
Monitorizare Kubernetes cu Prometheus [cu cazuri de utilizare și monitorizare]
Publicat: 2020-09-23Cuprins
Unde și de ce se utilizează Prometheus?
Prometheus Kubernetes este un instrument de monitorizare care poate fi implementat pe clustere AWS, Azure sau GCloud Kubernetes. Este considerat un instrument esențial în infrastructura modernă. DevOps modern devine din ce în ce mai complex de gestionat manual și, prin urmare, are nevoie de mai multă automatizare, astfel încât de obicei aveți mai multe servere care rulează aplicații containerizate.
Există sute de procese diferite care rulează pe acea infrastructură în care toate entitățile sunt interconectate, așa că menținerea unei astfel de setări pentru a rula fără probleme și fără perioade de nefuncționare a aplicațiilor este foarte dificilă. Imaginați-vă că aveți o infrastructură atât de complicată cu o mulțime de servere distribuite în mai multe locații și nu aveți nicio perspectivă asupra a ceea ce se întâmplă la nivel de hardware sau la nivel de aplicație, cum ar fi erorile, răspunsul și latența.
Hardware-ul oprit sau supraîncărcat poate rămâne fără resurse într-o astfel de infrastructură complexă, dar mai multe lucruri pot merge prost atunci când aveți o mulțime de servicii și aplicații implementate. Oricare dintre ele se poate prăbuși și poate cauza defecțiuni ale altor servicii, are atât de multe piese în mișcare și dintr-o dată aplicația devine indisponibilă utilizatorilor. Trebuie să identificați rapid ce anume dintre aceste sute de lucruri diferite au mers prost, ceea ce ar putea fi dificil și consumator de timp atunci când depanați manual sistemul.
Câteva cazuri de utilizare pentru utilizarea Prometheus Monitoring
De exemplu, să presupunem că un anumit server a rămas fără memorie și a pornit un container care rulează care era responsabil pentru furnizarea de sincronizare a bazei de date între două pot-uri de baze de date dintr-un cluster Kubernetes. Asta, la rândul său, a făcut ca acele două poturi de baze de date să eșueze. Acea bază de date a fost folosită de un serviciu de autentificare care și-a încetat să funcționeze, deoarece baza de date nu este disponibilă.
Aplicația care depindea de acel serviciu de autentificare nu mai putea autentifica utilizatorii în UI, dar din perspectiva utilizatorului, tot ce vedeți este o eroare în UI. Când nu aveți o perspectivă asupra a ceea ce se întâmplă în interiorul clusterului, nu vedeți acea linie roșie a lanțului de evenimente așa cum este afișată aici; doar vezi eroarea. Deci acum începeți să lucrați înapoi de acolo pentru a găsi cauza și a o remedia. Dar ce va face acest proces cu probleme de căutare mai eficient? Puteți folosi un instrument care monitorizează continuu dacă serviciile rulează și apar alerte de îndată ce un serviciu se blochează.
Știți exact ce s-a întâmplat, sau și mai bine, identifică problemele înainte ca acestea să apară și alertează administratorii de sistem responsabili pentru acea infrastructură pentru a preveni această problemă. De exemplu, în acest caz discutat, ar verifica în mod regulat starea utilizării memoriei pe fiecare server. Atunci când pe unul dintre servere crește, de exemplu, peste 70% timp de peste o oră sau continuă să crească, anunță despre riscul ca memoria de pe acel server să se epuizeze în curând.

Sau să luăm în considerare un alt scenariu în care nu mai vedeți jurnalele pentru aplicația dvs. deoarece căutarea elastică nu acceptă niciun log nou, deoarece serverul a rămas fără spațiu pe disc sau căutarea elastică a atins limita de stocare care i-a fost alocată. Instrumentul de monitorizare ar verifica în mod continuu spațiul de stocare și îl va compara cu consumul de căutare elastică al spațiului de stocare. Acesta va vedea riscul și va notifica întreținătorul cu privire la posibila problemă de stocare.
