
Zero to Hero: Flask Production Recipes
Publicat: 2022-03-11Ca inginer de învățare automată și expert în viziunea computerizată, mă trezesc să creez API-uri și chiar aplicații web cu Flask surprinzător de des. În această postare, vreau să împărtășesc câteva sfaturi și rețete utile pentru construirea unei aplicații Flask complete, gata de producție.
Vom acoperi următoarele subiecte:
- Managementul configurației. Orice aplicație reală are un ciclu de viață cu etape specifice - cel puțin, ar fi dezvoltarea, testarea și implementarea. În fiecare etapă, codul aplicației ar trebui să funcționeze într-un mediu ușor diferit, ceea ce necesită un set diferit de setări, cum ar fi șiruri de conexiune la baza de date, chei API externe și adrese URL.
- Aplicație Flask cu auto-găzduire cu Gunicorn. Deși Flask are un server web încorporat, după cum știm cu toții, nu este potrivit pentru producție și trebuie să fie pus în spatele unui server web real capabil să comunice cu Flask printr-un protocol WSGI. O alegere comună pentru asta este Gunicorn—un server HTTP Python WSGI.
- Servirea fișierelor statice și cererea de proxy cu Nginx. Deși este un server web HTTP, Gunicorn, la rândul său, este un server de aplicații care nu este potrivit pentru a face față internetului. De aceea avem nevoie de Nginx ca proxy invers și pentru a servi fișiere statice. În cazul în care trebuie să ne extindem aplicația pe mai multe servere, Nginx se va ocupa și de echilibrarea sarcinii.
- Implementarea unei aplicații în containerele Docker pe un server Linux dedicat. Implementarea containerizată a fost o parte esențială a designului software de destul de mult timp. Aplicația noastră nu este diferită și va fi ambalată îngrijit în propriul container (de fapt, mai multe containere).
- Configurarea și implementarea unei baze de date PostgreSQL pentru aplicație. Structura și migrările bazei de date vor fi gestionate de Alambic cu SQLAlchemy oferind mapare obiect-relațională.
- Configurarea unei cozi de sarcini Telina pentru a gestiona sarcinile de lungă durată. Fiecare aplicație va necesita în cele din urmă acest lucru pentru a descărca procese intensive de timp sau de calcul - fie că este vorba despre trimiterea de e-mailuri, menținerea automată a bazei de date sau procesarea imaginilor încărcate - din firele de execuție ale serverului web pe lucrătorii externi.
Crearea aplicației Flask
Să începem prin a crea un cod de aplicație și elemente. Vă rugăm să rețineți că nu voi aborda structura adecvată a aplicației Flask în această postare. Aplicația demo constă dintr-un număr minim de module și pachete, de dragul conciziei și clarității.
Mai întâi, creați o structură de directoare și inițializați un depozit Git gol.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtÎn continuare, vom adăuga codul.
config/__init__.py
În modulul de configurare, vom defini micul nostru cadru de gestionare a configurației. Ideea este de a face aplicația să se comporte în funcție de configurația prestabilită selectată de variabila de mediu APP_ENV , plus, adăugați o opțiune pentru a înlocui orice setare de configurare cu o anumită variabilă de mediu, dacă este necesar.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/settings.py
Acesta este un set de clase de configurare, dintre care una este selectată de variabila APP_ENV . Când aplicația rulează, codul din __init__.py va instanția una dintre aceste clase, suprascriind valorile câmpului cu variabile de mediu specifice, dacă acestea sunt prezente. Vom folosi un obiect de configurare final atunci când inițializam configurația Flask și Celery mai târziu.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Truetasks/__init__.py
Pachetul de sarcini conține codul de inițializare de țelină. Pachetul de configurare, care va avea deja toate setările copiate la nivel de modul la inițializare, este folosit pentru a actualiza obiectul de configurare Celery în cazul în care vom avea unele setări specifice lui Celery în viitor, de exemplu, sarcinile programate și timeout-urile lucrătorilor.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()tasks/celery_worker.py
Acest modul este necesar pentru a porni și inițializa un lucrător de țelină, care va rula într-un container Docker separat. Inițializează contextul aplicației Flask pentru a avea acces la același mediu ca și aplicația. Dacă acest lucru nu este necesar, aceste linii pot fi îndepărtate în siguranță.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Urmează pachetul API, care definește API-ul REST folosind pachetul Flask-Restful. Aplicația noastră este doar o demonstrație și va avea doar două puncte finale:
-
/process_data– Pornește o operațiune de lungă durată pe un lucrător de țelină și returnează ID-ul unei sarcini noi. -
/tasks/<task_id>– Returnează starea unei sarcini după ID-ul sarcinii.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')model/__init__.py
Acum vom adăuga un model SQLAlchemy pentru obiectul User și un cod de inițializare a motorului bazei de date. Obiectul User nu va fi folosit de aplicația noastră demonstrativă în niciun mod semnificativ, dar vom avea nevoie de el pentru a ne asigura că migrarea bazei de date funcționează și integrarea SQLAlchemy-Flask este configurată corect.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Observați modul în care UUID este generat automat ca ID de obiect prin expresie implicită.
