate ayour-site.com - Le richieste HTTP vengono reindirizzate alla porta HTTPS sicura.
- Il proxy inverso è configurato per passare le richieste alla porta locale 5000.
- I file statici sono serviti da Nginx da una cartella locale.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } Dopo aver modificato il file, esegui sudo nginx -s reload e verifica se ci sono errori.
Configurazione delle credenziali GitHub
È buona norma disporre di un account VCS di "distribuzione" separato per l'implementazione del progetto e del sistema CI/CD. In questo modo non rischi esponendo le credenziali del tuo account. Per proteggere ulteriormente il repository del progetto, puoi anche limitare le autorizzazioni di tale account all'accesso in sola lettura. Per un repository GitHub, avrai bisogno di un account dell'organizzazione per farlo. Per distribuire la nostra applicazione demo, creeremo semplicemente una chiave pubblica sul server e la registreremo su GitHub per ottenere l'accesso al nostro progetto senza inserire le credenziali ogni volta.
Per creare una nuova chiave SSH, eseguire:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Quindi accedi a GitHub e aggiungi la tua chiave pubblica da ~/.ssh/id_rsa.pub nelle impostazioni dell'account.
Distribuzione di un'app
I passaggi finali sono piuttosto semplici: dobbiamo ottenere il codice dell'applicazione da GitHub e avviare tutti i contenitori con Docker Compose.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Potrebbe essere una buona idea omettere -d (che avvia il contenitore in modalità scollegata) per una prima esecuzione per vedere l'output di ciascun contenitore direttamente nel terminale e verificare possibili problemi. Un'altra opzione è ispezionare ogni singolo container con docker logs in seguito. Vediamo se tutti i nostri container sono in esecuzione con docker ps.
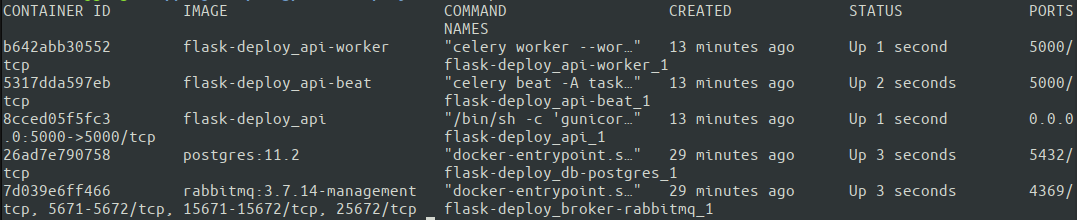
Grande. Tutti e cinque i container sono attivi e funzionanti. Docker Compose nomi di contenitori assegnati automaticamente in base al servizio specificato in docker-compose.yml. Ora è il momento di testare finalmente come funziona l'intera configurazione! È meglio eseguire i test da una macchina esterna per assicurarsi che il server disponga delle impostazioni di rete corrette.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtQuesto è tutto. Abbiamo una configurazione minimalista, ma completamente pronta per la produzione della nostra app in esecuzione su un'istanza AWS. Spero che ti aiuterà a iniziare a creare rapidamente un'applicazione nella vita reale ed evitare alcuni errori comuni! Il codice completo è disponibile su un repository GitHub.
Conclusione
In questo articolo, abbiamo discusso alcune delle migliori pratiche per strutturare, configurare, impacchettare e distribuire un'applicazione Flask alla produzione. Questo è un argomento molto grande, impossibile da coprire completamente in un singolo post sul blog. Ecco un elenco di domande importanti che non abbiamo affrontato:
Questo articolo non copre:
- Integrazione continua e distribuzione continua
- Test automatico
- Spedizione log
- Monitoraggio API
- Ridimensionamento di un'applicazione su più server
- Protezione delle credenziali nel codice sorgente
Tuttavia, puoi imparare come farlo usando alcune delle altre fantastiche risorse su questo blog. Ad esempio, per esplorare la registrazione, vedere Registrazione Python: un'esercitazione approfondita oppure per una panoramica generale su CI/CD e test automatizzati, vedere Come creare una pipeline di distribuzione iniziale efficace. Lascio a te, lettore, l'attuazione di questi come esercizio.
Grazie per aver letto!