
Kubernetes-Überwachung mit Prometheus [mit Anwendungsfällen und Überwachung]
Veröffentlicht: 2020-09-23Inhaltsverzeichnis
Wo und warum wird Prometheus verwendet?
Prometheus Kubernetes ist ein Überwachungstool, das auf AWS-, Azure- oder GCloud-Kubernetes-Clustern bereitgestellt werden kann. Es gilt als unverzichtbares Werkzeug in der modernen Infrastruktur. Modernes DevOps wird immer komplexer in der manuellen Handhabung und erfordert daher mehr Automatisierung, sodass Sie in der Regel mehrere Server haben, auf denen containerisierte Anwendungen ausgeführt werden.
Auf dieser Infrastruktur, in der alle Einheiten miteinander verbunden sind, laufen Hunderte verschiedener Prozesse. Daher ist es sehr schwierig, ein solches Setup so zu halten, dass es reibungslos und ohne Anwendungsausfallzeiten läuft. Stellen Sie sich vor, Sie hätten eine so komplizierte Infrastruktur mit vielen Servern, die über viele Standorte verteilt sind, und Sie hätten keinen Einblick in das, was auf Hardware- oder Anwendungsebene passiert, wie Fehler, Antworten und Latenz.
Ausgefallene oder überlastete Hardware kann dazu führen, dass in solch einer komplexen Infrastruktur die Ressourcen ausgehen, aber es können noch mehr Dinge schief gehen, wenn Sie unzählige Dienste und Anwendungen bereitstellen. Jeder von ihnen kann abstürzen und den Ausfall anderer Dienste verursachen, so viele bewegliche Teile haben, und plötzlich ist die Anwendung für Benutzer nicht mehr verfügbar. Sie müssen schnell identifizieren, was genau von diesen hundert verschiedenen Dingen schief gelaufen ist, was schwierig und zeitaufwändig sein kann, wenn Sie das System manuell debuggen.
Einige Anwendungsfälle für die Verwendung von Prometheus Monitoring
Angenommen, ein bestimmter Server hatte keinen Arbeitsspeicher mehr und startete einen laufenden Container, der für die Datenbanksynchronisierung zwischen zwei Datenbank-Pots in einem Kubernetes-Cluster verantwortlich war. Das wiederum führte dazu, dass diese beiden Datenbanktöpfe scheiterten. Diese Datenbank wurde von einem Authentifizierungsdienst verwendet, der ebenfalls nicht mehr funktioniert, weil die Datenbank nicht verfügbar ist.
Die Anwendung, die von diesem Authentifizierungsdienst abhängig war, konnte Benutzer in der Benutzeroberfläche nicht mehr authentifizieren, aber aus Benutzerperspektive sehen Sie nur einen Fehler in der Benutzeroberfläche. Wenn Sie keinen Einblick in das haben, was innerhalb des Clusters vor sich geht, sehen Sie diese rote Linie der Ereigniskette nicht, wie sie hier angezeigt wird; Sie sehen nur den Fehler. Also fangen Sie jetzt an, von dort aus rückwärts zu arbeiten, um die Ursache zu finden und zu beheben. Aber was macht diesen Suchproblemprozess effizienter? Sie könnten ein Tool verwenden, das kontinuierlich überwacht, ob Dienste ausgeführt werden, und Warnmeldungen ausgibt, sobald ein Dienst abstürzt.
Sie wissen genau, was passiert ist, oder noch besser, es identifiziert Probleme, bevor sie überhaupt auftreten, und alarmiert die für diese Infrastruktur verantwortlichen Systemadministratoren, um dieses Problem zu verhindern. In diesem Fall würde es beispielsweise regelmäßig den Status der Speichernutzung auf jedem Server überprüfen. Wenn es auf einem der Server beispielsweise über eine Stunde lang über 70 % steigt oder weiter zunimmt, weist es auf das Risiko hin, dass der Speicher auf diesem Server bald erschöpft sein könnte.

Oder betrachten wir ein anderes Szenario, in dem Sie keine Protokolle mehr für Ihre Anwendung sehen, weil die elastische Suche keine neuen Protokolle akzeptiert, da auf dem Server kein Speicherplatz mehr vorhanden ist oder die elastische Suche die ihr zugewiesene Speichergrenze erreicht hat. Das Überwachungstool würde den Speicherplatz kontinuierlich überprüfen und mit dem elastischen Suchverbrauch des Speicherplatzes vergleichen. Es erkennt das Risiko und benachrichtigt den Betreuer über das mögliche Speicherproblem.
