
Monitoraggio Kubernetes con Prometheus [con casi d'uso e monitoraggio]
Pubblicato: 2020-09-23Sommario
Dove e perché viene utilizzato Prometeo?
Prometheus Kubernetes è uno strumento di monitoraggio che può essere distribuito su cluster AWS, Azure o GCloud Kubernetes. È considerato uno strumento essenziale nelle moderne infrastrutture. Il DevOps moderno sta diventando più complesso da gestire manualmente e quindi necessita di maggiore automazione, quindi in genere hai più server che eseguono applicazioni containerizzate.
Esistono centinaia di processi diversi in esecuzione su quell'infrastruttura in cui tutte le entità sono interconnesse, quindi mantenere una tale configurazione per funzionare senza intoppi e senza tempi di inattività delle applicazioni è molto impegnativo. Immagina di avere un'infrastruttura così complicata con carichi di server distribuiti in molte posizioni e di non avere informazioni su ciò che sta accadendo a livello di hardware o di applicazione come errori, risposta e latenza.
L'hardware inattivo o sovraccarico potrebbe esaurire le risorse in un'infrastruttura così complessa, ma più cose possono andare storte quando sono distribuiti tonnellate di servizi e applicazioni. Ognuno di essi può bloccarsi e causare il fallimento di altri servizi, avere così tanti pezzi in movimento e improvvisamente l'applicazione non è disponibile per gli utenti. È necessario identificare rapidamente cosa esattamente tra queste centinaia di cose diverse è andato storto, il che potrebbe essere difficile e richiedere molto tempo durante il debug manuale del sistema.
Alcuni casi d'uso per l'utilizzo di Prometheus Monitoring
Ad esempio, supponiamo che un server specifico abbia esaurito la memoria e abbia avviato un container in esecuzione che era responsabile della sincronizzazione del database tra due pot di database in un cluster Kubernetes. Ciò, a sua volta, ha causato il fallimento di quei due contenitori di database. Tale database è stato utilizzato da un servizio di autenticazione che ha smesso di funzionare anche perché il database non è disponibile.
L'applicazione che dipendeva da quel servizio di autenticazione non poteva più autenticare gli utenti nell'interfaccia utente, ma dal punto di vista dell'utente, tutto ciò che vedi è un errore nell'interfaccia utente. Quando non hai un'idea di cosa sta succedendo all'interno del cluster, non vedi quella linea rossa della catena di eventi mostrata qui; vedi solo l'errore. Quindi ora inizi a lavorare all'indietro da lì per trovare la causa e risolverla. Ma cosa renderà più efficiente questo processo di ricerca dei problemi? È possibile utilizzare uno strumento che monitora continuamente se i servizi sono in esecuzione e gli avvisi vengono visualizzati non appena un servizio si arresta in modo anomalo.
Sai esattamente cosa è successo o, ancora meglio, identifica i problemi prima ancora che si verifichino e avvisa gli amministratori di sistema responsabili di quell'infrastruttura per prevenire quel problema. Ad esempio, in questo caso discusso, verificherebbe regolarmente lo stato di utilizzo della memoria su ciascun server. Quando su uno dei server, supera, ad esempio, il 70% per oltre un'ora o continua ad aumentare, segnala il rischio che la memoria su quel server possa presto esaurirsi.

Oppure prendiamo in considerazione un altro scenario in cui si interrompe la visualizzazione dei log per l'applicazione perché la ricerca elastica non accetta nuovi log poiché il server ha esaurito lo spazio su disco o la ricerca elastica ha raggiunto il limite di archiviazione allocato. Lo strumento di monitoraggio verificherebbe continuamente lo spazio di archiviazione e lo confronterebbe con il consumo di spazio di archiviazione della ricerca elastica. Vedrà il rischio e informerà il manutentore del possibile problema di archiviazione.
