
Zero to Hero: Recettes de production de flacons
Publié: 2022-03-11En tant qu'ingénieur en apprentissage automatique et expert en vision par ordinateur, je me retrouve à créer des API et même des applications Web avec Flask étonnamment souvent. Dans cet article, je souhaite partager quelques astuces et recettes utiles pour créer une application Flask complète et prête pour la production.
Nous aborderons les sujets suivants :
- Gestion de la configuration. Toute application réelle a un cycle de vie avec des étapes spécifiques - à tout le moins, ce serait le développement, les tests et le déploiement. À chaque étape, le code de l'application doit fonctionner dans un environnement légèrement différent, ce qui nécessite un ensemble de paramètres différent, comme les chaînes de connexion à la base de données, les clés d'API externes et les URL.
- Application Flask auto-hébergée avec Gunicorn. Bien que Flask dispose d'un serveur Web intégré, comme nous le savons tous, il n'est pas adapté à la production et doit être placé derrière un véritable serveur Web capable de communiquer avec Flask via un protocole WSGI. Un choix courant pour cela est Gunicorn, un serveur HTTP Python WSGI.
- Servir des fichiers statiques et des demandes de proxy avec Nginx. Tout en étant un serveur Web HTTP, Gunicorn, à son tour, est un serveur d'applications qui n'est pas adapté pour faire face au Web. C'est pourquoi nous avons besoin de Nginx comme proxy inverse et pour servir les fichiers statiques. Au cas où nous aurions besoin d'étendre notre application à plusieurs serveurs, Nginx se chargera également de l'équilibrage de charge.
- Déploiement d'une application dans des conteneurs Docker sur un serveur Linux dédié. Le déploiement conteneurisé est depuis longtemps un élément essentiel de la conception de logiciels. Notre application n'est pas différente et sera soigneusement emballée dans son propre conteneur (plusieurs conteneurs, en fait).
- Configuration et déploiement d'une base de données PostgreSQL pour l'application. La structure et les migrations de la base de données seront gérées par Alembic avec SQLAlchemy fournissant un mappage objet-relationnel.
- Configuration d'une file d'attente de tâches Celery pour gérer les tâches de longue durée. Chaque application en aura éventuellement besoin pour décharger les processus gourmands en temps ou en calculs - qu'il s'agisse de l'envoi de courrier, de la maintenance automatique de la base de données ou du traitement des images téléchargées - des threads du serveur Web sur les travailleurs externes.
Création de l'application Flask
Commençons par créer un code d'application et des ressources. Veuillez noter que je n'aborderai pas la structure appropriée de l'application Flask dans cet article. L'application de démonstration se compose d'un nombre minimal de modules et de packages par souci de brièveté et de clarté.
Tout d'abord, créez une structure de répertoires et initialisez un référentiel Git vide.
mkdir flask-deploy cd flask-deploy # init GIT repo git init # create folder structure mkdir static tasks models config # install required packages with pipenv, this will create a Pipfile pipenv install flask flask-restful flask-sqlalchemy flask-migrate celery # create test static asset echo "Hello World!" > static/hello-world.txtEnsuite, nous ajouterons le code.
config/__init__.py
Dans le module de configuration, nous définirons notre petit cadre de gestion de configuration. L'idée est de faire en sorte que l'application se comporte en fonction du préréglage de configuration sélectionné par la variable d'environnement APP_ENV , et d'ajouter une option pour remplacer tout paramètre de configuration par une variable d'environnement spécifique si nécessaire.
import os import sys import config.settings # create settings object corresponding to specified env APP_ENV = os.environ.get('APP_ENV', 'Dev') _current = getattr(sys.modules['config.settings'], '{0}Config'.format(APP_ENV))() # copy attributes to the module for convenience for atr in [f for f in dir(_current) if not '__' in f]: # environment can override anything val = os.environ.get(atr, getattr(_current, atr)) setattr(sys.modules[__name__], atr, val) def as_dict(): res = {} for atr in [f for f in dir(config) if not '__' in f]: val = getattr(config, atr) res[atr] = val return resconfig/settings.py
Il s'agit d'un ensemble de classes de configuration, dont l'une est sélectionnée par la variable APP_ENV . Lorsque l'application s'exécute, le code dans __init__.py instancie l'une de ces classes en remplaçant les valeurs de champ par des variables d'environnement spécifiques, si elles sont présentes. Nous utiliserons un objet de configuration final lors de l'initialisation de la configuration de Flask et Celery ultérieurement.