Lesen Sie: Kubernetes-Interviewfragen
Sie können dem Überwachungstool mitteilen, an welchem kritischen Punkt die Warnung ausgelöst werden soll. Wenn Sie eine kritische Anwendung haben, bei der absolut keine Protokolldaten verloren gehen können, können Sie sehr streng sein und Maßnahmen ergreifen, sobald fünfzig oder sechzig Prozent der Kapazität erreicht sind. Das Hinzufügen von mehr Speicherplatz wird lange dauern, da es sich um einen bürokratischen Prozess in Ihrem Unternehmen handelt, bei dem Sie die Genehmigung einer IT-Abteilung und mehrerer anderer Personen benötigen.

Sie möchten auch früher über das mögliche Speicherproblem benachrichtigt werden, damit Sie mehr Zeit haben, es zu beheben. Oder ein drittes Szenario, in dem die Anwendung plötzlich zu langsam wird, weil ein Dienst ausfällt und beginnt, Hunderte von Fehlermeldungen in einer Schleife über das Netzwerk zu senden, was zu hohem Netzwerkverkehr führt und andere Dienste verlangsamt, um ein Tool zu haben, das solche Spitzen in einem Netzwerk erkennt .
Lernen: Openshift vs. Kubernetes: Unterschied zwischen Openshift und Kubernetes
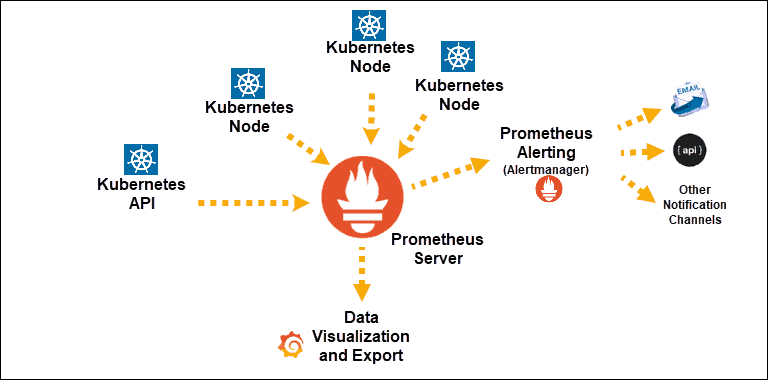
Quelle
Kubernetes Service-Entdeckungen, die Prometheus offengelegt wurden
Hauptkomponente: Prometheus-Server
Prometheus-Architektur
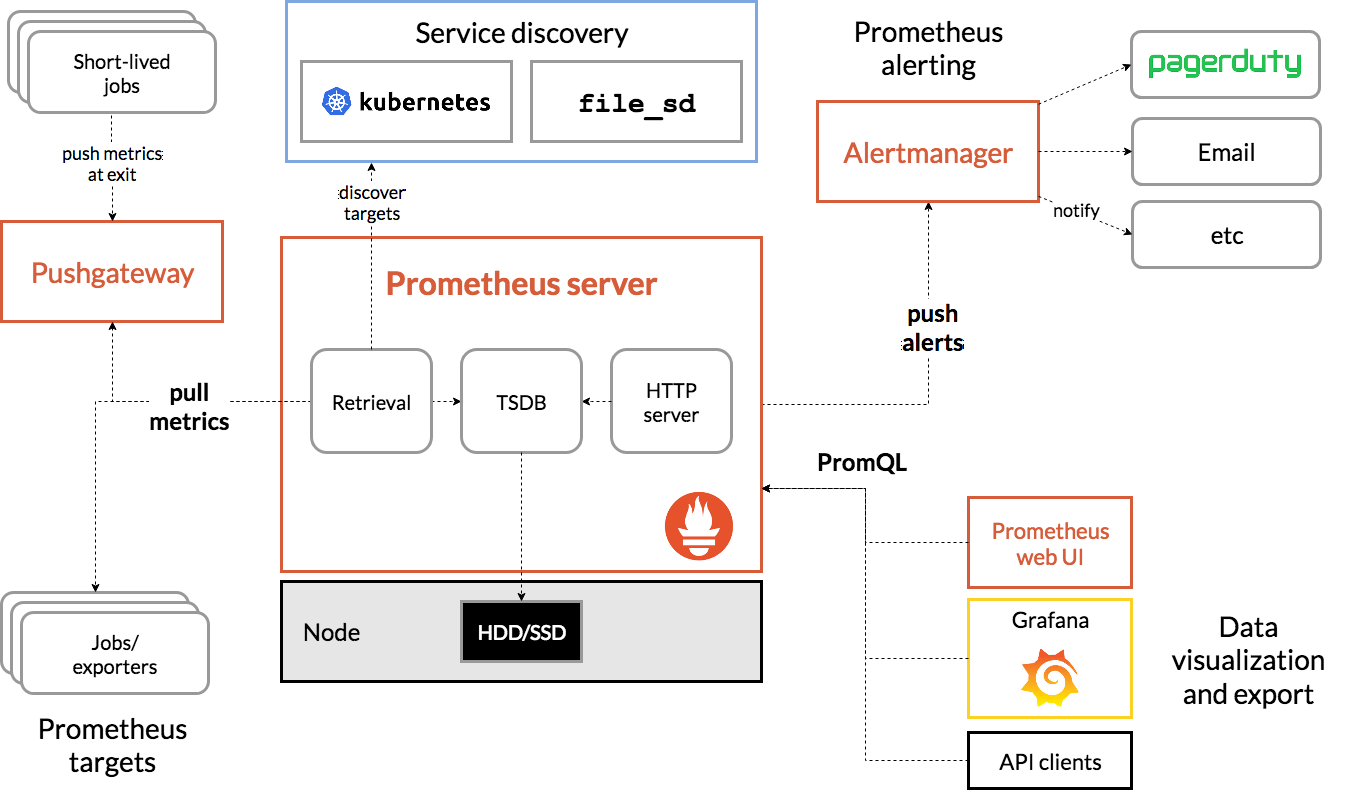
Quelle
Die Architektur von Prometheus Kubernetes
Eines der wichtigen Merkmale von Prometheus Kubernetes ist, dass es so konzipiert ist, dass es auch dann zuverlässig ist, wenn andere Systeme ausfallen. Sie können die Probleme diagnostizieren und beheben. Daher ist jeder Prometheus-Server in sich abgeschlossen, was bedeutet, dass er nicht von Netzwerkspeicher oder anderen Remote-Diensten abhängig ist.
Es soll funktionieren, wenn andere Teile der Infrastruktur defekt sind, und Sie müssen keine umfangreiche Infrastruktur einrichten, um es zu verwenden. Allerdings hat es auch den Nachteil, dass Prometheus schwer skalierbar sein kann. Wenn Sie also Hunderte von Servern haben, möchten Sie möglicherweise mehrere Prometheus-Server haben, die all diese Metrikdaten aggregieren.
