
Pemantauan Kubernetes Dengan Prometheus [Dengan Kasus Penggunaan & Pemantauan]
Diterbitkan: 2020-09-23Daftar isi
Dimana dan Mengapa Prometheus Digunakan?
Prometheus Kubernetes adalah alat pemantauan yang dapat digunakan di klaster AWS, Azure, atau GCloud Kubernetes. Ini dianggap sebagai alat penting dalam infrastruktur modern. DevOps modern menjadi lebih kompleks untuk ditangani secara manual dan oleh karena itu membutuhkan lebih banyak otomatisasi, sehingga Anda biasanya memiliki beberapa server yang menjalankan aplikasi dalam container.
Ada ratusan proses berbeda yang berjalan pada infrastruktur tersebut di mana semua entitas saling berhubungan, sehingga mempertahankan pengaturan seperti itu agar berjalan dengan lancar dan tanpa waktu henti aplikasi, sangatlah menantang. Bayangkan memiliki infrastruktur yang rumit dengan banyak server yang tersebar di banyak lokasi, dan Anda tidak memiliki wawasan tentang apa yang terjadi pada tingkat perangkat keras atau tingkat aplikasi seperti kesalahan, respons, dan latensi.
Perangkat keras yang tidak berfungsi atau kelebihan beban mungkin kehabisan sumber daya dalam infrastruktur kompleks seperti itu, tetapi lebih banyak hal bisa salah ketika Anda memiliki banyak layanan dan aplikasi yang digunakan. Salah satu dari mereka dapat crash dan menyebabkan kegagalan layanan lain, memiliki begitu banyak bagian yang bergerak, dan tiba-tiba aplikasi menjadi tidak tersedia untuk pengguna. Anda harus dengan cepat mengidentifikasi apa yang sebenarnya dari ratusan hal yang berbeda ini yang salah, yang bisa jadi sulit dan memakan waktu saat men-debug sistem secara manual.
Beberapa Kasus Penggunaan untuk menggunakan Prometheus Monitoring
Misalnya, satu server tertentu kehabisan memori dan menjalankan container yang bertanggung jawab untuk menyediakan sinkronisasi database antara dua pot database di cluster Kubernetes. Itu, pada gilirannya, menyebabkan dua pot basis data itu gagal. Basis data tersebut digunakan oleh layanan autentikasi yang juga berhenti berfungsi karena basis data tidak tersedia.
Aplikasi yang bergantung pada layanan autentikasi itu tidak lagi dapat mengautentikasi pengguna di UI, tetapi dari sudut pandang pengguna, yang Anda lihat hanyalah kesalahan di UI. Ketika Anda tidak memiliki wawasan tentang apa yang terjadi di dalam cluster, Anda tidak melihat garis merah dari rantai peristiwa seperti yang ditampilkan di sini; Anda hanya melihat kesalahan. Jadi sekarang Anda mulai bekerja mundur dari sana untuk menemukan penyebabnya dan memperbaikinya. Tapi apa yang akan membuat proses pencarian masalah ini lebih efisien? Anda dapat menggunakan alat yang terus memantau apakah layanan berjalan dan peringatan muncul segera setelah salah satu layanan mogok.
Anda tahu persis apa yang terjadi, atau bahkan lebih baik, ini mengidentifikasi masalah bahkan sebelum terjadi dan memperingatkan administrator sistem yang bertanggung jawab atas infrastruktur itu untuk mencegah masalah itu. Misalnya, dalam kasus yang dibahas, akan secara teratur memeriksa status penggunaan memori di setiap server. Ketika di salah satu server, itu melonjak, misalnya, 70% selama lebih dari satu jam atau terus meningkat, itu memberi tahu tentang risiko bahwa memori di server itu mungkin segera habis.

Atau mari kita pertimbangkan skenario lain di mana Anda berhenti melihat log untuk aplikasi Anda karena pencarian elastis tidak menerima log baru karena server kehabisan ruang disk atau pencarian elastis mencapai batas penyimpanan yang dialokasikan untuk itu. Alat pemantau akan memeriksa ruang penyimpanan secara terus menerus dan membandingkannya dengan pencarian elastis konsumsi ruang penyimpanan. Ini akan melihat risiko dan memberi tahu pengelola tentang kemungkinan masalah penyimpanan.