Leggi: Domande sull'intervista a Kubernetes

Puoi dire allo strumento di monitoraggio qual è il punto critico in cui deve essere attivato l'avviso. Se si dispone di un'applicazione critica che può assolutamente avere una perdita di dati di registro, è possibile essere molto severi e prendere le misure non appena viene raggiunta la capacità del cinquanta o sessanta percento. L'aggiunta di più spazio di archiviazione richiederà molto tempo perché è un processo burocratico all'interno dell'organizzazione, in cui è necessaria l'approvazione di alcuni dipartimenti IT e di molte altre persone.
Vuoi anche essere informato in anticipo sul possibile problema di archiviazione in modo da avere più tempo per risolverlo. O un terzo scenario in cui l'applicazione diventa improvvisamente troppo lenta perché un servizio si interrompe e inizia a inviare centinaia di messaggi di errore in un loop attraverso la rete, creando un traffico di rete elevato e rallentando altri servizi per avere uno strumento che rilevi tali picchi in una rete .
Impara: Openshift vs Kubernetes: differenza tra Openshift e Kubernetes
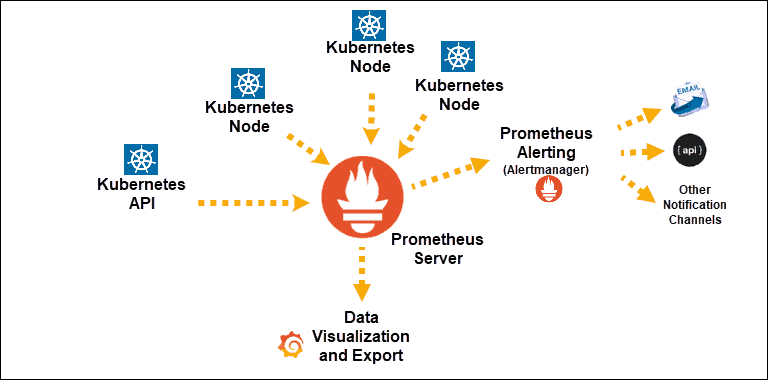
Fonte
Scoperte del servizio Kubernetes esposte a Prometheus
Componente principale: server Prometeo
Architettura di Prometeo
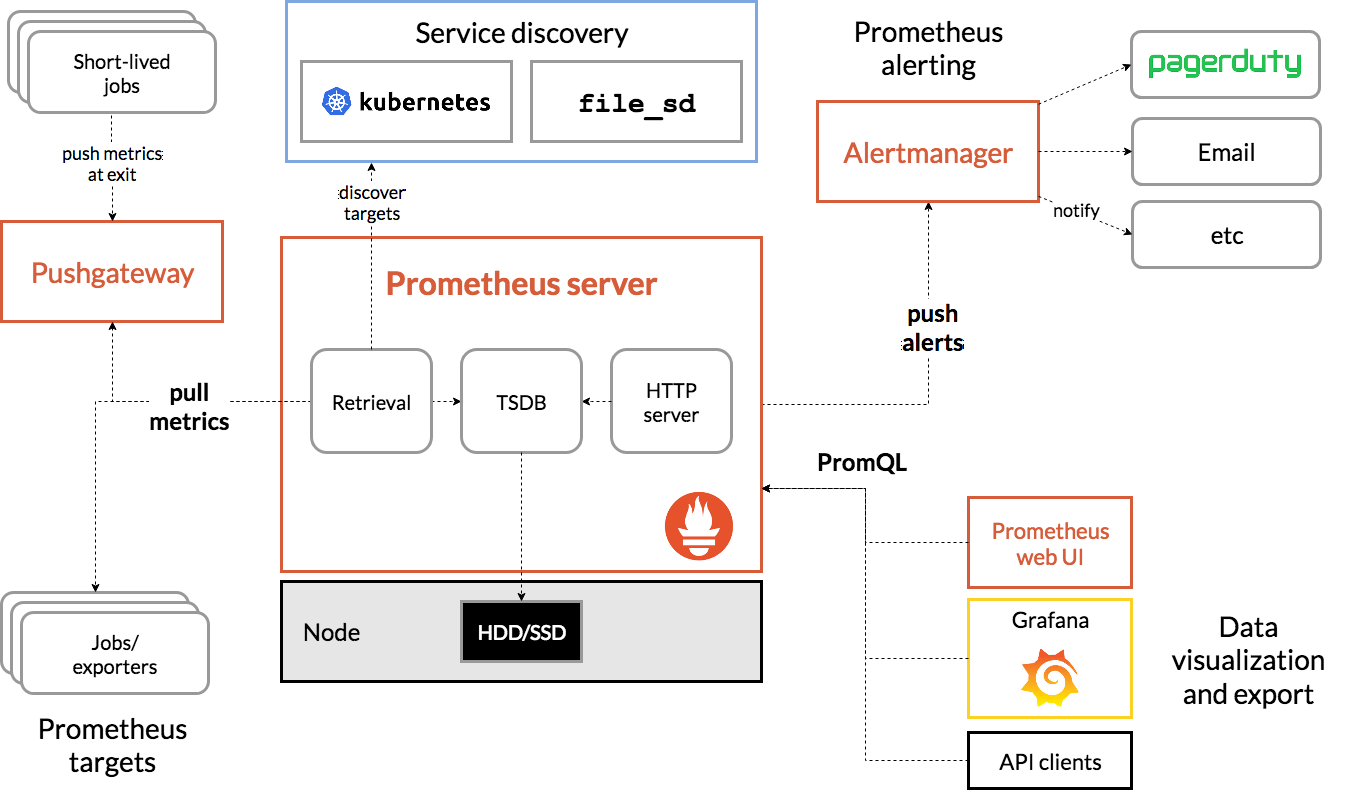
Fonte
L'architettura di Prometeo Kubernetes
Una delle caratteristiche importanti di Prometheus Kubernetes è che è progettato per essere affidabile anche in caso di interruzione di altri sistemi. È possibile diagnosticare i problemi e risolverli. Quindi ogni server Prometheus è autonomo, il che significa che non dipende dall'archiviazione di rete o da altri servizi remoti.
È pensato per funzionare quando altre parti dell'infrastruttura sono danneggiate e non è necessario configurare un'infrastruttura estesa per utilizzarla. Tuttavia, ha anche lo svantaggio che Prometeo può essere difficile da scalare. Quindi, quando hai centinaia di server, potresti voler avere più server Prometheus che aggregano tutti questi dati di metrica.
