
Surveillance de Kubernetes avec Prometheus [avec cas d'utilisation et surveillance]
Publié: 2020-09-23Table des matières
Où et pourquoi Prometheus est-il utilisé ?
Prometheus Kubernetes est un outil de surveillance qui peut être déployé sur des clusters AWS, Azure ou GCloud Kubernetes. Il est considéré comme un outil essentiel dans les infrastructures modernes. Le DevOps moderne devient de plus en plus complexe à gérer manuellement et nécessite donc plus d'automatisation, de sorte que vous avez généralement plusieurs serveurs qui exécutent des applications conteneurisées.
Des centaines de processus différents s'exécutent sur cette infrastructure où toutes les entités sont interconnectées. Il est donc très difficile de maintenir une telle configuration pour qu'elle fonctionne de manière fluide et sans interruption des applications. Imaginez avoir une infrastructure aussi compliquée avec des charges de serveurs répartis sur de nombreux emplacements, et vous n'avez aucune idée de ce qui se passe au niveau du matériel ou au niveau de l'application comme les erreurs, la réponse et la latence.
Le matériel en panne ou surchargé peut manquer de ressources dans une infrastructure aussi complexe, mais plus de choses peuvent mal tourner lorsque vous avez déployé des tonnes de services et d'applications. N'importe lequel d'entre eux peut planter et provoquer l'échec d'autres services, avoir tellement de pièces mobiles, et soudainement l'application devient indisponible pour les utilisateurs. Vous devez identifier rapidement ce qui n'a pas fonctionné précisément parmi ces centaines de problèmes différents, ce qui peut être difficile et prendre beaucoup de temps lors du débogage manuel du système.
Quelques cas d'utilisation pour l'utilisation de Prometheus Monitoring
Par exemple, supposons qu'un serveur spécifique manque de mémoire et lance un conteneur en cours d'exécution chargé de fournir la synchronisation de la base de données entre deux pots de base de données dans un cluster Kubernetes. Cela, à son tour, a provoqué l'échec de ces deux pots de base de données. Cette base de données a été utilisée par un service d'authentification qui a également cessé de fonctionner car la base de données n'est pas disponible.
L'application qui dépendait de ce service d'authentification ne pouvait plus authentifier les utilisateurs dans l'interface utilisateur, mais du point de vue de l'utilisateur, tout ce que vous voyez est une erreur dans l'interface utilisateur. Lorsque vous n'avez pas un aperçu de ce qui se passe à l'intérieur du cluster, vous ne voyez pas cette ligne rouge de la chaîne d'événements telle qu'elle est affichée ici ; vous voyez juste l'erreur. Alors maintenant, vous commencez à travailler en arrière à partir de là pour trouver la cause et la réparer. Mais qu'est-ce qui rendra ce processus de problème de recherche plus efficace ? Vous pouvez utiliser un outil qui surveille en permanence si les services sont en cours d'exécution et des alertes apparaissent dès qu'un service tombe en panne.
Vous savez exactement ce qui s'est passé, ou mieux encore, il identifie les problèmes avant même qu'ils ne surviennent et alerte les administrateurs système responsables de cette infrastructure pour prévenir ce problème. Par exemple, dans ce cas évoqué, il faudrait vérifier régulièrement l'état d'utilisation de la mémoire sur chaque serveur. Lorsque sur l'un des serveurs, il dépasse, par exemple, 70 % pendant plus d'une heure ou continue d'augmenter, il signale le risque que la mémoire de ce serveur soit bientôt épuisée.

Ou considérons un autre scénario dans lequel vous cessez de voir les journaux de votre application car la recherche élastique n'accepte aucun nouveau journal car le serveur manque d'espace disque ou la recherche élastique a atteint la limite de stockage qui lui était allouée. L'outil de surveillance vérifierait l'espace de stockage en continu et le comparerait à la consommation élastique de recherche d'espace de stockage. Il verra le risque et informera le mainteneur du problème de stockage possible.