Baca: Pertanyaan Wawancara Kubernetes
Anda dapat memberi tahu alat pemantau titik kritis saat peringatan harus dipicu. Jika Anda memiliki aplikasi penting yang benar-benar dapat memiliki kehilangan data log, Anda mungkin sangat ketat dan segera mengambil tindakan segera setelah kapasitas lima puluh atau enam puluh persen tercapai. Menambahkan lebih banyak ruang penyimpanan akan memakan waktu lama karena itu adalah proses birokrasi di organisasi Anda, di mana Anda memerlukan persetujuan dari beberapa departemen TI dan beberapa orang lainnya.

Anda juga ingin diberi tahu sebelumnya tentang kemungkinan masalah penyimpanan sehingga Anda memiliki lebih banyak waktu untuk memperbaikinya. Atau skenario ketiga di mana aplikasi tiba-tiba menjadi terlalu lambat karena satu layanan rusak dan mulai mengirim ratusan pesan kesalahan dalam satu lingkaran di seluruh jaringan, yang menciptakan lalu lintas jaringan yang tinggi dan memperlambat layanan lain untuk memiliki alat yang mendeteksi lonjakan seperti itu di jaringan .
Pelajari: Openshift Vs Kubernetes: Perbedaan Antara Openshift & Kubernetes
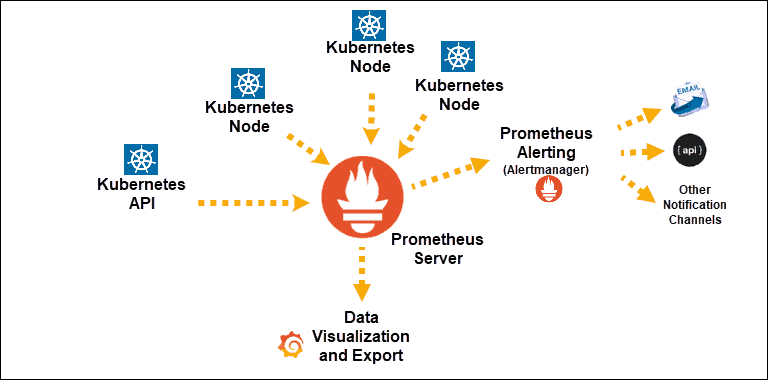
Sumber
Penemuan Layanan Kubernetes diekspos ke Prometheus
Komponen Utama: Server Prometheus
Arsitektur Prometheus
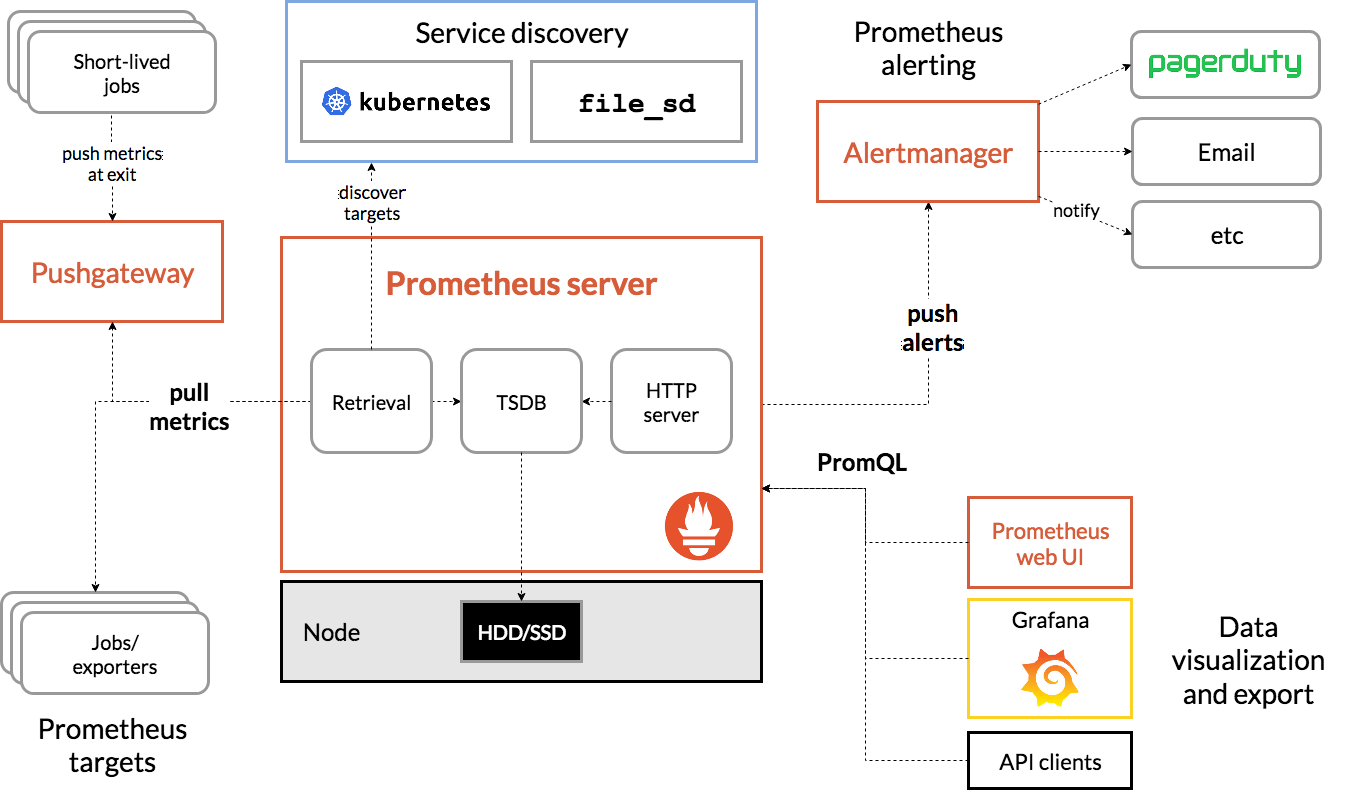
Sumber
Arsitektur Prometheus Kubernetes
Salah satu karakteristik penting dari Prometheus Kubernetes adalah ia dirancang untuk dapat diandalkan bahkan ketika sistem lain mengalami gangguan. Anda dapat mendiagnosis masalah dan memperbaikinya. Karenanya setiap server Prometheus mandiri, artinya tidak bergantung pada penyimpanan jaringan atau layanan jarak jauh lainnya.
Ini dimaksudkan untuk bekerja ketika bagian lain dari infrastruktur rusak, dan Anda tidak perlu menyiapkan infrastruktur yang luas untuk menggunakannya. Namun, ia juga memiliki kelemahan bahwa Prometheus sulit untuk diukur. Jadi, ketika Anda memiliki ratusan server, Anda mungkin ingin memiliki beberapa server Prometheus yang menggabungkan semua data metrik ini.
