
Zero to Hero: Receitas de produção de frascos
Publicados: 2022-03-11Como engenheiro de aprendizado de máquina e especialista em visão computacional, me vejo criando APIs e até aplicativos da Web com o Flask com uma frequência surpreendente. Neste post, quero compartilhar algumas dicas e receitas úteis para construir um aplicativo Flask completo e pronto para produção.
Abordaremos os seguintes tópicos:
- Gerenciamento de configurações. Qualquer aplicativo da vida real tem um ciclo de vida com estágios específicos – no mínimo, seria desenvolvimento, teste e implantação. Em cada estágio, o código do aplicativo deve funcionar em um ambiente ligeiramente diferente, o que requer um conjunto diferente de configurações, como strings de conexão de banco de dados, chaves de APIs externas e URLs.
- Aplicativo Flask auto-hospedado com Gunicorn. Embora o Flask tenha um servidor web embutido, como todos sabemos, ele não é adequado para produção e precisa ser colocado atrás de um servidor web real capaz de se comunicar com o Flask através de um protocolo WSGI. Uma escolha comum para isso é o Gunicorn—um servidor HTTP WSGI Python.
- Servindo arquivos estáticos e solicitação de proxy com Nginx. Apesar de ser um servidor web HTTP, o Gunicorn, por sua vez, é um servidor de aplicações não adequado para enfrentar a web. É por isso que precisamos do Nginx como proxy reverso e para servir arquivos estáticos. Caso precisemos escalar nosso aplicativo para vários servidores, o Nginx também cuidará do balanceamento de carga.
- Implantando um aplicativo dentro de contêineres do Docker em um servidor Linux dedicado. A implantação em contêiner tem sido uma parte essencial do design de software há muito tempo. Nosso aplicativo não é diferente e será empacotado perfeitamente em seu próprio contêiner (vários contêineres, na verdade).
- Configurando e implantando um banco de dados PostgreSQL para o aplicativo. A estrutura e as migrações do banco de dados serão gerenciadas pela Alambic com SQLAlchemy fornecendo mapeamento objeto-relacional.
- Configurando uma fila de tarefas de aipo para lidar com tarefas de longa duração. Todo aplicativo eventualmente exigirá isso para descarregar processos intensivos de tempo ou computação - seja envio de e-mail, manutenção automática de banco de dados ou processamento de imagens carregadas - de threads de servidor da Web em trabalhadores externos.
Criando o aplicativo Flask
Vamos começar criando um código de aplicativo e ativos. Observe que não abordarei a estrutura adequada do aplicativo Flask neste post. O aplicativo de demonstração consiste em um número mínimo de módulos e pacotes por uma questão de brevidade e clareza.
Primeiro, crie uma estrutura de diretórios e inicialize um repositório Git vazio.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtEm seguida, adicionaremos o código.
config/__init__.py
No módulo de configuração, definiremos nossa pequena estrutura de gerenciamento de configuração. A ideia é fazer com que o aplicativo se comporte de acordo com a configuração predefinida selecionada pela variável de ambiente APP_ENV , além de adicionar uma opção para substituir qualquer configuração por uma variável de ambiente específica, se necessário.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/settings.py
Este é um conjunto de classes de configuração, uma das quais é selecionada pela variável APP_ENV . Quando o aplicativo for executado, o código em __init__.py instanciará uma dessas classes substituindo os valores de campo por variáveis de ambiente específicas, se estiverem presentes. Usaremos um objeto de configuração final ao inicializar a configuração do Flask e do Celery posteriormente.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Truetasks/__init__.py
O pacote de tarefas contém o código de inicialização do Celery. O pacote Config, que já terá todas as configurações copiadas no nível do módulo na inicialização, é usado para atualizar o objeto de configuração Celery caso tenhamos algumas configurações específicas do Celery no futuro, por exemplo, tarefas agendadas e tempos limite de trabalho.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()tasks/celery_worker.py
Este módulo é necessário para iniciar e inicializar um trabalhador Celery, que será executado em um contêiner Docker separado. Ele inicializa o contexto do aplicativo Flask para ter acesso ao mesmo ambiente que o aplicativo. Se isso não for necessário, essas linhas podem ser removidas com segurança.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Em seguida, vem o pacote API, que define a API REST usando o pacote Flask-Restful. Nosso aplicativo é apenas uma demonstração e terá apenas dois endpoints:
-
/process_data– inicia uma operação longa fictícia em um trabalhador Celery e retorna o ID de uma nova tarefa. -
/tasks/<task_id>– Retorna o status de uma tarefa por ID de tarefa.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')models/__init__.py
Agora adicionaremos um modelo SQLAlchemy para o objeto User e um código de inicialização do mecanismo de banco de dados. O objeto User não será usado por nosso aplicativo de demonstração de maneira significativa, mas precisaremos dele para garantir que as migrações de banco de dados funcionem e a integração SQLAlchemy-Flask esteja configurada corretamente.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Observe como o UUID é gerado automaticamente como um ID de objeto por expressão padrão.
