
Zero to Hero: Herstellungsrezepte für Flaschen
Veröffentlicht: 2022-03-11Als Machine-Learning-Ingenieur und Computer-Vision-Experte erfinde ich mich überraschend oft dabei, APIs und sogar Web-Apps mit Flask zu erstellen. In diesem Beitrag möchte ich einige Tipps und nützliche Rezepte zum Erstellen einer vollständigen produktionsbereiten Flask-Anwendung teilen.
Folgende Themen werden wir behandeln:
- Konfigurationsmanagement. Jede reale Anwendung hat einen Lebenszyklus mit bestimmten Phasen – zumindest wäre es Entwicklung, Test und Bereitstellung. In jeder Phase sollte der Anwendungscode in einer etwas anderen Umgebung funktionieren, was unterschiedliche Einstellungen erfordert, wie z. B. Datenbankverbindungszeichenfolgen, externe API-Schlüssel und URLs.
- Selbsthostende Flask-Anwendung mit Gunicorn. Obwohl Flask über einen integrierten Webserver verfügt, ist dieser, wie wir alle wissen, nicht für die Produktion geeignet und muss hinter einen echten Webserver gestellt werden, der über ein WSGI-Protokoll mit Flask kommunizieren kann. Eine häufige Wahl dafür ist Gunicorn – ein Python-WSGI-HTTP-Server.
- Bereitstellen statischer Dateien und Proxy-Anforderungen mit Nginx. Gunicorn ist zwar ein HTTP-Webserver, aber ein Anwendungsserver, der nicht für das Web geeignet ist. Deshalb brauchen wir Nginx als Reverse-Proxy und um statische Dateien bereitzustellen. Falls wir unsere Anwendung auf mehrere Server skalieren müssen, kümmert sich Nginx auch um den Lastausgleich.
- Bereitstellen einer App in Docker-Containern auf einem dedizierten Linux-Server. Die containerisierte Bereitstellung ist schon seit geraumer Zeit ein wesentlicher Bestandteil des Softwaredesigns. Unsere Anwendung ist nicht anders und wird ordentlich in einem eigenen Container verpackt (tatsächlich in mehreren Containern).
- Konfigurieren und Bereitstellen einer PostgreSQL-Datenbank für die Anwendung. Datenbankstruktur und Migrationen werden von Alembic verwaltet, wobei SQLAlchemy objektrelationales Mapping bereitstellt.
- Einrichten einer Sellerie-Aufgabenwarteschlange zur Bearbeitung lang andauernder Aufgaben. Jede Anwendung wird dies schließlich erfordern, um zeit- oder rechenintensive Prozesse – sei es das Versenden von E-Mails, die automatische Verwaltung von Datenbanken oder die Verarbeitung hochgeladener Bilder – von Webserver-Threads auf externe Mitarbeiter auszulagern.
Erstellen der Flask-App
Beginnen wir mit der Erstellung eines Anwendungscodes und von Assets. Bitte beachten Sie, dass ich in diesem Beitrag nicht auf die richtige Flask-Anwendungsstruktur eingehen werde. Die Demo-App besteht aus Gründen der Kürze und Klarheit aus einer minimalen Anzahl von Modulen und Paketen.
Erstellen Sie zunächst eine Verzeichnisstruktur und initialisieren Sie ein leeres Git-Repository.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtAls Nächstes fügen wir den Code hinzu.