class BaseConfig(): API_PREFIX = '/api' TESTING = False DEBUG = False class DevConfig(BaseConfig): FLASK_ENV = 'development' DEBUG = True SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class ProductionConfig(BaseConfig): FLASK_ENV = 'production' SQLALCHEMY_DATABASE_URI = 'postgresql://db_user:db_password@db-postgres:5432/flask-deploy' CELERY_BROKER = 'pyamqp://rabbit_user:rabbit_password@broker-rabbitmq//' CELERY_RESULT_BACKEND = 'rpc://rabbit_user:rabbit_password@broker-rabbitmq//' class TestConfig(BaseConfig): FLASK_ENV = 'development' TESTING = True DEBUG = True # make celery execute tasks synchronously in the same process CELERY_ALWAYS_EAGER = Truetâches/__init__.py
Le package de tâches contient le code d'initialisation Celery. Le package de configuration, qui aura déjà tous les paramètres copiés au niveau du module lors de l'initialisation, est utilisé pour mettre à jour l'objet de configuration Celery au cas où nous aurions des paramètres spécifiques à Celery à l'avenir, par exemple, les tâches planifiées et les délais d'attente des travailleurs.
from celery import Celery import config def make_celery(): celery = Celery(__name__, broker=config.CELERY_BROKER) celery.conf.update(config.as_dict()) return celery celery = make_celery()tâches/celery_worker.py
Ce module est requis pour démarrer et initialiser un worker Celery, qui s'exécutera dans un conteneur Docker séparé. Il initialise le contexte de l'application Flask pour avoir accès au même environnement que l'application. Si ce n'est pas nécessaire, ces lignes peuvent être supprimées en toute sécurité.
from app import create_app app = create_app() app.app_context().push() from tasks import celeryapi/__init__.py
Vient ensuite le package API, qui définit l'API REST à l'aide du package Flask-Restful. Notre application n'est qu'une démo et n'aura que deux points de terminaison :
-
/process_data- Démarre une longue opération factice sur un travailleur Celery et renvoie l'ID d'une nouvelle tâche. -
/tasks/<task_id>– Renvoie l'état d'une tâche par ID de tâche.
import time from flask import jsonify from flask_restful import Api, Resource from tasks import celery import config api = Api(prefix=config.API_PREFIX) class TaskStatusAPI(Resource): def get(self, task_id): task = celery.AsyncResult(task_id) return jsonify(task.result) class DataProcessingAPI(Resource): def post(self): task = process_data.delay() return {'task_id': task.id}, 200 @celery.task() def process_data(): time.sleep(60) # data processing endpoint api.add_resource(DataProcessingAPI, '/process_data') # task status endpoint api.add_resource(TaskStatusAPI, '/tasks/<string:task_id>')modèles/__init__.py
Nous allons maintenant ajouter un modèle SQLAlchemy pour l'objet User et un code d'initialisation du moteur de base de données. L'objet User ne sera pas utilisé par notre application de démonstration de manière significative, mais nous en aurons besoin pour nous assurer que les migrations de base de données fonctionnent et que l'intégration SQLAlchemy-Flask est correctement configurée.
import uuid from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() class User(db.Model): id = db.Column(db.String(), primary_key=True, default=lambda: str(uuid.uuid4())) username = db.Column(db.String()) email = db.Column(db.String(), unique=True)Notez comment UUID est généré automatiquement en tant qu'ID d'objet par expression par défaut.
app.py
Enfin, créons un fichier d'application Flask principal.
