
Floresta aleatória vs árvore de decisão: diferença entre floresta aleatória e árvore de decisão
Publicados: 2020-12-30Avanços recentes pavimentaram o crescimento de vários algoritmos. Esses algoritmos novos e em chamas incendiaram os dados. Eles ajudam no manuseio de dados e na tomada de decisões com eles de forma eficaz. Já que o mundo está lidando com uma onda de internet. Quase tudo está na internet. Para lidar com esses dados, precisamos de algoritmos rigorosos para tomar decisões e interpretações. Agora, na presença de uma ampla lista de algoritmos, é uma tarefa pesada escolher o mais adequado.
Os algoritmos de tomada de decisão são amplamente utilizados pela maioria das organizações. Eles têm que tomar decisões triviais e grandes a cada duas horas. A partir da análise de qual material escolher para obter altas áreas brutas, uma decisão está acontecendo no backend. Os recentes avanços em python e ML empurraram a barra para lidar com dados. Assim, os dados estão presentes em grandes volumes. O limite depende da organização. Existem 2 algoritmos de decisão principais amplamente utilizados. Árvore de Decisão e Floresta Aleatória - Parece familiar, certo?
Árvores e florestas!
Vamos explorar isso com um exemplo fácil.
Suponha que você tenha que comprar um pacote de Rs. 10 biscoitos doces. Agora, você tem que decidir uma entre várias marcas de biscoitos.
Você escolhe um algoritmo de árvore de decisão. Agora, ele verificará os Rs. 10 pacotes, que é doce. Ele escolherá provavelmente os biscoitos mais vendidos. Você vai decidir ir para Rs. 10 biscoitos de chocolate. Vocês estão felizes!

Mas seu amigo usou o algoritmo de floresta aleatória. Agora, ele tomou várias decisões. Além disso, escolhendo a decisão da maioria. Ele escolhe entre vários sabores de morango, baunilha, mirtilo e laranja. Ele verifica se um determinado Rs. 10 pacotes serviram 3 unidades a mais que o original. Foi servido em chocolate de baunilha. Ele comprou aquele biscoito de chocolate com baunilha. Ele é o mais feliz, enquanto você se arrepende de sua decisão.
Participe do Curso Online de Aprendizado de Máquina das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
Índice
Qual é a diferença entre a Árvore de Decisão e a Random Forest?
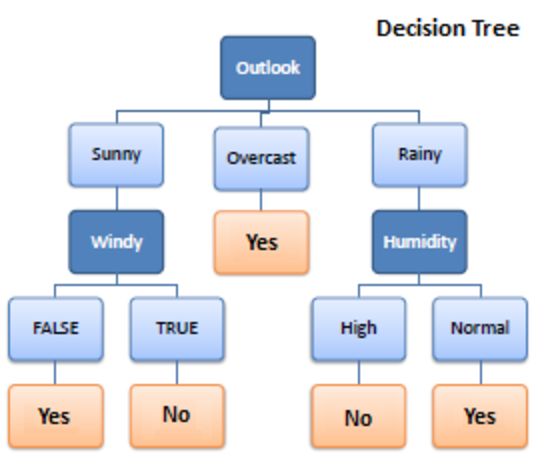
1. Árvore de Decisão
Fonte
A Árvore de Decisão é um algoritmo de aprendizado supervisionado usado em aprendizado de máquina. Ele operou em ambos os algoritmos de classificação e regressão. Como o nome sugere, é como uma árvore com nós. As ramificações dependem do número de critérios. Ele divide os dados em ramificações como essas até atingir uma unidade de limite. Uma árvore de decisão tem nós raiz, nós filhos e nós folha.
A recursão é usada para percorrer os nós. Você não precisa de nenhum outro algoritmo. Ele lida com dados com precisão e funciona melhor para um padrão linear. Ele lida com grandes dados facilmente e leva menos tempo.
Como funciona?
1. Divisão
Os dados, quando fornecidos à árvore de decisão, são divididos em várias categorias em ramos.
Deve ler: Classificador Naive Bayes: Prós e Contras, Aplicações e Tipos Explicados
2. Poda
A poda é também a trituração desses ramos. Funciona como uma classificação para subsidiar melhor os dados. Tipo, da mesma forma que dizemos poda de partes em excesso, funciona da mesma forma. O nó folha é atingido e a poda termina. É uma parte muito importante das árvores de decisão.
3. Seleção de árvores
Agora, você precisa escolher a melhor árvore que pode trabalhar com seus dados sem problemas.
Aqui estão os fatores que precisam ser considerados:
4. Entropia
Para verificar a homogeneidade das árvores, a entropia precisa ser inferida. Se a entropia for zero, ela é homogênea; senão não.
5. Ganho de conhecimento
Uma vez que a entropia é diminuída, a informação é obtida. Esta informação ajuda a dividir ainda mais os ramos.
- Você precisa calcular a entropia.
- Dividir os dados com base em diferentes critérios
- Escolha as melhores informações.
A profundidade da árvore é um aspecto importante. A profundidade nos informa do número de decisões que precisamos tomar antes de chegarmos a uma conclusão. Árvores de profundidade rasa têm melhor desempenho com algoritmos de árvore de decisão.
