
Monitoramento do Kubernetes com o Prometheus [com casos de uso e monitoramento]
Publicados: 2020-09-23Índice
Onde e por que o Prometheus é usado?
O Prometheus Kubernetes é uma ferramenta de monitoramento que pode ser implantada em clusters AWS, Azure ou GCloud Kubernetes. É considerado como uma ferramenta essencial na infraestrutura moderna. O DevOps moderno está se tornando mais complexo de manusear manualmente e, portanto, precisa de mais automação, então você normalmente tem vários servidores que executam aplicativos em contêiner.
Existem centenas de processos diferentes em execução nessa infraestrutura em que todas as entidades estão interconectadas, portanto, manter essa configuração para funcionar sem problemas e sem paralisações de aplicativos é muito desafiador. Imagine ter uma infraestrutura tão complicada com muitos servidores distribuídos em vários locais e você não tem nenhuma visão do que está acontecendo no nível do hardware ou no nível do aplicativo, como erros, resposta e latência.
Hardware inativo ou sobrecarregado pode estar ficando sem recursos em uma infraestrutura tão complexa, mas mais coisas podem dar errado quando você tem muitos serviços e aplicativos implantados. Qualquer um deles pode travar e causar falhas em outros serviços, ter tantas peças móveis e, de repente, o aplicativo fica indisponível para os usuários. Você deve identificar rapidamente o que exatamente dessas centenas de coisas deu errado, o que pode ser difícil e demorado ao depurar o sistema manualmente.
Alguns casos de uso para usar o Prometheus Monitoring
Por exemplo, digamos que um servidor específico ficou sem memória e iniciou um contêiner em execução que era responsável por fornecer sincronização de banco de dados entre dois potes de banco de dados em um cluster Kubernetes. Isso, por sua vez, causou a falha desses dois potes de banco de dados. Esse banco de dados foi usado por um serviço de autenticação que também parou de funcionar porque o banco de dados não está disponível.
O aplicativo que dependia desse serviço de autenticação não pôde mais autenticar usuários na interface do usuário, mas da perspectiva do usuário, tudo o que você vê é um erro na interface do usuário. Quando você não tem uma visão do que está acontecendo dentro do cluster, você não vê a linha vermelha da cadeia de eventos exibida aqui; você acabou de ver o erro. Então agora você começa a trabalhar para trás a partir daí para encontrar a causa e corrigi-la. Mas o que tornará esse processo de problema de busca mais eficiente? Você pode usar uma ferramenta que monitore continuamente se os serviços estão em execução e alertas surgindo assim que um serviço falha.
Você sabe exatamente o que aconteceu, ou melhor ainda, ele identifica problemas antes mesmo que eles ocorram e alerta os administradores do sistema responsáveis por essa infraestrutura para evitar esse problema. Por exemplo, neste caso discutido, ele verificaria regularmente o status do uso de memória em cada servidor. Quando em um dos servidores, ele atinge um pico, por exemplo, 70% por mais de uma hora ou continua aumentando, ele notifica sobre o risco de que a memória nesse servidor acabe em breve.

Ou vamos considerar outro cenário em que você para de ver os logs do seu aplicativo porque a pesquisa elástica não aceita novos logs porque o servidor ficou sem espaço em disco ou a pesquisa elástica atingiu o limite de armazenamento alocado para ela. A ferramenta de monitoramento verificaria o espaço de armazenamento continuamente e o compararia com o consumo elástico de pesquisa do espaço de armazenamento. Ele verá o risco e notificará o mantenedor sobre o possível problema de armazenamento.
Leia: Perguntas da entrevista do Kubernetes
Você pode dizer à ferramenta de monitoramento qual é o ponto crítico quando o alerta deve ser acionado. Se você tiver um aplicativo crítico que absolutamente pode ter qualquer perda de dados de log, você pode ser muito rigoroso e tomar medidas assim que cinquenta ou sessenta por cento da capacidade for atingida. Adicionar mais espaço de armazenamento levará muito tempo porque é um processo burocrático em sua organização, onde você precisa da aprovação de algum departamento de TI e várias outras pessoas.