from flask import Flask logging.basicConfig(level=logging.DEBUG, format='[%(asctime)s]: {} %(levelname)s %(message)s'.format(os.getpid()), datefmt='%Y-%m-%d %H:%M:%S', handlers=[logging.StreamHandler()]) logger = logging.getLogger() def create_app(): logger.info(f'Starting app in {config.APP_ENV} environment') app = Flask(__name__) app.config.from_object('config') api.init_app(app) # initialize SQLAlchemy db.init_app(app) # define hello world page @app.route('/') def hello_world(): return 'Hello, World!' return app if __name__ == "__main__": app = create_app() app.run(host='0.0.0.0', debug=True)</td> </tr> <tr> <td>Nous voilà:
- Configuration de la journalisation de base dans un format approprié avec l'heure, le niveau et l'ID de processus
- Définition de la fonction de création d'application Flask avec initialisation de l'API et "Hello, world!" page
- Définir un point d'entrée pour exécuter l'application pendant le temps de développement
wsgi.py
De plus, nous aurons besoin d'un module séparé pour exécuter l'application Flask avec Gunicorn. Il n'aura que deux lignes :
from app import create_app app = create_app()Le code d'application est prêt. Notre prochaine étape consiste à créer une configuration Docker.
Construire des conteneurs Docker
Notre application nécessitera plusieurs conteneurs Docker pour s'exécuter :
- Conteneur d'application pour servir des pages basées sur des modèles et exposer les points de terminaison d'API. C'est une bonne idée de séparer ces deux fonctions sur la production, mais nous n'avons pas de pages modèles dans notre application de démonstration. Le conteneur exécutera le serveur Web Gunicorn qui communiquera avec Flask via le protocole WSGI.
- Conteneur de travail de céleri pour exécuter de longues tâches. Il s'agit du même conteneur d'application, mais avec une commande d'exécution personnalisée pour lancer Celery, au lieu de Gunicorn.
- Conteneur de battement de céleri - similaire à ci-dessus, mais pour les tâches appelées selon un calendrier régulier, telles que la suppression des comptes d'utilisateurs qui n'ont jamais confirmé leur adresse e-mail.
- Conteneur RabbitMQ. Celery nécessite un courtier de messages pour communiquer entre les travailleurs et l'application, et stocker les résultats des tâches. RabbitMQ est un choix courant, mais vous pouvez également utiliser Redis ou Kafka.
- Conteneur de base de données avec PostgreSQL.
Un moyen naturel de gérer facilement plusieurs conteneurs consiste à utiliser Docker Compose. Mais d'abord, nous devrons créer un Dockerfile pour construire une image de conteneur pour notre application. Mettons-le dans le répertoire du projet.

FROM python:3.7.2 RUN pip install pipenv ADD . /flask-deploy WORKDIR /flask-deploy RUN pipenv install --system --skip-lock RUN pip install gunicorn[gevent] EXPOSE 5000 CMD gunicorn --worker-class gevent --workers 8 --bind 0.0.0.0:5000 wsgi:app --max-requests 10000 --timeout 5 --keep-alive 5 --log-level infoCe fichier demande à Docker de :
- Installer toutes les dépendances à l'aide de Pipenv
- Ajouter un dossier d'application au conteneur
- Exposez le port TCP 5000 à l'hôte
- Définissez la commande de démarrage par défaut du conteneur sur un appel Gunicorn
Discutons davantage de ce qui se passe dans la dernière ligne. Il exécute Gunicorn en spécifiant la classe de travail comme gevent. Gevent est une bibliothèque de concurrence légère pour le multitâche coopératif. Il offre des gains de performances considérables sur les charges liées aux E/S, offrant une meilleure utilisation du processeur par rapport au multitâche préemptif du système d'exploitation pour les threads. Le paramètre --workers est le nombre de processus de travail. C'est une bonne idée de le définir égal à un nombre de cœurs sur le serveur.
Une fois que nous avons un Dockerfile pour le conteneur d'application, nous pouvons créer un fichier docker-compose.yml , qui définira tous les conteneurs dont l'application aura besoin pour s'exécuter.
version: '3' services: broker-rabbitmq: image: "rabbitmq:3.7.14-management" environment: - RABBITMQ_DEFAULT_USER=rabbit_user - RABBITMQ_DEFAULT_PASS=rabbit_password db-postgres: image: "postgres:11.2" environment: - POSTGRES_USER=db_user - POSTGRES_PASSWORD=db_password migration: build: . environment: - APP_ENV=${APP_ENV} command: flask db upgrade depends_on: - db-postgres api: build: . ports: - "5000:5000" environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-worker: build: . command: celery worker --workdir=. -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migration api-beat: build: . command: celery beat -A tasks.celery --loglevel=info environment: - APP_ENV=${APP_ENV} depends_on: - broker-rabbitmq - db-postgres - migrationNous avons défini les services suivants :
-
broker-rabbitmq– Un conteneur de courtier de messages RabbitMQ. Les identifiants de connexion sont définis par des variables d'environnement -
db-postgres– Un conteneur PostgreSQL et ses identifiants -
migration- Un conteneur d'application qui effectuera la migration de la base de données avec Flask-Migrate et quittera. Les conteneurs d'API en dépendent et s'exécuteront ensuite. -
api- Le conteneur d'application principal -
api-workeretapi-beat– Conteneurs exécutant des workers Celery pour les tâches reçues de l'API et les tâches planifiées
Chaque conteneur d'application recevra également la variable APP_ENV de la commande docker-compose up .
