
Supervisión de Kubernetes con Prometheus [con casos de uso y supervisión]
Publicado: 2020-09-23Tabla de contenido
¿Dónde y por qué se usa Prometheus?
Prometheus Kubernetes es una herramienta de monitoreo que se puede implementar en clústeres de AWS, Azure o GCloud Kubernetes. Se considera como una herramienta esencial en la infraestructura moderna. El DevOps moderno se está volviendo más complejo de manejar manualmente y, por lo tanto, necesita más automatización, por lo que normalmente tiene varios servidores que ejecutan aplicaciones en contenedores.
Hay cientos de procesos diferentes que se ejecutan en esa infraestructura donde todas las entidades están interconectadas, por lo que mantener una configuración de este tipo para que funcione sin problemas y sin tiempos de inactividad de la aplicación es un gran desafío. Imagine tener una infraestructura tan complicada con una gran cantidad de servidores distribuidos en muchas ubicaciones, y no tiene idea de lo que sucede a nivel de hardware o de aplicación, como errores, respuesta y latencia.
El hardware inactivo o sobrecargado puede estar quedándose sin recursos en una infraestructura tan compleja, pero más cosas pueden salir mal cuando tiene toneladas de servicios y aplicaciones implementadas. Cualquiera de ellos puede colapsar y causar la falla de otros servicios, tener tantas piezas en movimiento y, de repente, la aplicación deja de estar disponible para los usuarios. Debe identificar rápidamente qué fue exactamente lo que salió mal de estas cien cosas diferentes, lo que podría ser difícil y llevar mucho tiempo al depurar el sistema manualmente.
Algunos casos de uso para usar Prometheus Monitoring
Por ejemplo, digamos que un servidor específico se quedó sin memoria e inició un contenedor en ejecución que era responsable de proporcionar sincronización de base de datos entre dos contenedores de base de datos en un clúster de Kubernetes. Eso, a su vez, hizo que fallaran esos dos potes de la base de datos. Esa base de datos fue utilizada por un servicio de autenticación que también dejó de funcionar porque la base de datos no está disponible.
La aplicación que dependía de ese servicio de autenticación ya no podía autenticar a los usuarios en la interfaz de usuario, pero desde la perspectiva del usuario, todo lo que ve es un error en la interfaz de usuario. Cuando no tiene una idea de lo que sucede dentro del clúster, no ve esa línea roja de la cadena de eventos que se muestra aquí; solo ves el error. Entonces ahora comienza a trabajar hacia atrás desde allí para encontrar la causa y solucionarlo. Pero, ¿qué hará que este proceso de búsqueda de problemas sea más eficiente? Podría usar una herramienta que monitoree continuamente si los servicios se están ejecutando y alertas tan pronto como un servicio falla.
Sabe exactamente lo que sucedió, o incluso mejor, identifica los problemas antes de que ocurran y alerta a los administradores del sistema responsables de esa infraestructura para evitar ese problema. Por ejemplo, en este caso discutido, verificaría periódicamente el estado del uso de la memoria en cada servidor. Cuando en uno de los servidores, aumenta, por ejemplo, el 70% durante más de una hora o sigue aumentando, notifica sobre el riesgo de que la memoria en ese servidor se agote pronto.

O consideremos otro escenario en el que deja de ver registros para su aplicación porque la búsqueda elástica no acepta ningún registro nuevo porque el servidor se quedó sin espacio en disco o la búsqueda elástica alcanzó el límite de almacenamiento que se le asignó. La herramienta de monitoreo verificaría el espacio de almacenamiento continuamente y lo compararía con el consumo de espacio de almacenamiento de búsqueda elástica. Verá el riesgo y notificará al mantenedor del posible problema de almacenamiento.
