
ゼロからヒーローへ:フラスコ生産レシピ
公開: 2022-03-11機械学習エンジニアおよびコンピュータービジョンの専門家として、私は驚くほど頻繁にFlaskを使用してAPIやWebアプリを作成しています。 この投稿では、完全な本番環境に対応したFlaskアプリケーションを構築するためのヒントと便利なレシピを共有したいと思います。
次のトピックについて説明します。
- 構成管理。 実際のアプリケーションには、特定の段階のライフサイクルがあります。少なくとも、開発、テスト、および展開になります。 各段階で、アプリケーションコードはわずかに異なる環境で動作する必要があります。これには、データベース接続文字列、外部APIキー、URLなどの異なる設定セットが必要です。
- Gunicornを使用したセルフホスティングFlaskアプリケーション。 FlaskにはWebサーバーが組み込まれていますが、ご存知のとおり、本番環境には適していないため、WSGIプロトコルを介してFlaskと通信できる実際のWebサーバーの背後に配置する必要があります。 そのための一般的な選択肢は、PythonWSGIHTTPサーバーであるGunicornです。
- Nginxで静的ファイルとプロキシリクエストを提供します。 GunicornはHTTPWebサーバーでありながら、Webに対応するのに適していないアプリケーションサーバーです。 そのため、リバースプロキシとして静的ファイルを提供するためにNginxが必要です。 アプリケーションを複数のサーバーにスケールアップする必要がある場合は、Nginxが負荷分散も処理します。
- 専用Linuxサーバー上のDockerコンテナー内にアプリをデプロイします。 コンテナ化された展開は、かなり長い間、ソフトウェア設計の重要な部分でした。 私たちのアプリケーションも例外ではなく、独自のコンテナー(実際には複数のコンテナー)にきちんとパッケージ化されます。
- アプリケーション用のPostgreSQLデータベースの構成とデプロイ。 データベースの構造と移行は、オブジェクトリレーショナルマッピングを提供するSQLAlchemyを使用してAlembicによって管理されます。
- 長時間実行されるタスクを処理するためのCeleryタスクキューの設定。 すべてのアプリケーションは、メール送信、自動データベースハウスキーピング、アップロードされた画像の処理など、時間や計算集約型のプロセスを外部ワーカーのWebサーバースレッドからオフロードするために、最終的にこれを必要とします。
フラスコアプリの作成
まず、アプリケーションコードとアセットを作成しましょう。 この投稿では、適切なFlaskアプリケーション構造については説明しませんのでご注意ください。 デモアプリは、簡潔さと明確さのために、最小限の数のモジュールとパッケージで構成されています。
まず、ディレクトリ構造を作成し、空のGitリポジトリを初期化します。
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txt次に、コードを追加します。
config / __ init__.py
構成モジュールでは、小さな構成管理フレームワークを定義します。 アイデアは、 APP_ENV環境変数によって選択された構成プリセットに従ってアプリを動作させることです。さらに、必要に応じて、特定の環境変数で構成設定をオーバーライドするオプションを追加します。
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig / settings.py
これは構成クラスのセットであり、そのうちの1つはAPP_ENV変数によって選択されます。 アプリケーションが実行されると、 __init__.pyのコードは、これらのクラスの1つをインスタンス化し、フィールド値が存在する場合は、特定の環境変数でオーバーライドします。 後でFlaskとCeleryの構成を初期化するときに、最終的な構成オブジェクトを使用します。
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Trueタスク/__init__.py
タスクパッケージには、Celery初期化コードが含まれています。 初期化時にモジュールレベルですべての設定がすでにコピーされている構成パッケージは、将来、スケジュールされたタスクやワーカーのタイムアウトなど、Celery固有の設定がある場合に備えて、Celery構成オブジェクトを更新するために使用されます。
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()タスク/celery_worker.py
このモジュールは、別のDockerコンテナーで実行されるCeleryワーカーを起動および初期化するために必要です。 これは、Flaskアプリケーションコンテキストを初期化して、アプリケーションと同じ環境にアクセスできるようにします。 それが必要ない場合は、これらの行を安全に削除できます。
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi / __init__。py
次は、Flask-Restfulパッケージを使用してRESTAPIを定義するAPIパッケージです。 私たちのアプリは単なるデモであり、エンドポイントは2つだけです。
-
/process_data– Celeryワーカーでダミーのlong操作を開始し、新しいタスクのIDを返します。 -
/tasks/<task_id>–タスクIDごとにタスクのステータスを返します。
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')モデル/__init__.py