Une fois que nous avons tous les actifs de l'application prêts, mettons-les sur GitHub, ce qui nous aidera à déployer le code sur le serveur.
git add * git commit -a -m 'Initial commit' git remote add origin [email protected]:your-name/flask-deploy.git git push -u origin masterConfiguration du serveur
Notre code est maintenant sur un GitHub, et il ne reste plus qu'à effectuer la configuration initiale du serveur et à déployer l'application. Dans mon cas, le serveur est une instance AWS exécutant AMI Linux. Pour les autres versions de Linux, les instructions peuvent différer légèrement. Je suppose également que le serveur a déjà une adresse IP externe, DNS est configuré avec un enregistrement A pointant vers cette adresse IP et des certificats SSL sont émis pour le domaine.
Conseil de sécurité : n'oubliez pas d'autoriser les ports 80 et 443 pour le trafic HTTP(S), le port 22 pour le SSH dans votre console d'hébergement (ou en utilisant iptables ) et fermez l'accès externe à tous les autres ports ! Assurez-vous de faire de même pour le protocole IPv6 !
Installation des dépendances
Tout d'abord, nous aurons besoin de Nginx et de Docker en cours d'exécution sur le serveur, ainsi que de Git pour extraire le code. Connectez-vous via SSH et utilisez un gestionnaire de packages pour les installer.
sudo yum install -y docker docker-compose nginx gitConfiguration de Nginx
L'étape suivante consiste à configurer Nginx. Le fichier de configuration principal nginx.conf est souvent bon tel quel. Néanmoins, assurez-vous de vérifier si cela convient à vos besoins. Pour notre application, nous allons créer un nouveau fichier de configuration dans un dossier conf.d La configuration de niveau supérieur a une directive pour inclure tous les fichiers .conf qu'elle contient.
cd /etc/nginx/conf.d sudo vim flask-deploy.confVoici un fichier de configuration du site Flask pour Nginx, piles incluses. Il a les caractéristiques suivantes :
- SSL est configuré. Vous devez avoir des certificats valides pour votre domaine, par exemple, un certificat Let's Encrypt gratuit.
- Les requêtes
your-site.comsont redirigées verswww.your-site.com - Les requêtes HTTP sont redirigées vers un port HTTPS sécurisé.
- Le proxy inverse est configuré pour transmettre les demandes au port local 5000.
- Les fichiers statiques sont servis par Nginx à partir d'un dossier local.
server { listen 80; listen 443; server_name www.your-site.com; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # redirect to non-www domain return 301 https://your-site.com$request_uri; } # HTTP to HTTPS redirection server { listen 80; server_name your-site.com; return 301 https://your-site.com$request_uri; } server { listen 443 ssl; # check your certificate path! ssl_certificate /etc/nginx/ssl/your-site.com/fullchain.crt; ssl_certificate_key /etc/nginx/ssl/your-site.com/server.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; # affects the size of files user can upload with HTTP POST client_max_body_size 10M; server_name your-site.com; location / { include /etc/nginx/mime.types; root /home/ec2-user/flask-deploy/static; # if static file not found - pass request to Flask try_files $uri @flask; } location @flask { add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; proxy_read_timeout 10; proxy_send_timeout 10; send_timeout 60; resolver_timeout 120; client_body_timeout 120; # set headers to pass request info to Flask proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_redirect off; proxy_pass http://127.0.0.1:5000$uri; } } Après avoir modifié le fichier, exécutez sudo nginx -s reload et voyez s'il y a des erreurs.