Lire : Questions d'entretien sur Kubernetes

Vous pouvez indiquer à l'outil de surveillance quel est ce point critique lorsque l'alerte doit être déclenchée. Si vous avez une application critique qui peut absolument subir une perte de données de journal, vous pouvez être très strict et prendre des mesures dès que la capacité de cinquante ou soixante pour cent est atteinte. L'ajout d'espace de stockage prendra beaucoup de temps car il s'agit d'un processus bureaucratique dans votre organisation, où vous avez besoin de l'approbation d'un service informatique et de plusieurs autres personnes.
Vous souhaitez également être informé plus tôt d'un éventuel problème de stockage afin d'avoir plus de temps pour le résoudre. Ou un troisième scénario où l'application devient soudainement trop lente parce qu'un service tombe en panne et commence à envoyer des centaines de messages d'erreur en boucle sur le réseau, ce qui crée un trafic réseau élevé et ralentit les autres services pour disposer d'un outil qui détecte de tels pics dans un réseau .
Apprendre : Openshift Vs Kubernetes : Différence entre Openshift et Kubernetes
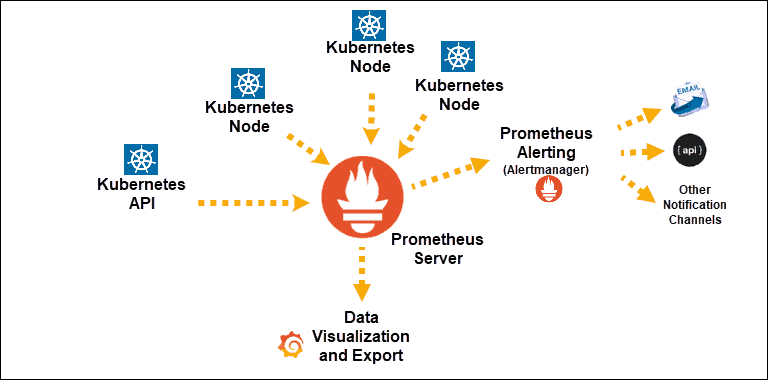
La source
Découvertes du service Kubernetes exposées à Prometheus
Composant principal : serveur Prometheus
Architecture Prométhée
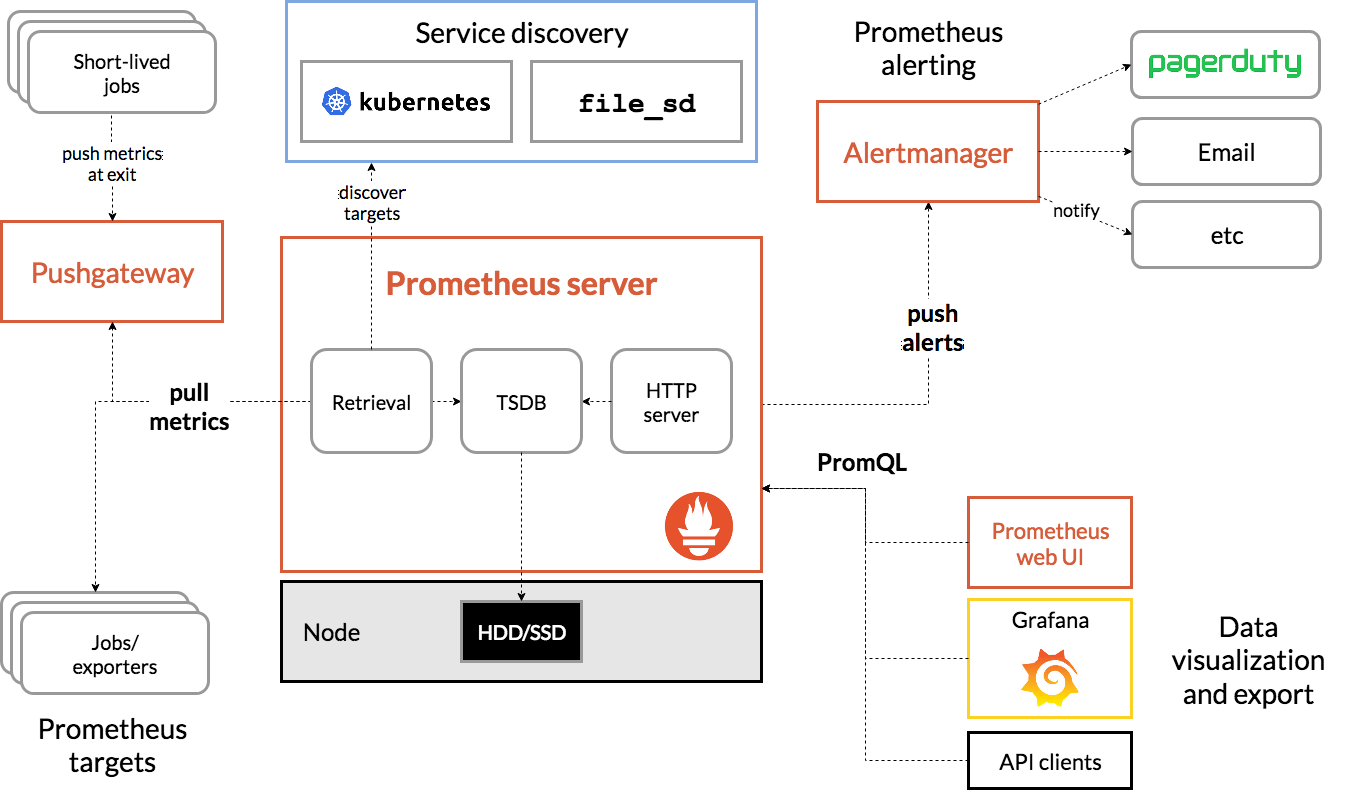
La source
L'architecture de Prometheus Kubernetes
L'une des caractéristiques importantes de Prometheus Kubernetes est qu'il est conçu pour être fiable même lorsque d'autres systèmes sont en panne. Vous pouvez diagnostiquer les problèmes et les résoudre. Par conséquent, chaque serveur Prometheus est autonome, ce qui signifie qu'il ne dépend pas du stockage réseau ou d'autres services distants.
Il est censé fonctionner lorsque d'autres parties de l'infrastructure sont en panne, et vous n'avez pas besoin de mettre en place une infrastructure étendue pour l'utiliser. Cependant, il présente également l'inconvénient que Prometheus peut être difficile à mettre à l'échelle. Ainsi, lorsque vous avez des centaines de serveurs, vous souhaiterez peut-être disposer de plusieurs serveurs Prometheus qui regroupent toutes ces données de métriques.