Citiți: Întrebări de interviu Kubernetes
Puteți spune instrumentului de monitorizare care este acel punct critic când ar trebui să fie declanșată alerta. Dacă aveți o aplicație critică care poate avea absolut orice pierdere de date de jurnal, este posibil să fiți foarte strict și odată să luați măsuri de îndată ce capacitatea de cincizeci sau șaizeci la sută este atinsă. Adăugarea mai multor spațiu de stocare va dura mult timp deoarece este un proces birocratic în organizația dvs., unde aveți nevoie de aprobarea unui departament IT și a mai multor persoane.

De asemenea, doriți să fiți notificat mai devreme despre posibila problemă de stocare, astfel încât să aveți mai mult timp să o remediați. Sau un al treilea scenariu în care aplicația devine brusc prea lentă, deoarece un serviciu se defectează și începe să trimită sute de mesaje de eroare într-o buclă în rețea, ceea ce creează un trafic ridicat în rețea și încetinește alte servicii pentru a avea un instrument care detectează astfel de vârfuri într-o rețea. .
Aflați: Openshift vs Kubernetes: diferența dintre Openshift și Kubernetes
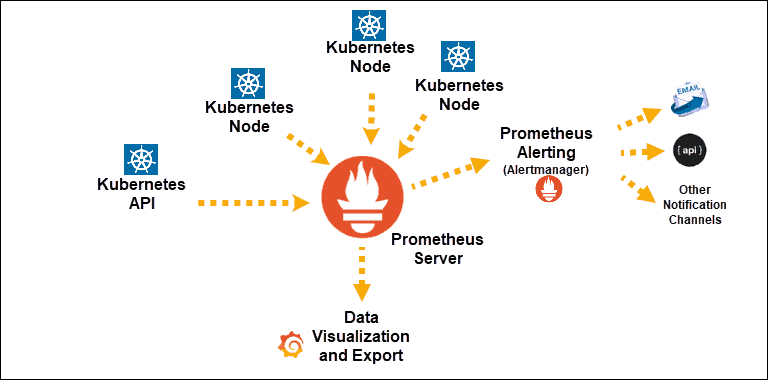
Sursă
Descoperirile serviciului Kubernetes expuse lui Prometheus
Componenta principală: Server Prometheus
Arhitectura Prometeu
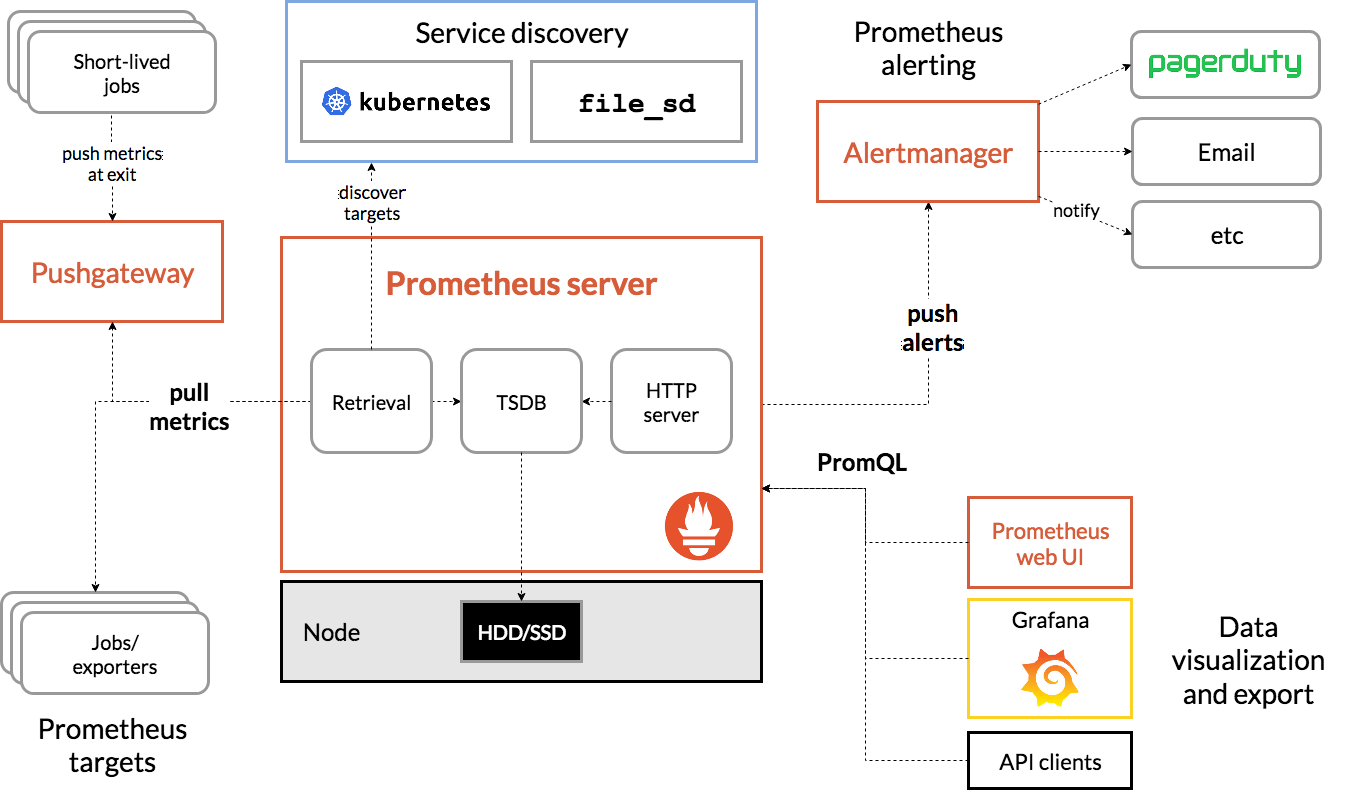
Sursă
Arhitectura lui Prometheus Kubernetes
Una dintre caracteristicile importante ale Prometheus Kubernetes este că este proiectat să fie fiabil chiar și atunci când alte sisteme au o întrerupere. Puteți diagnostica problemele și le puteți remedia. Prin urmare, fiecare server Prometheus este autonom, ceea ce înseamnă că nu depinde de stocarea în rețea sau de alte servicii de la distanță.
Este menit să funcționeze atunci când alte părți ale infrastructurii sunt stricate și nu trebuie să configurați o infrastructură extinsă pentru a o folosi. Cu toate acestea, are și dezavantajul că Prometheus poate fi greu de scalat. Așadar, atunci când aveți sute de servere, s-ar putea să doriți să aveți mai multe servere Prometheus care să adună toate aceste date de valori.