Konfigurasi dan penskalaan primitif dengan cara itu bisa sangat sulit karena karakteristik ini. Jadi, meskipun menggunakan satu simpul tidak terlalu rumit, dan Anda dapat memulai dengan sangat mudah, ini membatasi jumlah metrik yang dapat dipantau oleh Prometheus. Untuk mengatasinya, Anda dapat meningkatkan kapasitas server Prometheus sehingga dapat menyimpan lebih banyak data metrik atau membatasi jumlah metrik yang dikumpulkan Prometheus dari aplikasi agar hanya yang relevan saja.
Anda dapat meningkatkan pengetahuan Anda tentang topik tersebut dengan melakukan kursus komputasi awan pada platform seperti upGrad, Udemy, Coursera, dll. karena alat pemantauan ini dapat digunakan di cloud. Khususnya dengan upGrad, kursus dirancang oleh salah satu institusi terkenal di negara kita IIIT-B. Ini akan memberi Anda pengalaman langsung dan aspek pengetahuan yang lebih luas.
Lihat: Kubernetes Vs. Docker: Perbedaan Utama yang Harus Anda Ketahui
Kesimpulan
Kubernetes menyederhanakan penerapan, penskalaan, dan pengelolaan aplikasi dan layanan mikro dalam container. Ini membantu menjaga administrasi tetap berjalan, namun untuk mengenali dan menyelesaikan masalah tersembunyi seperti eksekusi yang lambat, Anda perlu kemampuan untuk mengumpulkan dan membayangkan aplikasi pondasi atas ke bawah dan informasi eksekusi dari atas kondisi Anda.
Tidak mendekati data berkelanjutan, di samping informasi yang relevan, membuatnya hampir sulit untuk menyesuaikan dengan pengukuran kondisi Anda sehingga Anda juga dapat mengatasi masalah dengan lebih cepat.
Jika Anda ingin belajar dan menguasai Kubernetes, DevOps, dan banyak lagi, lihat Diploma PG IIIT-B & upGrad dalam Program Pengembangan Perangkat Lunak Stack Penuh.