app.py
În cele din urmă, să creăm un fișier principal al aplicației Flask.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Iată-ne:
- Configurarea înregistrării de bază într-un format adecvat cu timpul, nivelul și ID-ul procesului
- Definirea funcției de creare a aplicației Flask cu inițializare API și „Bună, lume!” pagină
- Definirea unui punct de intrare pentru a rula aplicația în timpul dezvoltării
wsgi.py
De asemenea, vom avea nevoie de un modul separat pentru a rula aplicația Flask cu Gunicorn. Va avea doar două rânduri:
from app import create_app app = create_app()Codul aplicației este gata. Următorul nostru pas este să creăm o configurație Docker.
Construirea de containere Docker
Aplicația noastră va necesita mai multe containere Docker pentru a rula:
- Container de aplicații pentru a difuza pagini șablon și a expune punctele finale API. Este o idee bună să împărțim aceste două funcții în producție, dar nu avem nicio pagină șablon în aplicația noastră demo. Containerul va rula serverul web Gunicorn care va comunica cu Flask prin protocolul WSGI.
- Container pentru muncitor de țelină pentru a executa sarcini lungi. Acesta este același container de aplicații, dar cu comanda de rulare personalizată pentru a lansa Țelina, în loc de Gunicorn.
- Container pentru bătăi de țelină — similar cu cel de mai sus, dar pentru sarcini invocate pe un program regulat, cum ar fi eliminarea conturilor utilizatorilor care nu și-au confirmat niciodată e-mailul.
- Container RabbitMQ. Țelina necesită un broker de mesaje pentru a comunica între lucrători și aplicație și pentru a stoca rezultatele sarcinilor. RabbitMQ este o alegere comună, dar puteți folosi și Redis sau Kafka.
- Container baze de date cu PostgreSQL.
O modalitate naturală de a gestiona cu ușurință mai multe containere este utilizarea Docker Compose. Dar mai întâi, va trebui să creăm un Dockerfile pentru a construi o imagine container pentru aplicația noastră. Să-l punem în directorul proiectului.
FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoAcest fișier îi cere lui Docker să:

- Instalați toate dependențele folosind Pipenv
- Adăugați un folder de aplicație în container
- Expuneți portul TCP 5000 la gazdă
- Setați comanda implicită de pornire a containerului la un apel Gunicorn
Să discutăm mai multe despre ce se întâmplă în ultima linie. Rulează Gunicorn specificând clasa lucrătorilor ca gevent. Gevent este o libră de concurență ușoară pentru multitasking cooperativ. Oferă câștiguri considerabile de performanță la încărcările legate de I/O, oferind o utilizare mai bună a procesorului în comparație cu operarea multitasking preventivă pentru fire. Parametrul --workers este numărul de procese de lucru. Este o idee bună să-l setați egal cu un număr de nuclee pe server.
Odată ce avem un container Dockerfile pentru aplicație, putem crea un fișier docker-compose.yml , care va defini toate containerele pe care aplicația va avea nevoie pentru a rula.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationAm definit următoarele servicii:
-
broker-rabbitmq– Un container de broker de mesaje RabbitMQ. Acreditările de conectare sunt definite de variabilele de mediu -
db-postgres– Un container PostgreSQL și acreditările sale -
migration– Un container de aplicație care va efectua migrarea bazei de date cu Flask-Migrate și va ieși. Containerele API depind de el și vor rula ulterior. -
api– containerul principal al aplicației -
api-workerșiapi-beat– Containere care rulează lucrători de țelină pentru sarcinile primite de la API și sarcinile programate
Fiecare container de aplicație va primi, de asemenea, variabila APP_ENV de la comanda docker-compose docker-compose up .
Odată ce avem toate activele aplicației pregătite, să le punem pe GitHub, ceea ce ne va ajuta să implementăm codul pe server.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterConfigurarea serverului
Codul nostru se află acum pe un GitHub și tot ce mai rămâne este să efectuați configurarea inițială a serverului și să implementați aplicația. În cazul meu, serverul este o instanță AWS care rulează AMI Linux. Pentru alte variante de Linux, instrucțiunile pot diferi ușor. De asemenea, presupun că serverul are deja o adresă IP externă, DNS este configurat cu înregistrarea A care indică acest IP și certificate SSL sunt emise pentru domeniu.
Sfat de securitate: nu uitați să permiteți porturile 80 și 443 pentru traficul HTTP(S), portul 22 pentru SSH în consola dvs. de găzduire (sau să utilizați iptables ) și să închideți accesul extern la toate celelalte porturi! Asigurați-vă că faceți același lucru pentru protocolul IPv6 !
