
Мониторинг Kubernetes с помощью Prometheus [с вариантами использования и мониторингом]
Опубликовано: 2020-09-23Оглавление
Где и почему используется Прометей?
Prometheus Kubernetes — это инструмент мониторинга, который можно развернуть в кластерах AWS, Azure или GCloud Kubernetes. Он считается важным инструментом в современной инфраструктуре. Современный DevOps становится все сложнее обрабатывать вручную и, следовательно, требует большей автоматизации, поэтому обычно у вас есть несколько серверов, на которых выполняются контейнерные приложения.
В этой инфраструктуре, где все объекты взаимосвязаны, выполняются сотни различных процессов, поэтому поддерживать такую настройку для бесперебойной работы и без простоев приложений очень сложно. Представьте себе такую сложную инфраструктуру с множеством серверов, распределенных по многим местам, и вы не имеете представления о том, что происходит на аппаратном уровне или на уровне приложений, например об ошибках, ответах и задержках.
Оборудование может быть отключено или перегружено, поэтому в такой сложной инфраструктуре могут не хватать ресурсов, но когда у вас развернуто множество сервисов и приложений, может произойти больше ошибок. Любой из них может дать сбой и привести к сбою других сервисов, иметь так много движущихся частей, и вдруг приложение станет недоступным для пользователей. Вы должны быстро определить, что именно из этих сотен различных вещей пошло не так, что может быть трудным и трудоемким при отладке системы вручную.
Некоторые варианты использования Prometheus Monitoring
Например, предположим, что одному конкретному серверу не хватило памяти, и он запустил работающий контейнер, который отвечал за обеспечение синхронизации базы данных между двумя горшками базы данных в кластере Kubernetes. Это, в свою очередь, привело к сбою этих двух горшков базы данных. Эта база данных использовалась службой проверки подлинности, которая также перестала работать, поскольку база данных недоступна.
Приложение, которое зависело от этой службы аутентификации, больше не могло аутентифицировать пользователей в пользовательском интерфейсе, но с точки зрения пользователя все, что вы видите, — это ошибка в пользовательском интерфейсе. Если у вас нет представления о том, что происходит внутри кластера, вы не видите красную линию цепочки событий, показанную здесь; вы просто видите ошибку. Итак, теперь вы начинаете работать в обратном направлении, чтобы найти причину и исправить ее. Но что сделает процесс поиска проблемы более эффективным? Вы можете использовать инструмент, который постоянно отслеживает, работают ли службы, и выдает предупреждения, как только одна из служб выходит из строя.
Вы точно знаете, что произошло, или, что еще лучше, он выявляет проблемы еще до их возникновения и предупреждает системных администраторов, ответственных за эту инфраструктуру, чтобы предотвратить эту проблему. Например, в рассматриваемом случае будет регулярно проверяться статус использования памяти на каждом сервере. Когда на одном из серверов она превышает, например, 70% в течение часа или продолжает расти, она уведомляет о риске скорого исчерпания памяти на этом сервере.

Или давайте рассмотрим другой сценарий, когда вы перестаете видеть журналы для своего приложения, потому что эластичный поиск не принимает новые журналы, так как на сервере закончилось место на диске или эластичный поиск достиг предела хранилища, выделенного для него. Инструмент мониторинга будет постоянно проверять пространство для хранения и сравнивать его с эластичным поиском, потребляющим пространство для хранения. Он увидит риск и уведомит сопровождающего о возможной проблеме с хранилищем.
Читайте: Вопросы интервью Kubernetes
Вы можете указать инструменту мониторинга, в какой критической точке должно срабатывать оповещение. Если у вас есть критическое приложение, в котором абсолютно возможна потеря данных журнала, вы можете быть очень строгим и принять меры, как только будет достигнуто пятьдесят или шестьдесят процентов емкости. Добавление дополнительного места для хранения займет много времени, потому что это бюрократический процесс в вашей организации, где вам нужно одобрение какого-то ИТ-отдела и нескольких других людей.

Вы также хотите получить уведомление о возможной проблеме с хранилищем раньше, чтобы у вас было больше времени для ее устранения. Или третий сценарий, когда приложение внезапно становится слишком медленным, потому что одна служба выходит из строя и начинает отправлять сотни сообщений об ошибках в цикле по сети, что создает высокий сетевой трафик и замедляет работу других служб, чтобы иметь инструмент, обнаруживающий такие всплески в сети. .
