
Prometheusを使用したKubernetesモニタリング[ユースケースとモニタリングを使用]
公開: 2020-09-23目次
Prometheusはどこで、なぜ使用されますか?
Prometheus Kubernetesは、AWS、Azure、またはGCloudKubernetesクラスターにデプロイできるモニタリングツールです。 これは、最新のインフラストラクチャに不可欠なツールと見なされています。 最新のDevOpsは手動で処理するのがより複雑になり、したがってより多くの自動化が必要になるため、通常、コンテナー化されたアプリケーションを実行する複数のサーバーがあります。
すべてのエンティティが相互接続されているインフラストラクチャで実行されている数百の異なるプロセスがあるため、アプリケーションのダウンタイムなしでスムーズに実行されるようにそのようなセットアップを維持することは非常に困難です。 サーバーの負荷が多くの場所に分散しているこのような複雑なインフラストラクチャがあると想像してください。エラー、応答、遅延など、ハードウェアレベルまたはアプリケーションレベルで何が起こっているのかについての洞察がありません。
ハードウェアのダウンまたは過負荷は、このような複雑なインフラストラクチャのリソースを使い果たしている可能性がありますが、大量のサービスとアプリケーションを展開していると、さらに多くの問題が発生する可能性があります。 それらのいずれかがクラッシュして他のサービスの障害を引き起こし、非常に多くの可動部分があり、突然アプリケーションがユーザーに利用できなくなる可能性があります。 これらの100の異なるもののうち、何がうまくいかなかったかをすばやく特定する必要があります。これは、システムを手動でデバッグする場合、困難で時間がかかる可能性があります。
PrometheusMonitoringを使用するためのいくつかのユースケース
たとえば、ある特定のサーバーがメモリを使い果たし、Kubernetesクラスター内の2つのデータベースポット間でデータベース同期を提供する役割を果たしている実行中のコンテナーを起動したとします。 その結果、これら2つのデータベースポットが失敗しました。 そのデータベースは、データベースが利用できないために機能を停止した認証サービスによって使用されました。
その認証サービスに依存していたアプリケーションは、UIでユーザーを認証できなくなりましたが、ユーザーの観点から見ると、UIのエラーだけが表示されます。 クラスター内で何が起こっているかについての洞察がない場合、ここに表示されている一連のイベントの赤い線は表示されません。 エラーが表示されるだけです。 そこで、そこから逆方向に作業を開始して、原因を見つけて修正します。 しかし、何がこの検索問題プロセスをより効率的にするのでしょうか? サービスが実行されているかどうかを継続的に監視し、1つのサービスがクラッシュするとすぐにアラートがポップアップするツールを使用できます。
何が起こったのかを正確に把握しているだけでなく、問題が発生する前に問題を特定し、そのインフラストラクチャを担当するシステム管理者に警告して、その問題を防止します。 たとえば、このケースでは、各サーバーのメモリ使用状況を定期的にチェックします。 サーバーの1つで、たとえば1時間以上にわたって70%を急上昇したり、増加し続けたりすると、そのサーバーのメモリがすぐになくなる可能性があるというリスクについて通知します。

または、サーバーのディスク容量が不足したか、Elastic Searchが割り当てられたストレージ制限に達したために、Elastic Searchが新しいログを受け入れないために、アプリケーションのログの表示を停止する別のシナリオを考えてみましょう。 監視ツールは、ストレージスペースを継続的にチェックし、ストレージスペースの弾力的な検索消費と比較します。 リスクを確認し、ストレージの問題の可能性をメンテナに通知します。
読む: Kubernetesのインタビューの質問