Configurare e ridimensionare le primitive in questo modo può essere molto difficile a causa di queste caratteristiche. Pertanto, sebbene l'utilizzo di un singolo nodo sia meno complesso e puoi iniziare molto facilmente, limita il numero di metriche che Prometheus può monitorare. Per ovviare a questo problema, puoi aumentare la capacità del server Prometheus in modo che possa archiviare più dati di metriche o limitare il numero di metriche che Prometheus raccoglie dalle applicazioni per mantenerlo limitato solo a quelle pertinenti.
Puoi migliorare le tue conoscenze su tali argomenti facendo corsi di cloud computing su piattaforme come upGrad, Udemy, Coursera, ecc. Poiché questo strumento di monitoraggio può essere distribuito sul cloud. Soprattutto con upGrad, i corsi sono progettati da una delle istituzioni più rinomate del nostro paese IIIT-B. Questo ti darà un'esperienza pratica e un aspetto di conoscenza più ampio.
Scopri: Kubernetes vs. Docker: differenze primarie che dovresti conoscere
Conclusione
Kubernetes semplifica la distribuzione, la scalabilità e la gestione di applicazioni e microservizi containerizzati. Ciò aiuta a far funzionare le amministrazioni, ma per riconoscere e risolvere problemi nascosti come un'esecuzione lenta, è necessaria la capacità di accumulare e immaginare dall'alto verso il basso le informazioni sull'applicazione e l'esecuzione da sopra la propria condizione.
Non avvicinarsi ai dati continui, insieme alle informazioni rilevanti, rende quasi difficile corrispondere alle misurazioni delle tue condizioni, quindi anche tu puoi affrontare i problemi più rapidamente.
Se vuoi imparare e padroneggiare Kubernetes, DevOps e altro, dai un'occhiata al Diploma PG di IIIT-B e upGrad nel programma di sviluppo software Full Stack.