Узнайте: Openshift против Kubernetes: разница между Openshift и Kubernetes
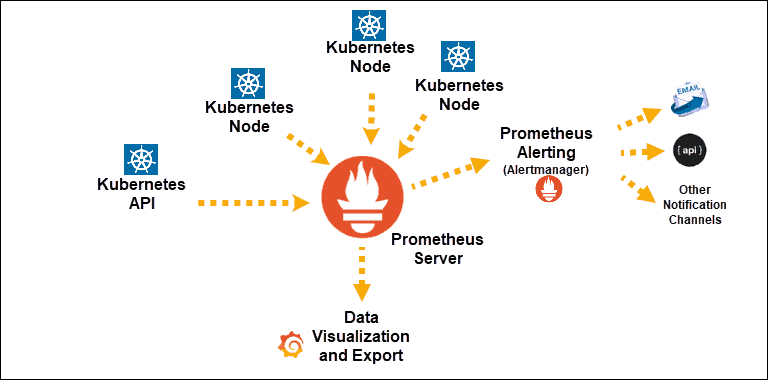
Источник
Открытия Kubernetes Service, раскрытые Prometheus
Основной компонент: сервер Prometheus
Архитектура Прометея
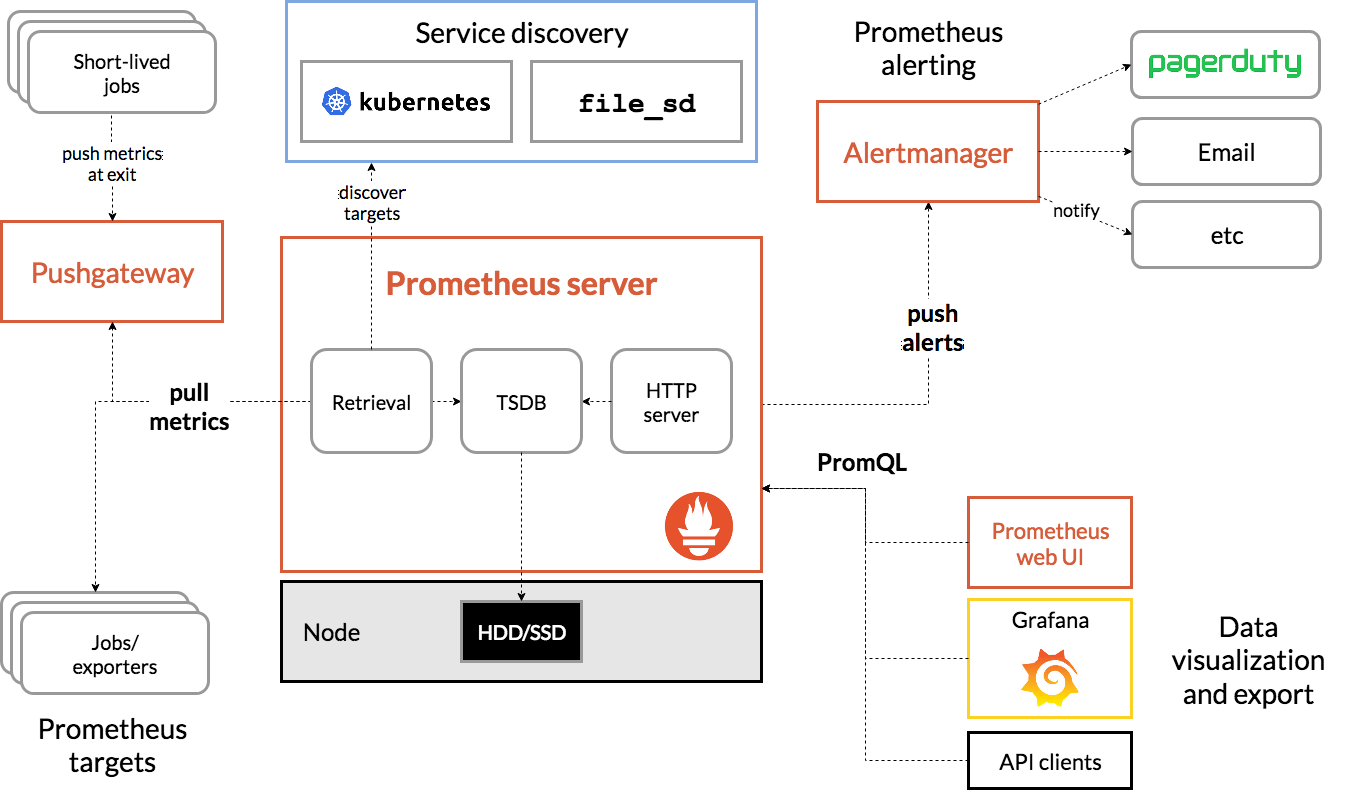
Источник
Архитектура Prometheus Kubernetes
Одной из важных характеристик Prometheus Kubernetes является то, что он разработан таким образом, чтобы быть надежным даже в случае сбоя других систем. Вы можете диагностировать проблемы и устранять их. Следовательно, каждый сервер Prometheus автономен, то есть не зависит от сетевого хранилища или других удаленных служб.
Он предназначен для работы, когда другие части инфраструктуры не работают, и вам не нужно настраивать обширную инфраструктуру для его использования. Однако у него также есть недостаток, заключающийся в том, что Prometheus сложно масштабировать. Поэтому, когда у вас есть сотни серверов, вам может понадобиться несколько серверов Prometheus, которые объединяют все эти данные метрик.
Конфигурирование и масштабирование примитивов таким образом может быть очень сложным из-за этих характеристик. Таким образом, хотя использование одного узла менее сложно, и вы можете очень легко начать работу, это ограничивает количество метрик, которые может отслеживать Prometheus. Чтобы обойти это, вы либо увеличиваете мощность сервера Prometheus, чтобы он мог хранить больше данных метрик, либо ограничиваете количество метрик, которые Prometheus собирает из приложений, чтобы ограничить его только релевантными.
Вы можете расширить свои знания по таким темам, пройдя курсы по облачным вычислениям на таких платформах, как upGrad, Udemy, Coursera и т. д., поскольку этот инструмент мониторинга можно развернуть в облаке. Специально для upGrad курсы разработаны одним из авторитетных учебных заведений нашей страны IIIT-B. Это даст вам практический опыт и более широкий аспект знаний.
Проверьте: Kubernetes против. Docker: основные отличия, которые вы должны знать
Заключение
Kubernetes упрощает развертывание, масштабирование и управление контейнерными приложениями и микросервисами. Это помогает поддерживать работу администрирования, но для распознавания и решения скрытых проблем, таких как медленное выполнение, вам нужна способность накапливать и представлять всю информацию о базовых приложениях и выполнении по вашему состоянию.
Если не обращаться к непрерывным данным вместе с релевантной информацией, почти невозможно соответствовать вашим измерениям состояния, поэтому вы тоже можете быстрее решать проблемы.
Если вы хотите изучить и освоить Kubernetes, DevOps и многое другое, ознакомьтесь с дипломом PG IIIT-B и upGrad по программе разработки программного обеспечения Full Stack.