Instalarea dependențelor
În primul rând, vom avea nevoie de Nginx și Docker care rulează pe server, plus Git pentru a extrage codul. Să ne autentificăm prin SSH și să folosim un manager de pachete pentru a le instala.
sudo yum install -y docker docker-compose nginx gitConfigurarea Nginx
Următorul pas este configurarea Nginx. Fișierul principal de configurare nginx.conf este adesea bun așa cum este. Totuși, asigurați-vă că verificați dacă se potrivește nevoilor dvs. Pentru aplicația noastră, vom crea un nou fișier de configurare într-un folder conf.d Configurația de nivel superior are o directivă pentru a include toate fișierele .conf din ea.
cd /etc/nginx/conf.d sudo vim flask-deploy.confIată un fișier de configurare a site-ului Flask pentru Nginx, bateriile incluse. Are următoarele caracteristici:
- SSL este configurat. Ar trebui să aveți certificate valide pentru domeniul dvs., de exemplu, un certificat Let's Encrypt gratuit.
- Solicitările
www.your-site.comsunt redirecționate cătreyour-site.com - Solicitările HTTP sunt redirecționate către portul HTTPS securizat.
- Reverse proxy este configurat pentru a transmite cereri către portul local 5000.
- Fișierele statice sunt servite de Nginx dintr-un folder local.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } După editarea fișierului, rulați sudo nginx -s reload și vedeți dacă există erori.
Configurarea acreditărilor GitHub
Este o bună practică să aveți un cont separat VCS de „implementare” pentru implementarea proiectului și a sistemului CI/CD. În acest fel, nu riscați expunând acreditările propriului cont. Pentru a proteja și mai mult depozitul de proiect, puteți, de asemenea, să limitați permisiunile unui astfel de cont la acces numai în citire. Pentru un depozit GitHub, veți avea nevoie de un cont de organizație pentru a face asta. Pentru a implementa aplicația noastră demonstrativă, vom crea doar o cheie publică pe server și o vom înregistra pe GitHub pentru a avea acces la proiectul nostru fără a introduce acreditările de fiecare dată.
Pentru a crea o nouă cheie SSH, rulați:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Apoi conectați-vă pe GitHub și adăugați cheia publică din ~/.ssh/id_rsa.pub în setările contului.
Implementarea unei aplicații
Pașii finali sunt destul de simpli – trebuie să obținem codul aplicației din GitHub și să pornim toate containerele cu Docker Compose.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Ar putea fi o idee bună să omiteți -d (care pornește containerul în modul detașat) pentru o primă rulare pentru a vedea rezultatul fiecărui container chiar în terminal și a verifica eventualele probleme. O altă opțiune este să inspectați ulterior fiecare container individual cu docker logs . Să vedem dacă toate containerele noastre rulează cu docker ps.
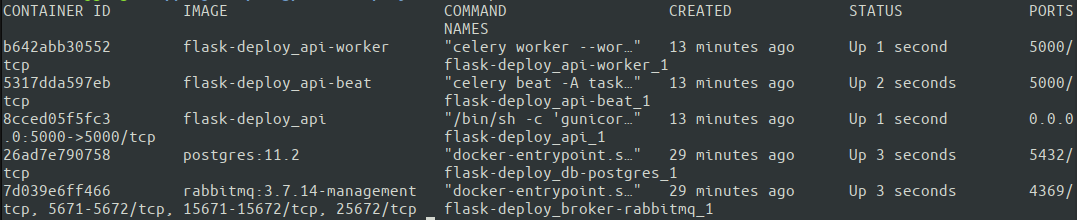
Grozav. Toate cele cinci containere sunt în funcțiune. Docker Compose a atribuit automat nume de containere pe baza serviciului specificat în docker-compose.yml. Acum este timpul să testăm în sfârșit modul în care funcționează întreaga configurație! Cel mai bine este să rulați testele de pe o mașină externă pentru a vă asigura că serverul are setările de rețea corecte.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtAsta e. Avem o configurație minimalistă, dar complet pregătită pentru producție a aplicației noastre care rulează pe o instanță AWS. Sper că vă va ajuta să începeți rapid să construiți o aplicație reală și să evitați unele greșeli comune! Codul complet este disponibil pe un depozit GitHub.
Concluzie
În acest articol, am discutat câteva dintre cele mai bune practici de structurare, configurare, ambalare și implementare a unei aplicații Flask în producție. Acesta este un subiect foarte mare, imposibil de acoperit pe deplin într-o singură postare pe blog. Iată o listă de întrebări importante pe care nu le-am abordat:
Acest articol nu acoperă:
- Integrare continuă și implementare continuă
- Testare automată
- Expediere busteni
- Monitorizare API
- Extinderea unei aplicații pe mai multe servere
- Protecția acreditărilor în codul sursă
Cu toate acestea, puteți învăța cum să faceți asta folosind unele dintre celelalte resurse grozave de pe acest blog. De exemplu, pentru a explora înregistrarea în jurnal, consultați Python Logging: un tutorial aprofundat sau pentru o prezentare generală despre CI/CD și testarea automată, consultați Cum să construiți o conductă de implementare inițială eficientă. Vă las punerea în aplicare a acestora ca exercițiu pe seama dumneavoastră, cititorului.
Multumesc pentru lectura!