Leer: Preguntas de la entrevista de Kubernetes
Puede decirle a la herramienta de monitoreo cuál es ese punto crítico cuando se debe activar la alerta. Si tiene una aplicación crítica que absolutamente puede tener cualquier pérdida de datos de registro, puede ser muy estricto y tomar medidas tan pronto como se alcance el cincuenta o sesenta por ciento de la capacidad. Agregar más espacio de almacenamiento llevará mucho tiempo porque es un proceso burocrático en su organización, donde necesita la aprobación de algún departamento de TI y varias otras personas.

También desea recibir una notificación antes sobre el posible problema de almacenamiento para que tenga más tiempo para solucionarlo. O un tercer escenario en el que la aplicación de repente se vuelve demasiado lenta porque un servicio falla y comienza a enviar cientos de mensajes de error en un bucle a través de la red, lo que crea un alto tráfico en la red y ralentiza otros servicios para tener una herramienta que detecte tales picos en una red. .
Aprenda: Openshift Vs Kubernetes: diferencia entre Openshift y Kubernetes
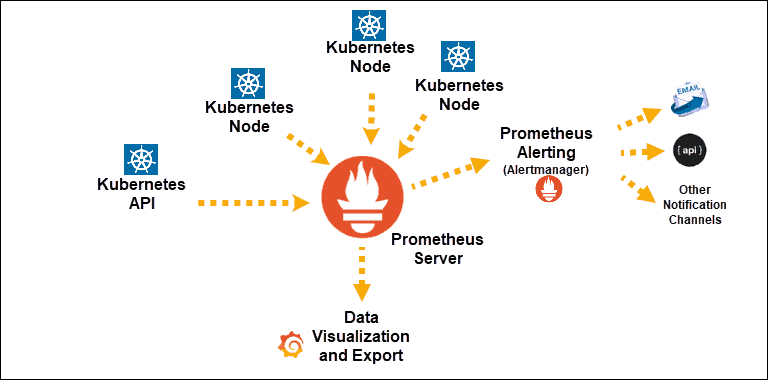
Fuente
Descubrimientos de Kubernetes Service expuestos a Prometheus
Componente principal: Servidor Prometheus
Arquitectura Prometeo
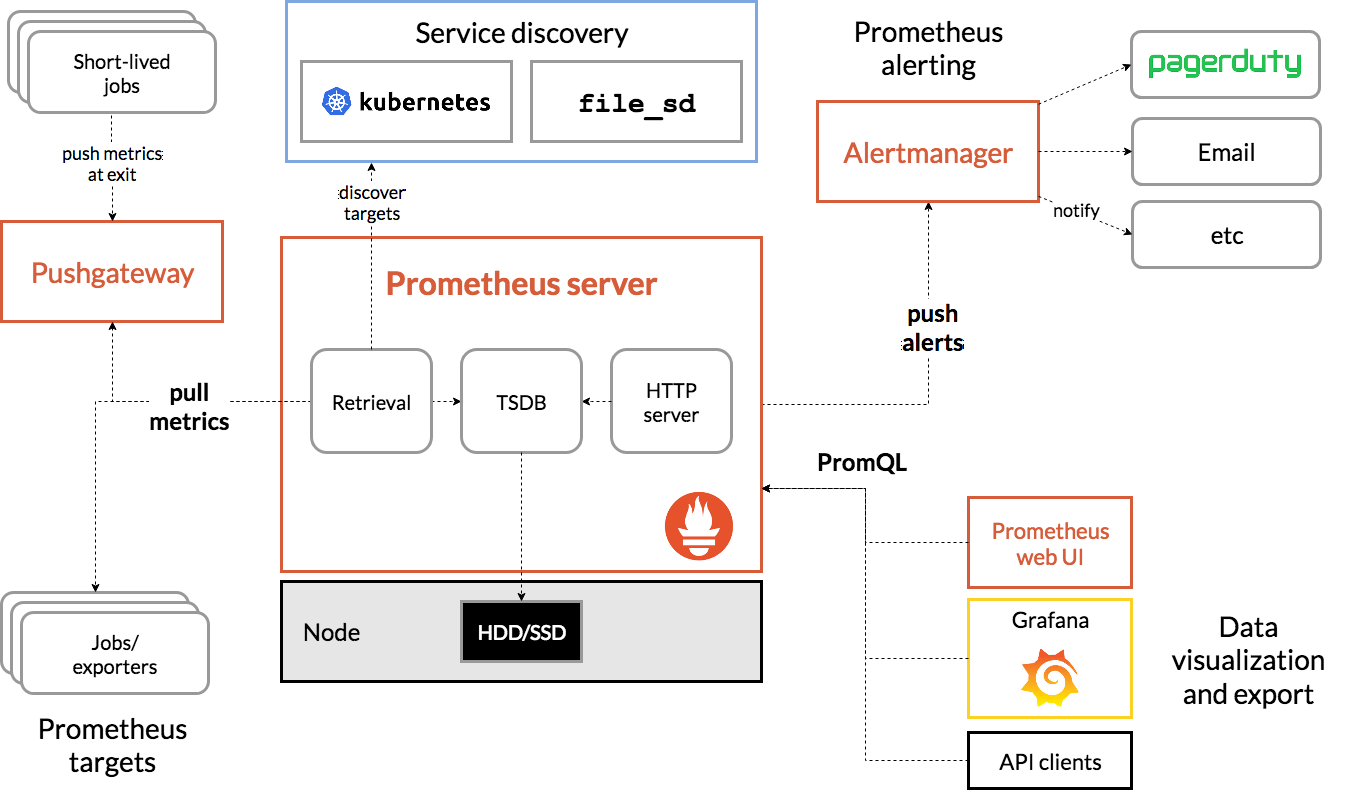
Fuente
La arquitectura de Prometheus Kubernetes
Una de las características importantes de Prometheus Kubernetes es que está diseñado para ser confiable incluso cuando otros sistemas tienen una interrupción. Puede diagnosticar los problemas y solucionarlos. Por lo tanto, cada servidor Prometheus es autónomo, lo que significa que no depende del almacenamiento en red ni de otros servicios remotos.
Está diseñado para funcionar cuando otras partes de la infraestructura están dañadas y no es necesario configurar una infraestructura extensa para usarla. Sin embargo, también tiene la desventaja de que Prometheus puede ser difícil de escalar. Entonces, cuando tiene cientos de servidores, es posible que desee tener varios servidores Prometheus que agreguen todos estos datos de métricas.