Aufgrund dieser Eigenschaften kann es sehr schwierig sein, Grundelemente auf diese Weise zu konfigurieren und zu skalieren. Während die Verwendung eines einzelnen Knotens weniger komplex ist und Sie sehr einfach loslegen können, begrenzt dies die Anzahl der Metriken, die Prometheus überwachen kann. Um dies zu umgehen, erhöhen Sie entweder die Kapazität des Prometheus-Servers, sodass er mehr Metrikdaten speichern kann, oder begrenzen Sie die Anzahl der Metriken, die Prometheus von den Anwendungen erfasst, um sie auf nur die relevanten zu beschränken.
Sie können Ihr Wissen zu solchen Themen erweitern, indem Sie Cloud-Computing-Kurse auf Plattformen wie upGrad, Udemy, Coursera usw. absolvieren, da dieses Überwachungstool in der Cloud bereitgestellt werden kann. Insbesondere bei upGrad werden die Kurse von einer der renommiertesten Institutionen unseres Landes IIIT-B konzipiert. Dadurch erhalten Sie praktische Erfahrungen und einen breiteren Wissensaspekt.
Schauen Sie sich an: Kubernetes vs. Docker: Hauptunterschiede, die Sie kennen sollten
Fazit
Kubernetes vereinfacht die Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen und Microservices. Dies hilft dabei, die Verwaltung am Laufen zu halten, aber um versteckte Probleme wie eine langsame Ausführung zu erkennen und zu lösen, müssen Sie die Fähigkeit haben, grundlegende Anwendungs- und Ausführungsinformationen über Ihren Zustand zu sammeln und sich vorzustellen.
Der Verzicht auf kontinuierliche Daten neben relevanten Informationen macht es fast schwierig, Ihren Zustandsmessungen zu entsprechen, sodass auch Sie Probleme schneller angehen können.
Wenn Sie Kubernetes, DevOps und mehr lernen und beherrschen möchten, sehen Sie sich das PG Diploma in Full Stack Software Development Program von IIIT-B & upGrad an.