アラートをトリガーする必要があるときに、その重要なポイントが何であるかを監視ツールに伝えることができます。 ログデータが完全に失われる可能性のある重要なアプリケーションがある場合は、非常に厳格で、容量が50%または60%に達したらすぐに対策を講じることができます。 ストレージスペースの追加は、組織内の官僚的なプロセスであり、IT部門や他の何人かの人々の承認が必要なため、長い時間がかかります。

また、ストレージの問題の可能性について早期に通知して、修正する時間を増やす必要があります。 または、1つのサービスが故障し、ネットワーク全体でループで数百のエラーメッセージの送信を開始したためにアプリケーションが突然遅くなり、ネットワークトラフィックが多くなり、他のサービスの速度が低下して、ネットワーク内のこのようなスパイクを検出するツールが作成される3番目のシナリオ。
学習: OpenshiftとKubernetes:OpenshiftとKubernetesの違い
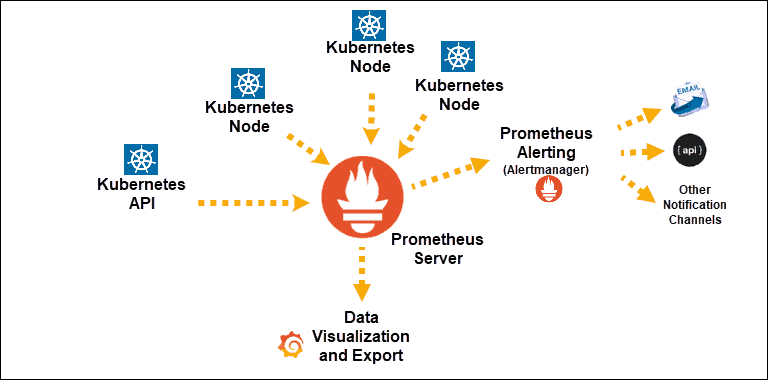
ソース
Prometheusに公開されたKubernetesサービスの検出
主要コンポーネント:Prometheusサーバー
プロメテウスアーキテクチャ
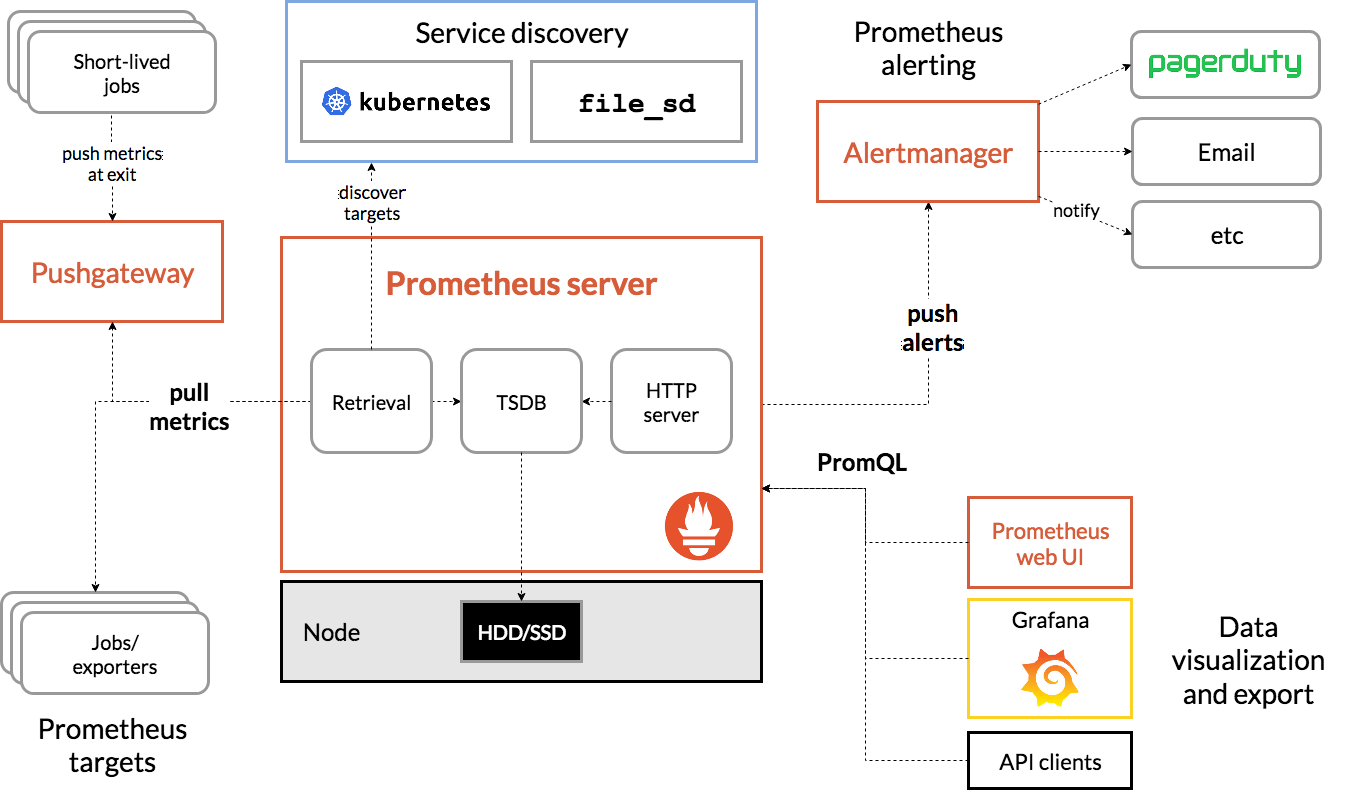
ソース
PrometheusKubernetesのアーキテクチャ
Prometheus Kubernetesの重要な特徴の1つは、他のシステムが停止した場合でも信頼できるように設計されていることです。 問題を診断して修正することができます。 したがって、各Prometheusサーバーは自己完結型であり、ネットワークストレージやその他のリモートサービスに依存しません。
これは、インフラストラクチャの他の部分が壊れたときに機能することを目的としており、それを使用するために大規模なインフラストラクチャをセットアップする必要はありません。 ただし、Prometheusのスケーリングが難しいという欠点もあります。 したがって、数百台のサーバーがある場合、これらすべてのメトリックデータを集約する複数のPrometheusサーバーが必要になる場合があります。
これらの特性のため、この方法でプリミティブを構成およびスケーリングすることは非常に難しい場合があります。 したがって、単一のノードを使用することはそれほど複雑ではなく、非常に簡単に開始できますが、Prometheusが監視できるメトリックの数が制限されます。 これを回避するには、Prometheusサーバーの容量を増やして、より多くのメトリックデータを保存できるようにするか、Prometheusがアプリケーションから収集するメトリックの数を制限して関連するものだけに制限します。
この監視ツールはクラウドにデプロイできるため、upGrad、Udemy、Courseraなどのプラットフォームでクラウドコンピューティングコースを受講することで、このようなトピックに関する知識を向上させることができます。 特にupGradの場合、コースは我が国IIIT-Bの評判の高い教育機関の1つによって設計されています。 これにより、実践的な経験と幅広い知識の側面が得られます。
チェックアウト: Kubernetes Vs. Docker:知っておくべき主な違い
結論
Kubernetesは、コンテナ化されたアプリケーションとマイクロサービスのデプロイ、スケーリング、管理を簡素化します。 これは、管理を継続するのに役立ちますが、実行速度の低下などの隠れた問題を認識して解決するには、条件全体から上から下への基盤アプリケーションと実行情報を蓄積して想像する能力が必要です。
関連情報とともに継続的なデータに近づかないと、状態の測定値に対応することがほとんど困難になるため、あなたもより迅速に問題に取り組むことができます。
Kubernetes、DevOpsなどを学び、習得したい場合は、フルスタックソフトウェア開発プログラムでIIIT-BとupGradのPGディプロマをチェックしてください。