Configurar y escalar primitivas de esa manera puede ser muy difícil debido a estas características. Por lo tanto, si bien el uso de un solo nodo es menos complejo y puede comenzar muy fácilmente, limita la cantidad de métricas que Prometheus puede monitorear. Para evitarlo, aumente la capacidad del servidor de Prometheus para que pueda almacenar más datos de métricas o limite la cantidad de métricas que Prometheus recopila de las aplicaciones para limitarlas solo a las relevantes.
Puede mejorar sus conocimientos sobre estos temas realizando cursos de computación en la nube en plataformas como upGrad, Udemy, Coursera, etc., ya que esta herramienta de monitoreo se puede implementar en la nube. Especialmente con upGrad, los cursos están diseñados por una de las instituciones de mayor reputación de nuestro país IIIT-B. Esto le dará experiencia práctica y un aspecto de conocimiento más amplio.
Echa un vistazo: Kubernetes vs. Docker: diferencias principales que debe conocer
Conclusión
Kubernetes simplifica la implementación, el escalado y la gestión de microservicios y aplicaciones en contenedores. Esto ayuda a mantener las administraciones en funcionamiento, pero para reconocer y resolver problemas ocultos como una ejecución lenta, necesita la capacidad de acumular e imaginar información básica de aplicación y ejecución de su estado.
No acercarse a los datos continuos, junto con la información relevante, hace que sea casi difícil corresponder a las mediciones de su condición para que usted también pueda abordar los problemas más rápidamente.
Si desea aprender y dominar Kubernetes, DevOps y más, consulte el Diploma PG de IIIT-B & upGrad en el programa de desarrollo de software de pila completa.