app.py
Por fim, vamos criar um arquivo principal do aplicativo Flask.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Aqui estamos:
- Configurando o log básico em um formato adequado com hora, nível e ID do processo
- Definindo a função de criação do aplicativo Flask com inicialização da API e “Hello, world!” página
- Definindo um ponto de entrada para executar o aplicativo durante o tempo de desenvolvimento
wsgi.py
Além disso, precisaremos de um módulo separado para executar o aplicativo Flask com Gunicorn. Terá apenas duas linhas:
from app import create_app app = create_app()O código do aplicativo está pronto. Nossa próxima etapa é criar uma configuração do Docker.
Construindo contêineres do Docker
Nosso aplicativo exigirá vários contêineres do Docker para ser executado:
- Contêiner de aplicativo para veicular páginas de modelo e expor endpoints de API. É uma boa ideia dividir essas duas funções na produção, mas não temos nenhuma página de modelo em nosso aplicativo de demonstração. O contêiner executará o servidor web Gunicorn que se comunicará com o Flask através do protocolo WSGI.
- Recipiente de trabalhador de aipo para executar tarefas longas. Este é o mesmo contêiner do aplicativo, mas com o comando de execução personalizado para iniciar o Celery, em vez do Gunicorn.
- Recipiente de batida de aipo - semelhante ao acima, mas para tarefas invocadas em uma programação regular, como remover contas de usuários que nunca confirmaram seus e-mails.
- Recipiente RabbitMQ. O aipo exige que um agente de mensagens se comunique entre os trabalhadores e o aplicativo e armazene os resultados das tarefas. RabbitMQ é uma escolha comum, mas você também pode usar Redis ou Kafka.
- Container de banco de dados com PostgreSQL.
Uma maneira natural de gerenciar facilmente vários contêineres é usar o Docker Compose. Mas primeiro, precisaremos criar um Dockerfile para construir uma imagem de contêiner para nosso aplicativo. Vamos colocá-lo no diretório do projeto.

FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoEste arquivo instrui o Docker a:
- Instale todas as dependências usando o Pipenv
- Adicionar uma pasta de aplicativo ao contêiner
- Expor a porta TCP 5000 ao host
- Defina o comando de inicialização padrão do contêiner para uma chamada do Gunicorn
Vamos discutir mais o que acontece na última linha. Ele roda o Gunicorn especificando a classe trabalhadora como gevent. Gevent é uma biblioteca de simultaneidade leve para multitarefa cooperativa. Ele oferece ganhos de desempenho consideráveis em cargas vinculadas de E/S, proporcionando melhor utilização da CPU em comparação com a multitarefa preemptiva do SO para threads. O parâmetro --workers é o número de processos de trabalho. É uma boa ideia defini-lo igual a um número de núcleos no servidor.
Assim que tivermos um Dockerfile para o contêiner do aplicativo, podemos criar um arquivo docker-compose.yml , que definirá todos os contêineres que o aplicativo precisará para ser executado.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationDefinimos os seguintes serviços:
-
broker-rabbitmq– Um contêiner do intermediário de mensagens RabbitMQ. As credenciais de conexão são definidas por variáveis de ambiente -
db-postgres– Um contêiner PostgreSQL e suas credenciais -
migration– Um contêiner de aplicativo que realizará a migração do banco de dados com o Flask-Migrate e sairá. Os contêineres de API dependem dele e serão executados posteriormente. -
api– O contêiner principal do aplicativo -
api-workereapi-beat– Contêineres que executam trabalhadores de aipo para tarefas recebidas da API e tarefas agendadas
Cada contêiner de aplicativo também receberá a variável APP_ENV do comando docker-compose up .
Assim que tivermos todos os ativos do aplicativo prontos, vamos colocá-los no GitHub, o que nos ajudará a implantar o código no servidor.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterConfigurando o Servidor
Nosso código está em um GitHub agora, e tudo o que resta é realizar a configuração inicial do servidor e implantar o aplicativo. No meu caso, o servidor é uma instância da AWS executando o AMI Linux. Para outros tipos de Linux, as instruções podem diferir ligeiramente. Também presumo que o servidor já tenha um endereço IP externo, o DNS esteja configurado com um registro A apontando para esse IP e os certificados SSL sejam emitidos para o domínio.
Dica de segurança: Não se esqueça de permitir as portas 80 e 443 para tráfego HTTP(S), porta 22 para SSH em seu console de hospedagem (ou usando iptables ) e fechar o acesso externo a todas as outras portas! Certifique-se de fazer o mesmo para o protocolo IPv6 !