config/__init__.py
Im Konfigurationsmodul definieren wir unser winziges Konfigurationsmanagement-Framework. Die Idee besteht darin, dass sich die App gemäß der von der Umgebungsvariablen APP_ENV ausgewählten Konfigurationsvoreinstellung verhält und bei Bedarf eine Option zum Überschreiben jeder Konfigurationseinstellung mit einer bestimmten Umgebungsvariablen hinzufügt.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/settings.py
Dies ist ein Satz von Konfigurationsklassen, von denen eine durch die Variable APP_ENV ausgewählt wird. Wenn die Anwendung ausgeführt wird, instanziiert der Code in __init__.py eine dieser Klassen und überschreibt die Feldwerte mit bestimmten Umgebungsvariablen, sofern vorhanden. Wir werden später ein letztes Konfigurationsobjekt verwenden, wenn wir die Flask- und Celery-Konfiguration initialisieren.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = TrueAufgaben/__init__.py
Das Aufgabenpaket enthält Celery-Initialisierungscode. Das Konfigurationspaket, das bereits bei der Initialisierung alle Einstellungen auf Modulebene kopiert hat, wird verwendet, um das Celery-Konfigurationsobjekt zu aktualisieren, falls wir in Zukunft einige Celery-spezifische Einstellungen haben werden – zum Beispiel geplante Aufgaben und Worker-Timeouts.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()task/celery_worker.py
Dieses Modul ist erforderlich, um einen Celery-Worker zu starten und zu initialisieren, der in einem separaten Docker-Container ausgeführt wird. Es initialisiert den Flask-Anwendungskontext, um Zugriff auf dieselbe Umgebung wie die Anwendung zu haben. Wenn dies nicht erforderlich ist, können diese Leitungen sicher entfernt werden.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Als nächstes folgt das API-Paket, das die REST-API mithilfe des Flask-Restful-Pakets definiert. Unsere App ist nur eine Demo und wird nur zwei Endpunkte haben:
-
/process_data– Startet eine Dummy-Long-Operation auf einem Celery-Worker und gibt die ID einer neuen Aufgabe zurück. -
/tasks/<task_id>– Gibt den Status einer Aufgabe nach Aufgaben-ID zurück.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')Modelle/__init__.py
Jetzt fügen wir ein SQLAlchemy-Modell für das User -Objekt und einen Datenbank-Engine-Initialisierungscode hinzu. Das User -Objekt wird von unserer Demo-App nicht sinnvoll verwendet, aber wir benötigen es, um sicherzustellen, dass Datenbankmigrationen funktionieren und die SQLAlchemy-Flask-Integration korrekt eingerichtet ist.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Beachten Sie, wie die UUID standardmäßig automatisch als Objekt-ID generiert wird.
app.py
Lassen Sie uns abschließend eine Flask-Hauptanwendungsdatei erstellen.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Hier sind wir:
- Konfigurieren der grundlegenden Protokollierung in einem geeigneten Format mit Zeit, Ebene und Prozess-ID
- Definieren der Flask-App-Erstellungsfunktion mit API-Initialisierung und „Hello, world!“ Seite
- Definieren eines Einstiegspunkts zum Ausführen der App während der Entwicklungszeit
wsgi.py
Außerdem benötigen wir ein separates Modul, um die Flask-Anwendung mit Gunicorn auszuführen. Es wird nur zwei Zeilen haben:
from app import create_app app = create_app()Der Anwendungscode ist fertig. Unser nächster Schritt besteht darin, eine Docker-Konfiguration zu erstellen.
Docker-Container bauen
Unsere Anwendung benötigt mehrere Docker-Container, um ausgeführt zu werden:
- Anwendungscontainer zum Bereitstellen von Vorlagenseiten und Verfügbarmachen von API-Endpunkten. Es ist eine gute Idee, diese beiden Funktionen in der Produktion aufzuteilen, aber wir haben keine Vorlagenseiten in unserer Demo-App. Auf dem Container wird der Gunicorn-Webserver ausgeführt, der über das WSGI-Protokoll mit Flask kommuniziert.
- Sellerie-Worker-Container zum Ausführen langer Aufgaben. Dies ist derselbe Anwendungscontainer, jedoch mit benutzerdefiniertem Ausführungsbefehl zum Starten von Celery anstelle von Gunicorn.
- Sellerie-Beat-Container – ähnlich wie oben, aber für Aufgaben, die regelmäßig aufgerufen werden, wie z. B. das Entfernen von Konten von Benutzern, die ihre E-Mail nie bestätigt haben.
- RabbitMQ-Container. Sellerie benötigt einen Nachrichtenbroker, um zwischen Mitarbeitern und der App zu kommunizieren und Aufgabenergebnisse zu speichern. RabbitMQ ist eine gängige Wahl, aber Sie können auch Redis oder Kafka verwenden.
- Datenbankcontainer mit PostgreSQL.
Eine natürliche Möglichkeit, mehrere Container einfach zu verwalten, ist die Verwendung von Docker Compose. Aber zuerst müssen wir ein Dockerfile erstellen, um ein Container-Image für unsere Anwendung zu erstellen. Legen wir es in das Projektverzeichnis.
FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoDiese Datei weist Docker an:

- Installieren Sie alle Abhängigkeiten mit Pipenv
- Fügen Sie dem Container einen Anwendungsordner hinzu
- Geben Sie TCP-Port 5000 für den Host frei
- Legen Sie den standardmäßigen Startbefehl des Containers auf einen Gunicorn-Aufruf fest
Lassen Sie uns mehr darüber diskutieren, was in der letzten Zeile passiert. Es führt Gunicorn aus und gibt die Arbeiterklasse als gevent an. Gevent ist eine leichtgewichtige Nebenläufigkeitsbibliothek für kooperatives Multitasking. Es bietet erhebliche Leistungssteigerungen bei E/A-gebundenen Lasten und eine bessere CPU-Auslastung im Vergleich zum präemptiven Multitasking des Betriebssystems für Threads. Der Parameter --workers ist die Anzahl der Worker-Prozesse. Es ist eine gute Idee, es gleich einer Anzahl von Kernen auf dem Server festzulegen.
Sobald wir eine Docker-Datei für den Anwendungscontainer haben, können wir eine docker docker-compose.yml Datei erstellen, die alle Container definiert, die die Anwendung zum Ausführen benötigt.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationFolgende Leistungen haben wir definiert:
-
broker-rabbitmq– Ein RabbitMQ-Message-Broker-Container. Verbindungsanmeldeinformationen werden durch Umgebungsvariablen definiert -
db-postgres– Ein PostgreSQL-Container und seine Anmeldeinformationen -
migration– Ein App-Container, der die Datenbankmigration mit Flask-Migrate durchführt und beendet. API-Container hängen davon ab und werden danach ausgeführt. -
api– Der Hauptanwendungscontainer -
api-workerundapi-beat– Container, in denen Sellerie-Worker für Aufgaben ausgeführt werden, die von der API empfangen werden, und geplante Aufgaben
Jeder App-Container erhält außerdem die APP_ENV -Variable vom docker docker-compose up Befehl.
Sobald wir alle Anwendungsressourcen bereit haben, stellen wir sie auf GitHub, was uns bei der Bereitstellung des Codes auf dem Server helfen wird.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterKonfigurieren des Servers
Unser Code befindet sich jetzt auf einem GitHub, und es bleibt nur noch, die anfängliche Serverkonfiguration durchzuführen und die Anwendung bereitzustellen. In meinem Fall ist der Server eine AWS-Instanz, auf der AMI Linux ausgeführt wird. Für andere Linux-Varianten können die Anweisungen leicht abweichen. Ich gehe auch davon aus, dass der Server bereits eine externe IP-Adresse hat, DNS mit einem A-Eintrag konfiguriert ist, der auf diese IP zeigt, und SSL-Zertifikate für die Domain ausgestellt sind.
Sicherheitstipp: Vergessen Sie nicht, die Ports 80 und 443 für HTTP(S)-Verkehr, Port 22 für SSH in Ihrer Hosting-Konsole (oder mit iptables ) zuzulassen und den externen Zugriff auf alle anderen Ports zu schließen! Machen Sie dasselbe für das IPv6 -Protokoll!
Abhängigkeiten installieren
Zuerst benötigen wir Nginx und Docker, die auf dem Server laufen, plus Git, um den Code abzurufen. Melden wir uns über SSH an und verwenden einen Paketmanager, um sie zu installieren.
sudo yum install -y docker docker-compose nginx gitKonfigurieren von Nginx
Der nächste Schritt ist die Konfiguration von Nginx. Die Hauptkonfigurationsdatei nginx.conf ist oft so gut, wie sie ist. Prüfen Sie dennoch, ob es Ihren Anforderungen entspricht. Für unsere App erstellen wir eine neue Konfigurationsdatei in einem conf.d Ordner. Die Top-Level-Konfiguration hat eine Anweisung, alle .conf Dateien von ihr einzuschließen.
cd /etc/nginx/conf.d sudo vim flask-deploy.confHier ist eine Flask-Site-Konfigurationsdatei für Nginx, inklusive Batterien. Es hat die folgenden Funktionen:
- SSL ist konfiguriert. Sie sollten gültige Zertifikate für Ihre Domain haben, z. B. ein kostenloses Zertifikat von Let's Encrypt.
-
www.your-site.comAnfragen werden anyour-site.comumgeleitet - HTTP-Anforderungen werden an einen sicheren HTTPS-Port umgeleitet.
- Der Reverse-Proxy ist so konfiguriert, dass Anfragen an den lokalen Port 5000 weitergeleitet werden.
- Statische Dateien werden von Nginx aus einem lokalen Ordner bereitgestellt.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } Führen Sie nach dem Bearbeiten der Datei sudo nginx -s reload aus und prüfen Sie, ob Fehler vorliegen.