Configuration des informations d'identification GitHub
Il est recommandé d'avoir un compte VCS de « déploiement » séparé pour déployer le projet et le système CI/CD. De cette façon, vous ne risquez pas d'exposer les informations d'identification de votre propre compte. Pour protéger davantage le référentiel du projet, vous pouvez également limiter les autorisations de ce compte à un accès en lecture seule. Pour un référentiel GitHub, vous aurez besoin d'un compte d'organisation pour le faire. Pour déployer notre application de démonstration, nous allons simplement créer une clé publique sur le serveur et l'enregistrer sur GitHub pour avoir accès à notre projet sans entrer d'informations d'identification à chaque fois.
Pour créer une nouvelle clé SSH, exécutez :
cd ~/.ssh ssh-keygen -b 2048 -t rsa -f id_rsa.pub -q -N "" -C "deploy" Connectez-vous ensuite sur GitHub et ajoutez votre clé publique depuis ~/.ssh/id_rsa.pub dans les paramètres du compte.
Déploiement d'une application
Les étapes finales sont assez simples : nous devons obtenir le code d'application de GitHub et démarrer tous les conteneurs avec Docker Compose.
cd ~ git clone https://github.com/your-name/flask-deploy.git git checkout master APP_ENV=Production docker-compose up -d Il peut être judicieux d'omettre -d (qui démarre le conteneur en mode détaché) pour une première exécution afin de voir la sortie de chaque conteneur directement dans le terminal et de rechercher d'éventuels problèmes. Une autre option consiste à inspecter chaque conteneur individuel avec les docker logs par la suite. Voyons si tous nos conteneurs fonctionnent avec docker ps.
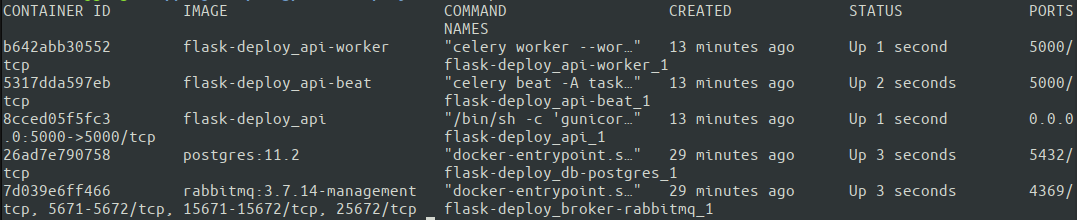
Génial. Les cinq conteneurs sont opérationnels. Docker Compose attribue automatiquement des noms de conteneurs en fonction du service spécifié dans docker-compose.yml. Il est maintenant temps de tester enfin le fonctionnement de l'ensemble de la configuration ! Il est préférable d'exécuter les tests à partir d'une machine externe pour s'assurer que le serveur dispose des paramètres réseau corrects.
# test HTTP protocol, you should get a 301 response curl your-site.com # HTTPS request should return our Hello World message curl https://your-site.com # and nginx should correctly send test static file: curl https://your-site.com/hello-world.txtC'est ça. Nous avons une configuration minimaliste, mais entièrement prête pour la production de notre application exécutée sur une instance AWS. J'espère que cela vous aidera à commencer à créer rapidement une application réelle et à éviter certaines erreurs courantes ! Le code complet est disponible sur un dépôt GitHub.
Conclusion
Dans cet article, nous avons abordé certaines des meilleures pratiques de structuration, de configuration, de conditionnement et de déploiement d'une application Flask en production. C'est un sujet très vaste, impossible à couvrir entièrement dans un seul article de blog. Voici une liste de questions importantes auxquelles nous n'avons pas répondu :
Cet article ne couvre pas :
- Intégration continue et déploiement continu
- Test automatique
- Expédition de journaux
- Surveillance des API
- Mise à l'échelle d'une application sur plusieurs serveurs
- Protection des identifiants dans le code source
Cependant, vous pouvez apprendre à le faire en utilisant certaines des autres excellentes ressources de ce blog. Par exemple, pour explorer la journalisation, consultez Python Logging : An In-Depth Tutorial, ou pour un aperçu général sur CI/CD et les tests automatisés, consultez Comment créer un pipeline de déploiement initial efficace. Je laisse la mise en œuvre de ceux-ci comme un exercice pour vous, le lecteur.
Merci d'avoir lu!