Você também deseja ser notificado com antecedência sobre o possível problema de armazenamento para ter mais tempo para corrigi-lo. Ou um terceiro cenário em que o aplicativo de repente se torna muito lento porque um serviço quebra e começa a enviar centenas de mensagens de erro em um loop pela rede, o que cria alto tráfego de rede e desacelera outros serviços para ter uma ferramenta que detecte esses picos em uma rede .
Aprenda: Openshift vs Kubernetes: diferença entre Openshift e Kubernetes
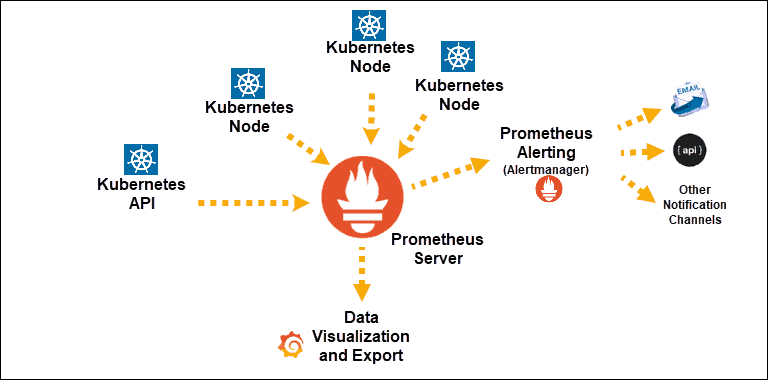
Fonte
Descobertas do serviço Kubernetes expostas ao Prometheus
Componente principal: Servidor Prometheus
Arquitetura Prometheus
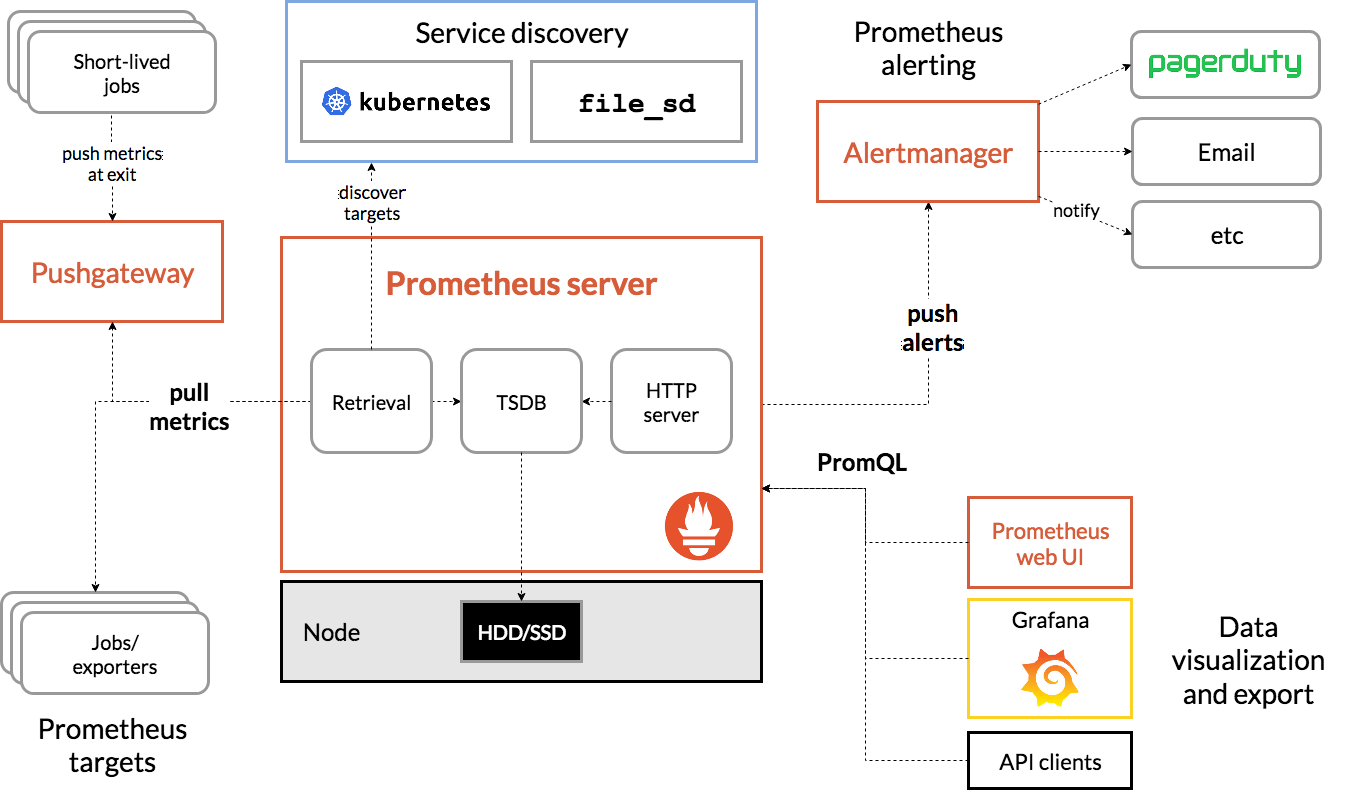
Fonte
A arquitetura do Prometheus Kubernetes
Uma das características importantes do Prometheus Kubernetes é que ele foi projetado para ser confiável mesmo quando outros sistemas têm uma interrupção. Você pode diagnosticar os problemas e corrigi-los. Portanto, cada servidor Prometheus é independente, o que significa que não depende de armazenamento de rede ou outros serviços remotos.
Ele deve funcionar quando outras partes da infraestrutura estão quebradas e você não precisa configurar uma infraestrutura extensa para usá-lo. No entanto, também tem a desvantagem de que o Prometheus pode ser difícil de escalar. Portanto, quando você tem centenas de servidores, pode querer ter vários servidores Prometheus que agregam todos esses dados de métricas.