Instalando dependências
Primeiro, precisaremos do Nginx e do Docker em execução no servidor, além do Git para extrair o código. Vamos fazer o login via SSH e usar um gerenciador de pacotes para instalá-los.
sudo yum install -y docker docker-compose nginx gitConfigurando o Nginx
O próximo passo é configurar o Nginx. O arquivo de configuração principal nginx.conf geralmente é bom como está. Ainda assim, certifique-se de verificar se ele atende às suas necessidades. Para nosso aplicativo, criaremos um novo arquivo de configuração em uma pasta conf.d A configuração de nível superior tem uma diretiva para incluir todos os arquivos .conf dela.
cd /etc/nginx/conf.d sudo vim flask-deploy.confAqui está um arquivo de configuração do site Flask para Nginx, baterias incluídas. Possui as seguintes características:
- SSL está configurado. Você deve ter certificados válidos para seu domínio, por exemplo, um certificado Let's Encrypt gratuito.
- As solicitações de
www.your-site.comsão redirecionadas parayour-site.com - As solicitações HTTP são redirecionadas para a porta HTTPS segura.
- O proxy reverso está configurado para passar solicitações para a porta local 5000.
- Arquivos estáticos são servidos pelo Nginx de uma pasta local.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } Depois de editar o arquivo, execute sudo nginx -s reload e veja se há algum erro.
Configurando credenciais do GitHub
É uma boa prática ter uma conta VCS de “implantação” separada para implantar o projeto e o sistema CI/CD. Assim você não corre o risco de expor as credenciais da sua própria conta. Para proteger ainda mais o repositório do projeto, você também pode limitar as permissões dessa conta para acesso somente leitura. Para um repositório do GitHub, você precisará de uma conta de organização para fazer isso. Para implantar nosso aplicativo de demonstração, basta criar uma chave pública no servidor e registrá-la no GitHub para obter acesso ao nosso projeto sem inserir credenciais todas as vezes.
Para criar uma nova chave SSH, execute:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Em seguida, faça login no GitHub e adicione sua chave pública de ~/.ssh/id_rsa.pub nas configurações da conta.
Como implantar um aplicativo
As etapas finais são bem diretas - precisamos obter o código do aplicativo do GitHub e iniciar todos os contêineres com o Docker Compose.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Pode ser uma boa ideia omitir -d (que inicia o contêiner no modo desanexado) para uma primeira execução para ver a saída de cada contêiner diretamente no terminal e verificar possíveis problemas. Outra opção é inspecionar cada contêiner individual com docker logs posteriormente. Vamos ver se todos os nossos containers estão rodando com o docker ps.
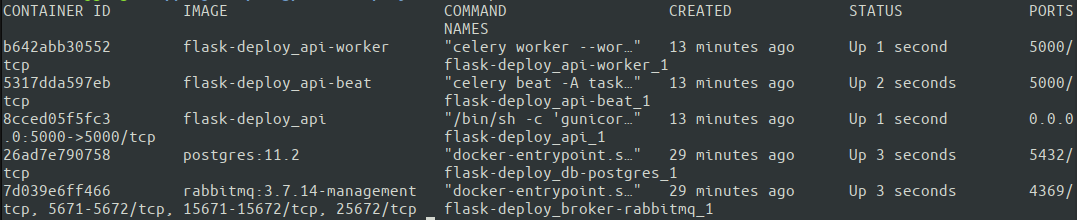
Excelente. Todos os cinco contêineres estão funcionando. Docker Compose nomes de contêiner atribuídos automaticamente com base no serviço especificado em docker-compose.yml. Agora é hora de finalmente testar como toda a configuração funciona! É melhor executar os testes em uma máquina externa para garantir que o servidor tenha as configurações de rede corretas.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtÉ isso. Temos uma configuração minimalista, mas totalmente pronta para produção, do nosso aplicativo em execução em uma instância da AWS. Espero que ajude você a começar a criar um aplicativo da vida real rapidamente e evitar alguns erros comuns! O código completo está disponível em um repositório GitHub.
Conclusão
Neste artigo, discutimos algumas das melhores práticas de estruturação, configuração, empacotamento e implantação de um aplicativo Flask para produção. Este é um tópico muito grande, impossível de cobrir completamente em uma única postagem no blog. Aqui está uma lista de questões importantes que não abordamos:
Este artigo não abrange:
- Integração contínua e implantação contínua
- Teste automático
- Envio de logs
- Monitoramento de API
- Escalando um aplicativo para vários servidores
- Proteção de credenciais no código-fonte
No entanto, você pode aprender como fazer isso usando alguns dos outros ótimos recursos deste blog. Por exemplo, para explorar o registro em log, consulte Python Logging: um tutorial detalhado ou, para obter uma visão geral sobre CI/CD e testes automatizados, consulte Como criar um pipeline de implantação inicial eficaz. Deixo a implementação destes como um exercício para você, leitor.
Obrigado por ler!