Configurarea și scalarea primitivelor în acest fel poate fi foarte dificilă din cauza acestor caracteristici. Deci, în timp ce folosirea unui singur nod este mai puțin complexă și puteți începe foarte ușor, limitează numărul de metrici pe care Prometheus le poate monitoriza. Pentru a rezolva asta, fie creșteți capacitatea serverului Prometheus, astfel încât acesta să poată stoca mai multe date de metrică, fie limitați numărul de metrici pe care Prometheus le colectează din aplicații pentru a le menține doar la cele relevante.
Vă puteți îmbunătăți cunoștințele despre astfel de subiecte, ținând cursuri de cloud computing pe platforme precum upGrad, Udemy, Coursera etc., deoarece acest instrument de monitorizare poate fi implementat pe cloud. În special cu upGrad, cursurile sunt concepute de una dintre instituțiile de mare renume ale țării noastre IIIT-B. Acest lucru vă va oferi experiență practică și un aspect mai larg de cunoștințe.
Verificați: Kubernetes vs. Docker: Diferențele primare pe care ar trebui să le cunoașteți
Concluzie
Kubernetes simplifică implementarea, scalarea și gestionarea aplicațiilor și microserviciilor containerizate. Acest lucru ajută la menținerea administrațiilor în funcțiune, dar pentru a recunoaște și a rezolva probleme ascunse, cum ar fi o execuție lentă, aveți nevoie de capacitatea de a acumula și de a vă imagina aplicații fundației de sus până jos și informații de execuție din starea dumneavoastră.
Nu abordarea datelor continue, alături de informații relevante, face aproape dificilă corespondența cu măsurătorile stării tale, astfel încât și tu să poți aborda problemele mai rapid.
Dacă doriți să învățați și să stăpâniți Kubernetes, DevOps și multe altele, consultați IIIT-B & upGrad's PG Diploma in Full Stack Software Development Program.