次に、 UserオブジェクトのSQLAlchemyモデルと、データベースエンジンの初期化コードを追加します。 Userオブジェクトは、デモアプリで意味のある方法で使用されることはありませんが、データベースの移行が機能し、SQLAlchemyとFlaskの統合が正しく設定されていることを確認するために必要になります。
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)UUIDがデフォルトの式でオブジェクトIDとして自動的に生成される方法に注意してください。
app.py
最後に、メインのFlaskアプリケーションファイルを作成しましょう。
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>ここにあります:
- 時間、レベル、プロセスIDを使用して適切な形式で基本的なログを構成する
- API初期化と「Hello、world!」を使用してFlaskアプリ作成関数を定義します。 ページ
- 開発時にアプリを実行するためのエントリポイントを定義する
wsgi.py
また、GunicornでFlaskアプリケーションを実行するには別のモジュールが必要になります。 2行だけになります。
from app import create_app app = create_app()アプリケーションコードの準備ができました。 次のステップは、Docker構成を作成することです。
Dockerコンテナの構築
このアプリケーションを実行するには、複数のDockerコンテナが必要です。
- テンプレート化されたページを提供し、APIエンドポイントを公開するためのアプリケーションコンテナ。 これらの2つの関数を本番環境で分割することをお勧めしますが、デモアプリにはテンプレート化されたページがありません。 コンテナは、WSGIプロトコルを介してFlaskと通信するGunicornWebサーバーを実行します。
- 長いタスクを実行するためのCeleryワーカーコンテナ。 これは同じアプリケーションコンテナですが、Gunicornの代わりにCeleryを起動するカスタム実行コマンドがあります。
- セロリビートコンテナ-上記と同様ですが、メールを確認したことのないユーザーのアカウントを削除するなど、定期的に呼び出されるタスク用です。
- RabbitMQコンテナ。 Celeryには、ワーカーとアプリの間で通信し、タスクの結果を保存するためのメッセージブローカーが必要です。 RabbitMQが一般的な選択ですが、RedisまたはKafkaを使用することもできます。
- PostgreSQLを使用したデータベースコンテナ。
複数のコンテナーを簡単に管理する自然な方法は、DockerComposeを使用することです。 ただし、最初に、アプリケーションのコンテナイメージを構築するためのDockerfileを作成する必要があります。 それをプロジェクトディレクトリに置きましょう。
FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoこのファイルはDockerに次のように指示します。

- Pipenvを使用してすべての依存関係をインストールします
- コンテナにアプリケーションフォルダを追加します
- TCPポート5000をホストに公開します
- コンテナのデフォルトの起動コマンドをGunicornの呼び出しに設定します
最後の行で何が起こるかについてもっと話し合いましょう。 ワーカークラスをgeventとして指定してGunicornを実行します。 Geventは、協調マルチタスク用の軽量の同時実行ライブラリです。 I / Oバウンドの負荷でパフォーマンスが大幅に向上し、スレッドのOSプリエンプティブマルチタスクと比較してCPU使用率が向上します。 --workersパラメーターは、ワーカープロセスの数です。 サーバー上のコアの数と等しくなるように設定することをお勧めします。
アプリケーションコンテナ用のDockerfileを取得したら、docker docker-compose.ymlファイルを作成できます。このファイルは、アプリケーションの実行に必要なすべてのコンテナを定義します。
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration次のサービスを定義しました。
-
broker-rabbitmq–RabbitMQメッセージブローカーコンテナー。 接続クレデンシャルは環境変数によって定義されます db-postgresコンテナとそのクレデンシャルmigration–Flaskを使用してデータベースの移行を実行するアプリコンテナ-移行して終了します。 APIコンテナはそれに依存しており、後で実行されます。-
api–メインアプリケーションコンテナ api-workerおよびapi-beat–APIから受信したタスクとスケジュールされたタスクのためにCeleryワーカーを実行するコンテナー
各アプリコンテナは、docker docker-compose up composeupコマンドからAPP_ENV変数も受け取ります。
すべてのアプリケーションアセットの準備ができたら、それらをGitHubに配置します。これは、サーバーにコードをデプロイするのに役立ちます。
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterサーバーの構成
私たちのコードは現在GitHubにあり、あとはサーバーの初期構成を実行してアプリケーションをデプロイするだけです。 私の場合、サーバーはAMILinuxを実行しているAWSインスタンスです。 他のLinuxフレーバーの場合、手順が若干異なる場合があります。 また、サーバーにはすでに外部IPアドレスがあり、DNSはこのIPを指すAレコードで構成されており、ドメインに対してSSL証明書が発行されていると想定しています。