GitHub-Anmeldeinformationen einrichten
Es empfiehlt sich, ein separates VCS-Bereitstellungskonto für die Bereitstellung des Projekts und des CI/CD-Systems zu haben. Auf diese Weise gehen Sie kein Risiko ein, indem Sie die Anmeldeinformationen Ihres eigenen Kontos preisgeben. Um das Projekt-Repository weiter zu schützen, können Sie die Berechtigungen eines solchen Kontos auch auf schreibgeschützten Zugriff beschränken. Für ein GitHub-Repository benötigen Sie dazu ein Organisationskonto. Um unsere Demoanwendung bereitzustellen, erstellen wir einfach einen öffentlichen Schlüssel auf dem Server und registrieren ihn auf GitHub, um Zugriff auf unser Projekt zu erhalten, ohne jedes Mal Anmeldeinformationen eingeben zu müssen.
Um einen neuen SSH-Schlüssel zu erstellen, führen Sie Folgendes aus:
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Melden Sie sich dann bei GitHub an und fügen Sie Ihren öffentlichen Schlüssel von ~/.ssh/id_rsa.pub in den Kontoeinstellungen hinzu.
Bereitstellen einer App
Die letzten Schritte sind ziemlich einfach – wir müssen Anwendungscode von GitHub abrufen und alle Container mit Docker Compose starten.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Es könnte eine gute Idee sein, -d (das den Container im getrennten Modus startet) für einen ersten Lauf wegzulassen, um die Ausgabe jedes Containers direkt im Terminal zu sehen und auf mögliche Probleme zu prüfen. Eine weitere Möglichkeit besteht darin, jeden einzelnen Container anschließend mit docker logs zu inspizieren. Mal sehen, ob alle unsere Container mit docker ps.
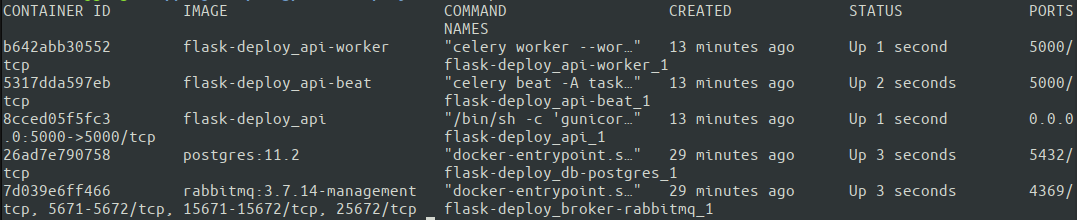
Toll. Alle fünf Container sind in Betrieb. Containernamen wurden von Docker Compose automatisch basierend auf dem in docker-compose.yml angegebenen Dienst zugewiesen. Jetzt ist es an der Zeit, endlich zu testen, wie die gesamte Konfiguration funktioniert! Am besten führen Sie die Tests von einem externen Computer aus aus, um sicherzustellen, dass der Server über die richtigen Netzwerkeinstellungen verfügt.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtDas ist es. Wir haben eine minimalistische, aber vollständig produktionsbereite Konfiguration unserer App, die auf einer AWS-Instanz ausgeführt wird. Ich hoffe, es hilft Ihnen, schnell mit dem Erstellen einer realen Anwendung zu beginnen und einige häufige Fehler zu vermeiden! Der vollständige Code ist in einem GitHub-Repository verfügbar.
Fazit
In diesem Artikel haben wir einige der Best Practices zum Strukturieren, Konfigurieren, Packen und Bereitstellen einer Flask-Anwendung für die Produktion besprochen. Dies ist ein sehr großes Thema, das unmöglich in einem einzigen Blogbeitrag vollständig behandelt werden kann. Hier ist eine Liste wichtiger Fragen, die wir nicht angesprochen haben:
Dieser Artikel behandelt nicht:
- Kontinuierliche Integration und kontinuierliche Bereitstellung
- Automatisches Testen
- Protokollversand
- API-Überwachung
- Hochskalieren einer Anwendung auf mehrere Server
- Schutz von Anmeldeinformationen im Quellcode
Sie können jedoch lernen, wie das geht, indem Sie einige der anderen großartigen Ressourcen in diesem Blog verwenden. Informationen zur Protokollierung finden Sie beispielsweise unter Python Logging: An In-Depth Tutorial, oder für einen allgemeinen Überblick über CI/CD und automatisierte Tests siehe How to Build an Effective Initial Deployment Pipeline. Die Umsetzung überlasse ich Ihnen, dem Leser, als Übung.
Danke fürs Lesen!