
Monitorowanie Kubernetes za pomocą Prometheusa [z przypadkami użycia i monitorowaniem]
Opublikowany: 2020-09-23Spis treści
Gdzie i dlaczego jest używany Prometeusz?
Prometheus Kubernetes to narzędzie do monitorowania, które można wdrożyć w klastrach AWS, Azure lub GCloud Kubernetes. Jest uważany za niezbędne narzędzie w nowoczesnej infrastrukturze. Nowoczesne metody DevOps stają się coraz bardziej skomplikowane w obsłudze ręcznej i dlatego wymagają większej automatyzacji, więc zazwyczaj masz wiele serwerów, na których działają aplikacje konteneryzowane.
W tej infrastrukturze, w której wszystkie jednostki są ze sobą połączone, działają setki różnych procesów, więc utrzymanie takiej konfiguracji, aby działała płynnie i bez przestojów aplikacji, jest bardzo trudne. Wyobraź sobie, że masz tak skomplikowaną infrastrukturę z mnóstwem serwerów rozmieszczonych w wielu lokalizacjach i nie masz wglądu w to, co dzieje się na poziomie sprzętu lub aplikacji, takie jak błędy, odpowiedź i opóźnienia.
W tak złożonej infrastrukturze sprzęt nie działa lub jest przeciążony, może się kończyć zasoby, ale więcej rzeczy może pójść nie tak, gdy masz mnóstwo wdrożonych usług i aplikacji. Każdy z nich może się zawiesić i spowodować awarię innych usług, mieć tak wiele ruchomych elementów i nagle aplikacja staje się niedostępna dla użytkowników. Musisz szybko określić, co dokładnie z tych stu różnych rzeczy poszło nie tak, co może być trudne i czasochłonne podczas ręcznego debugowania systemu.
Niektóre przypadki użycia aplikacji Prometheus Monitoring
Załóżmy na przykład, że jednemu określonemu serwerowi zabrakło pamięci i uruchomił działający kontener, który był odpowiedzialny za zapewnianie synchronizacji bazy danych między dwoma zbiorami baz danych w klastrze Kubernetes. To z kolei spowodowało awarię tych dwóch puli bazy danych. Ta baza danych była używana przez usługę uwierzytelniania, która również przestała działać, ponieważ baza danych jest niedostępna.
Aplikacja zależna od tej usługi uwierzytelniania nie może już uwierzytelniać użytkowników w interfejsie użytkownika, ale z perspektywy użytkownika widzisz tylko błąd w interfejsie użytkownika. Kiedy nie masz wglądu w to, co dzieje się wewnątrz gromady, nie widzisz tej czerwonej linii łańcucha zdarzeń, jak pokazano tutaj; po prostu widzisz błąd. Więc teraz zaczynasz pracę wstecz, aby znaleźć przyczynę i ją naprawić. Ale co sprawi, że ten proces wyszukiwania będzie bardziej wydajny? Możesz użyć narzędzia, które stale monitoruje, czy usługi są uruchomione, i wyświetlają alerty, gdy tylko jedna usługa ulegnie awarii.
Dokładnie wiesz, co się stało, a nawet lepiej, identyfikuje problemy, zanim jeszcze się pojawią, i ostrzega administratorów systemu odpowiedzialnych za tę infrastrukturę, aby temu zapobiec. Na przykład w omawianym przypadku regularnie sprawdzałby stan wykorzystania pamięci na każdym serwerze. Gdy na jednym z serwerów przekracza np. 70% przez ponad godzinę lub stale rośnie, informuje o ryzyku, że pamięć na tym serwerze może się wkrótce skończyć.

Lub rozważmy inny scenariusz, w którym przestajesz widzieć dzienniki aplikacji, ponieważ wyszukiwanie elastyczne nie akceptuje żadnych nowych dzienników, ponieważ serwerowi zabrakło miejsca na dysku lub wyszukiwanie elastyczne osiągnęło przydzielony dla niego limit magazynu. Narzędzie do monitorowania stale sprawdzałoby przestrzeń dyskową i porównywało ją z elastycznym wyszukiwaniem zużycia przestrzeni dyskowej. Zobaczy ryzyko i powiadomi opiekuna o możliwym problemie z przechowywaniem.