セキュリティのヒント:ホスティングコンソールで(またはiptablesを使用して)HTTP(S)トラフィック用にポート80と443、SSH用にポート22を許可し、他のすべてのポートへの外部アクセスを閉じることを忘れないでください! IPv6プロトコルについても同じことを必ず行ってください。
依存関係のインストール
まず、サーバー上でNginxとDockerを実行し、さらにコードをプルするためにGitを実行する必要があります。 SSH経由でログインし、パッケージマネージャーを使用してインストールしましょう。
sudo yum install -y docker docker-compose nginx gitNginxの構成
次のステップは、Nginxを構成することです。 多くの場合、メインのnginx.conf構成ファイルはそのままで十分です。 それでも、それがあなたのニーズに合っているかどうかを必ず確認してください。 このアプリでは、 conf.dフォルダーに新しい構成ファイルを作成します。 トップレベルの構成には、そこからすべての.confファイルを含めるように指示されています。
cd /etc/nginx/conf.d sudo vim flask-deploy.confこれは、バッテリーを含むNginxのFlaskサイト構成ファイルです。 次の機能があります。
- SSLが構成されています。 ドメインに有効な証明書が必要です。たとえば、無料のLet'sEncrypt証明書が必要です。
-
www.your-site.comリクエストはyour-site.comにリダイレクトされます - HTTPリクエストは安全なHTTPSポートにリダイレクトされます。
- リバースプロキシは、ローカルポート5000に要求を渡すように構成されています。
- 静的ファイルは、ローカルフォルダーからNginxによって提供されます。
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } ファイルを編集した後、 sudo nginx -s reloadを実行して、エラーがあるかどうかを確認します。
GitHubクレデンシャルの設定
プロジェクトとCI/CDシステムを展開するための個別の「展開」VCSアカウントを用意することをお勧めします。 このようにして、自分のアカウントの資格情報を公開することでリスクを冒すことはありません。 プロジェクトリポジトリをさらに保護するために、そのようなアカウントの権限を読み取り専用アクセスに制限することもできます。 GitHubリポジトリの場合、これを行うには組織アカウントが必要です。 デモアプリケーションをデプロイするには、サーバー上に公開鍵を作成し、それをGitHubに登録するだけで、毎回クレデンシャルを入力せずにプロジェクトにアクセスできます。
新しいSSHキーを作成するには、次のコマンドを実行します。
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" 次に、GitHubにログインし、アカウント設定の~/.ssh/id_rsa.pubから公開鍵を追加します。
アプリのデプロイ
最後の手順は非常に簡単です。GitHubからアプリケーションコードを取得し、DockerComposeですべてのコンテナーを起動する必要があります。
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d 最初の実行では-d (コンテナーをデタッチモードで開始します)を省略して、ターミナルで各コンテナーの出力を確認し、考えられる問題を確認することをお勧めします。 もう1つのオプションは、後でdocker logsを使用して個々のコンテナーを検査することです。 すべてのコンテナがdocker ps.
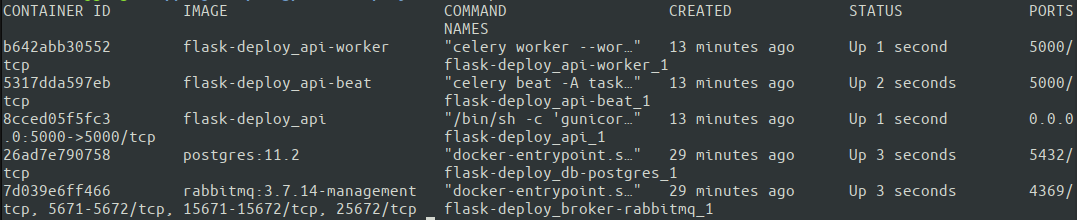
素晴らしい。 5つのコンテナすべてが稼働しています。 Docker Composeは、docker-compose.ymlで指定されたサービスに基づいて、割り当てられたコンテナー名を自動的に作成します。 次に、構成全体がどのように機能するかを最終的にテストします。 サーバーが正しいネットワーク設定を持っていることを確認するために、外部マシンからテストを実行するのが最善です。
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtそれでおしまい。 AWSインスタンスで実行されているアプリの最小限の、しかし完全に本番環境に対応した構成があります。 実際のアプリケーションの構築をすばやく開始し、よくある間違いを回避するのに役立つことを願っています。 完全なコードはGitHubリポジトリで入手できます。
結論
この記事では、Flaskアプリケーションを構造化、構成、パッケージ化、および本番環境にデプロイするためのベストプラクティスのいくつかについて説明しました。 これは非常に大きなトピックであり、1つのブログ投稿で完全にカバーすることは不可能です。 対処しなかった重要な質問のリストは次のとおりです。
この記事はカバーしていません:
- 継続的インテグレーションと継続的デプロイ
- 自動テスト
- ログ配布
- APIモニタリング
- アプリケーションを複数のサーバーにスケールアップする
- ソースコード内のクレデンシャルの保護
ただし、このブログの他の優れたリソースを使用して、その方法を学ぶことができます。 たとえば、ロギングについては、Pythonロギング:詳細なチュートリアルを参照してください。CI/ CDと自動テストの一般的な概要については、効果的な初期デプロイメントパイプラインを構築する方法を参照してください。 これらの実装は、読者の皆さんに演習として残しておきます。
読んでくれてありがとう!