Vantagens e desvantagens da árvore de decisão
Vantagens
- Fácil
- Processo transparente
- Lidar com dados numéricos e categóricos
- Quanto maiores os dados, melhor o resultado
- Velocidade
Desvantagens
- Pode sobreajustar
- Processo de poda grande
- Otimização não garantida
- Cálculos complexos
- Deflexão alta
Checkout: modelos de aprendizado de máquina explicados

2. Floresta Aleatória
Fonte
Também é usado para aprendizado supervisionado, mas é muito poderoso. É muito utilizado. A diferença básica é que não depende de uma decisão singular. Ele reúne decisões aleatórias com base em várias decisões e toma a decisão final com base na maioria.
Ele não procura a melhor previsão. Em vez disso, faz várias previsões aleatórias. Assim, mais diversidade é anexada e a previsão se torna muito mais suave.
Você pode inferir Random Forest como uma coleção de múltiplas árvores de decisão!
Bagging é o processo de estabelecer florestas aleatórias enquanto as decisões funcionam paralelamente.
1. Embalagens
- Pegue algum conjunto de dados de treinamento
- Faça uma árvore de decisão
- Repita o processo por um período definido
- Agora tome a votação principal. O que ganha é a sua decisão de tomar.
2. Inicialização
Bootstrapping é escolher aleatoriamente amostras de dados de treinamento. Este é um procedimento aleatório.
Passo a passo
- Condições de escolha aleatória
- Calcular o nó raiz
- Dividir
- Repetir
- Você ganha uma floresta
Leia: Naive Bayes Explicado
Vantagens e Desvantagens da Random Forest
Vantagens
- Poderoso e altamente preciso
- Não há necessidade de normalizar
- Pode lidar com vários recursos ao mesmo tempo
- Executar árvores de maneiras paralelas
Desvantagens
- Eles são tendenciosos para certos recursos às vezes
- Devagar
- Não pode ser usado para métodos lineares
- Pior para dados de alta dimensão
Conclusão
As árvores de decisão são muito fáceis em comparação com a floresta aleatória. Uma árvore de decisão combina algumas decisões, enquanto uma floresta aleatória combina várias árvores de decisão. Assim, é um processo longo, mas lento.
Considerando que, uma árvore de decisão é rápida e opera facilmente em grandes conjuntos de dados, especialmente o linear. O modelo de floresta aleatória precisa de treinamento rigoroso. Quando você está tentando colocar um projeto, pode precisar de mais de um modelo. Assim, um grande número de florestas aleatórias, mais o tempo.
Depende de seus requisitos. Se você tiver menos tempo para trabalhar em um modelo, terá que escolher uma árvore de decisão. No entanto, estabilidade e previsões confiáveis estão na cesta das florestas aleatórias.
Se você tem paixão e quer aprender mais sobre inteligência artificial, pode fazer o Diploma PG do IIIT-B & upGrad em Machine Learning e Deep Learning , que oferece mais de 400 horas de aprendizado, sessões práticas, assistência no trabalho e muito mais.
Como a floresta aleatória é diferente de uma árvore de decisão normal?
No aprendizado de máquina, uma Árvore de Decisão é uma técnica de aprendizado supervisionado. É capaz de trabalhar com técnicas de classificação e regressão. Assemelha-se a uma árvore com nós, como o nome indica. A quantidade de critérios determina as filiais. Ele divide os dados nessas ramificações até atingir uma unidade de limite. Existem nós raiz, nós filhos e nós folha em uma árvore de decisão. A floresta aleatória também é usada para aprendizado supervisionado, embora tenha muito poder. É bastante popular. A principal diferença é que não depende de uma única decisão. Ele reúne decisões aleatórias com base em muitas decisões e, em seguida, cria uma decisão final dependendo da maioria.
Quais são as principais vantagens de usar uma floresta aleatória versus uma única árvore de decisão?
Em um mundo ideal, gostaríamos de reduzir os erros relacionados ao viés e à variância. Esta questão é bem abordada por florestas aleatórias. Uma floresta aleatória nada mais é do que uma série de árvores de decisão com suas descobertas combinadas em um único resultado final. Eles são tão poderosos por causa de sua capacidade de reduzir o overfitting sem aumentar massivamente o erro devido ao viés. Florestas aleatórias, por outro lado, são uma poderosa ferramenta de modelagem que é muito mais resiliente do que uma única árvore de decisão. Eles combinam várias árvores de decisão para reduzir o overfitting e a imprecisão relacionada ao viés e, portanto, produzem resultados utilizáveis.
O que é uma limitação das árvores de decisão?
Uma das desvantagens das árvores de decisão é que elas são muito instáveis quando comparadas a outros preditores de escolha. Uma pequena mudança nos dados pode causar uma mudança significativa na estrutura da árvore de decisão, resultando em um resultado diferente do que os consumidores esperariam em um evento típico. Além disso, quando o objetivo principal é prever o resultado de uma variável contínua, as árvores de decisão são menos úteis para fazer previsões.