La configuration et la mise à l'échelle des primitives de cette manière peuvent être très difficiles en raison de ces caractéristiques. Ainsi, bien que l'utilisation d'un seul nœud soit moins complexe et que vous puissiez démarrer très facilement, cela limite le nombre de métriques que Prometheus peut surveiller. Pour contourner ce problème, vous pouvez soit augmenter la capacité du serveur Prometheus afin qu'il puisse stocker plus de données de métriques, soit limiter le nombre de métriques que Prometheus collecte à partir des applications pour les limiter à celles qui sont pertinentes.
Vous pouvez améliorer vos connaissances sur ces sujets en suivant des cours de cloud computing sur des plateformes telles que upGrad, Udemy, Coursera, etc., car cet outil de surveillance peut être déployé sur le cloud. Surtout avec upGrad, les cours sont conçus par l'une des institutions les plus réputées de notre pays IIIT-B. Cela vous donnera une expérience pratique et un aspect de connaissances plus large.
Découvrez : Kubernetes Vs. Docker : principales différences à connaître
Conclusion
Kubernetes simplifie le déploiement, la mise à l'échelle et la gestion des applications conteneurisées et des microservices. Cela aide à maintenir les administrations en marche, mais pour reconnaître et résoudre les problèmes cachés comme une exécution lente, vous avez besoin de la capacité d'accumuler et d'imaginer des informations d'application et d'exécution de base de haut en bas à partir de votre état.
Le fait de ne pas aborder les données continues, parallèlement aux informations pertinentes, rend presque difficile la correspondance avec vos mesures d'état, de sorte que vous aussi, vous pouvez résoudre les problèmes plus rapidement.
Si vous souhaitez apprendre et maîtriser Kubernetes, DevOps, etc., consultez le programme de développement logiciel Full Stack de IIIT-B & upGrad.