Configurar e dimensionar primitivas dessa maneira pode ser muito difícil devido a essas características. Portanto, embora o uso de um único nó seja menos complexo e você possa começar com muita facilidade, ele limita o número de métricas que o Prometheus pode monitorar. Para contornar isso, você aumenta a capacidade do servidor Prometheus para que ele possa armazenar mais dados de métricas ou limita o número de métricas que o Prometheus coleta dos aplicativos para mantê-lo reduzido apenas aos relevantes.
Você pode aprimorar seu conhecimento sobre esses tópicos fazendo cursos de computação em nuvem em plataformas como upGrad, Udemy, Coursera, etc., pois essa ferramenta de monitoramento pode ser implantada na nuvem. Especialmente com upGrad, os cursos são projetados por uma das instituições de maior renome do nosso país IIIT-B. Isso lhe dará experiência prática e um aspecto de conhecimento mais amplo.
Confira: Kubernetes vs. Docker: principais diferenças que você deve conhecer
Conclusão
O Kubernetes simplifica a implantação, o dimensionamento e o gerenciamento de aplicativos e microsserviços em contêineres. Isso ajuda a manter as administrações em andamento, mas para reconhecer e resolver problemas ocultos, como uma execução lenta, você precisa da capacidade de acumular e imaginar informações de execução e aplicativos de base de cima para baixo de sua condição.
Não abordar dados contínuos, juntamente com informações relevantes, torna quase difícil corresponder às suas medições de condição para que você também possa resolver os problemas mais rapidamente.
Se você quiser aprender e dominar Kubernetes, DevOps e muito mais, confira o Diploma PG do IIIT-B & upGrad em Programa de Desenvolvimento de Software Full Stack.