Przeczytaj: Pytania do wywiadu Kubernetes
Możesz powiedzieć narzędziu monitorującemu, jaki jest ten krytyczny punkt, kiedy alarm powinien zostać wyzwolony. Jeśli masz krytyczną aplikację, która bezwzględnie może spowodować utratę danych dziennika, możesz być bardzo rygorystyczny i raz podjąć środki, gdy tylko zostanie osiągnięta pięćdziesiąt lub sześćdziesiąt procent pojemności. Dodanie większej przestrzeni dyskowej zajmie dużo czasu, ponieważ jest to biurokratyczny proces w Twojej organizacji, który wymaga zgody jakiegoś działu IT i kilku innych osób.

Chcesz również wcześniej otrzymywać powiadomienia o możliwym problemie z przechowywaniem, aby mieć więcej czasu na jego naprawienie. Lub trzeci scenariusz, w którym aplikacja nagle staje się zbyt wolna, ponieważ jedna usługa ulega awarii i zaczyna wysyłać setki komunikatów o błędach w pętli przez sieć, co generuje duży ruch w sieci i spowalnia inne usługi, aby mieć narzędzie wykrywające takie skoki w sieci .
Dowiedz się: Openshift vs Kubernetes: różnica między Openshift a Kubernetes
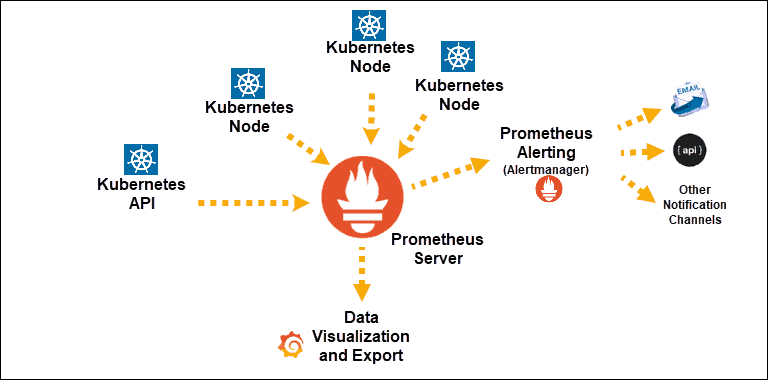
Źródło
Odkrycia usługi Kubernetes wystawione na działanie Prometheusa
Główny składnik: serwer Prometheus
Architektura Prometeusza
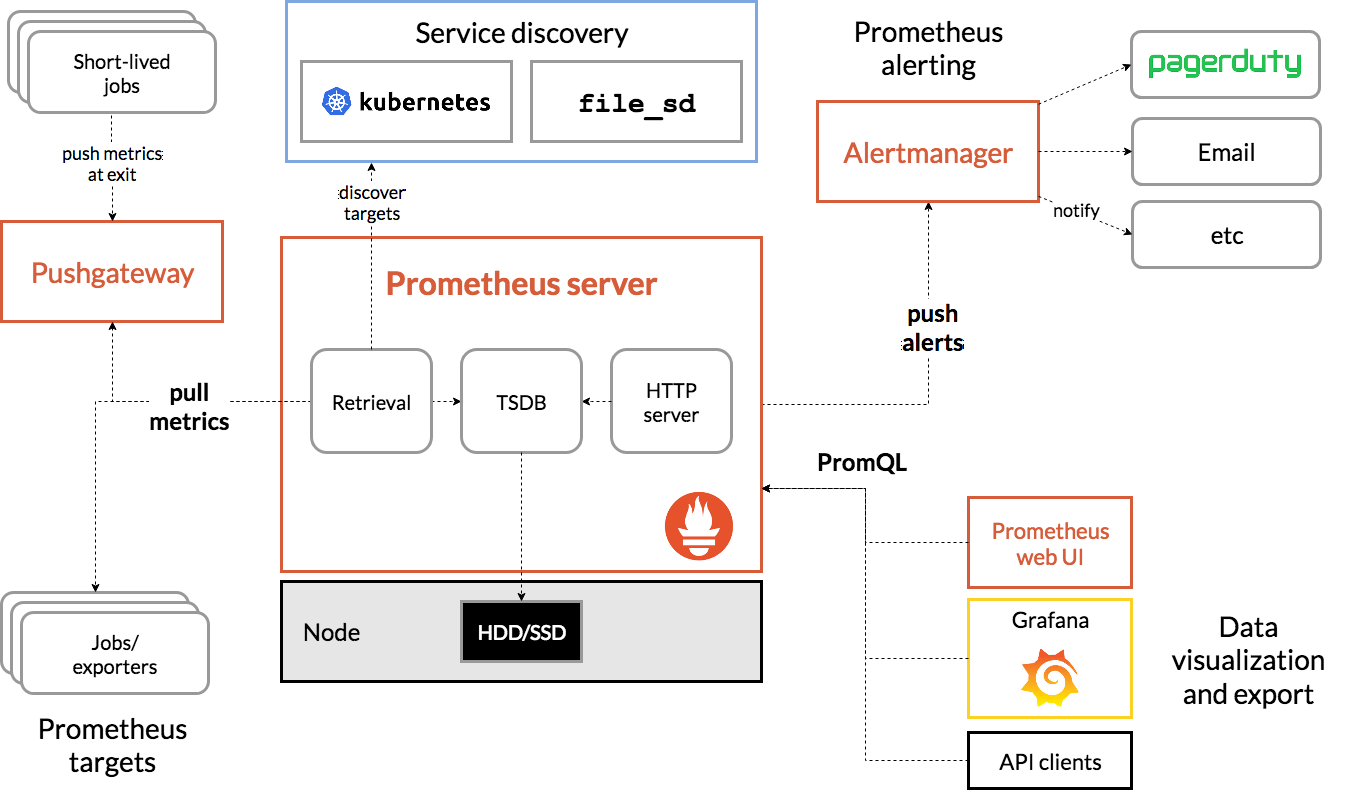
Źródło
Architektura Prometeusza Kubernetesa
Jedną z ważnych cech Prometheus Kubernetes jest to, że jest on zaprojektowany tak, aby był niezawodny nawet w przypadku awarii innych systemów. Możesz zdiagnozować problemy i je naprawić. Dlatego każdy serwer Prometheus jest samowystarczalny, co oznacza, że nie jest zależny od pamięci sieciowej ani innych usług zdalnych.
Ma działać, gdy inne części infrastruktury są uszkodzone i nie musisz konfigurować rozbudowanej infrastruktury, aby z niej korzystać. Jednak ma to również tę wadę, że Prometheus może być trudny do skalowania. Tak więc, gdy masz setki serwerów, możesz chcieć mieć wiele serwerów Prometheus, które agregują wszystkie te dane.
Konfiguracja i skalowanie prymitywów w ten sposób może być bardzo trudne ze względu na te cechy. Tak więc, chociaż korzystanie z pojedynczego węzła jest mniej skomplikowane i można bardzo łatwo rozpocząć, ogranicza liczbę metryk, które Prometheus może monitorować. Aby obejść ten problem, należy albo zwiększyć pojemność serwera Prometheus, aby mógł przechowywać więcej danych metrykalnych, albo ograniczyć liczbę metryk, które Prometheus zbiera z aplikacji, aby ograniczyć je tylko do odpowiednich.
Możesz podnieść swoją wiedzę na takie tematy, robiąc kursy przetwarzania w chmurze na platformach takich jak upGrad, Udemy, Coursera itp., ponieważ to narzędzie do monitorowania można wdrożyć w chmurze. Zwłaszcza w przypadku upGrad kursy są zaprojektowane przez jedną z renomowanych instytucji naszego kraju IIIT-B. To da ci praktyczne doświadczenie i szerszy aspekt wiedzy.
Sprawdź: Kubernetes vs. Docker: podstawowe różnice, które powinieneś wiedzieć
Wniosek
Kubernetes upraszcza wdrażanie, skalowanie i zarządzanie konteneryzowanymi aplikacjami i mikrousługami. Pomaga to w utrzymaniu administracji, jednak aby rozpoznać i rozwiązać ukryte problemy, takie jak powolne wykonywanie, potrzebna jest zdolność do gromadzenia i wyobrażania sobie od góry do dołu aplikacji i informacji o wykonywaniu ponad swoim stanem.
Brak zbliżania się do ciągłych danych wraz z istotnymi informacjami sprawia, że prawie trudno jest odpowiadać pomiarom stanu, dzięki czemu Ty również możesz szybciej rozwiązywać problemy.
Jeśli chcesz nauczyć się i opanować Kubernetes, DevOps i nie tylko, sprawdź IIIT-B i upGrad's PG Diploma in Full Stack Software Development Program.